class: center, middle, inverse, title-slide # <span class="title">R I: Basics</span> ## <span class="subtitle">Data Wrangling</span> ### <span class="author">Michael Clark</span> ### <span class="institute">m-clark.github.io <br> <span class="citation">@statsdatasci</span> <br> CSCAR, UM</span> ### <span class="date">2020-09-24</span> --- class: inverse background-image: url(https://github.com/m-clark/m-clark.github.io/raw/master/img/Rlogo.svg) --- class: inverse, middle, center ### *Data Structures* ### *Input/Output* ### *Indexing* ### *Tidyverse* --- class: inverse, center, middle # Data Structures <i class="fas fa-database fa-5x" aria-hidden="true"></i><span class="" style = "margin-right: 25px"></span> <i class="fas fa-code fa-5x" style = 'color:#1f65b7'></i> --- class: inverse, center # Data Structures <br> *Vectors* *Matrices* *Lists* *Data Frames* --- class: inverse # Data Structures: Vectors - *Character strings * ```r string = c('a', 'b', 'b', 'q', 'q', 'r') ``` - *Factors* ```r factor(string) ``` ``` [1] a b b q q r Levels: a b q r ``` How are they different? --- class: inverse # Data Structures: Vectors - *Logicals* ```r my_logic = c(TRUE, FALSE, TRUE) as.logical(1:5 > 3) ``` ``` [1] FALSE FALSE FALSE TRUE TRUE ``` ```r as.numeric(my_logic) ``` ``` [1] 1 0 1 ``` - *Numeric* and *integers* ```r x = c(1, 2.5, 3) ``` --- class: inverse # Data Structures: Vectors Another common data structure: *dates*. ```r Sys.Date() ``` ``` [1] "2020-09-30" ``` ```r x = as.Date(c(Sys.Date(), '2020-09-01')) class(x) ``` ``` [1] "Date" ``` The <span class="pack" style = "">lubridate</span> package will a lot. --- class: inverse # Data Structures: Matrices - *Matrices*: like vectors, all *elements* must be the same type! ```r x = 1:4 y = 5:8 z = 9:12 cbind(x, y, z) # column bind ``` ``` x y z [1,] 1 5 9 [2,] 2 6 10 [3,] 3 7 11 [4,] 4 8 12 ``` --- class: inverse # Data Structures: Data Frames - *Data Frame*: Mix it up! ```r my_df = data.frame(x = 1:2, y = c('a', 'b')) my_df ``` ``` x y 1 1 a 2 2 b ``` *tibbles* - Special class of data frames - Part of the <span class="pack">tidyverse</span> we will look at later ```r as_tibble(mtcars) ``` --- class: inverse # Data Structures: Lists Data frames are flexible because they are *lists*. ```r list(1, '1', my_df) ``` ``` [[1]] [1] 1 [[2]] [1] "1" [[3]] x y 1 1 a 2 2 b ``` --- class: inverse # Data Structures: Lists Most R objects you deal with are lists! - Data frames, model objects, plots, etc. How do you get at its elements? --- class: inverse # Data Structure Exercises - Exercise 1 - Create an object that is a <span class="objclass">matrix</span> and/or a <span class="objclass">data.frame</span>, and inspect its class or structure (use the <span class="func">class</span> or <span class="func">str</span> functions on the object you just created). - Exercise 2 - Create a list of 3 elements, the first of which contains character strings, the second numbers, and the third, the data.frame or matrix you just created in Exercise 1. - Thinking Exercises - How is a factor different from a character vector? - How is a data.frame the same as and different from a matrix? - How is a data.frame the same as and different from a list? --- class: inverse, center, middle # Input/Output <i class="fas fa-file-import fa-5x" ></i> <span class="" style = "margin-right: 25px"></span> <i class="fas fa-file-export fa-5x" ></i> --- class: inverse # Input/Output Primary packages: - <span class="pack" style = "">readr</span> - <span class="func" style = "">write_csv</span>, <span class="func" style = "">read_csv</span> - <span class="pack" style = "">haven</span> - other statistical packages (e.g. Stata) - base R - <span class="func" style = "">save</span>, <span class="func" style = "">save.image</span>, <span class="func" style = "">load</span> - <span class="func" style = "">readRDS</span>, <span class="func" style = "">saveRDS</span> ```r my_data = readr::read_csv('some_file.csv') load('my_saved_R_objects.RData') ``` --- class: inverse # Input/Output Exercises Read this csv (or any in your project data folder): https://raw.githubusercontent.com/m-clark/data-processing-and-visualization/master/data/cars.csv Use <span class="func" style = "">load</span> to load an .RData file from your data folder. --- class: inverse, center, middle # Indexing  --- class: inverse # Indexing: Slicing How do I extract: - elements of a vector - columns/rows of a matrix - subsets of a data frame - ...? ```r letters[4:6] # lower case letters a-z myMatrix[1, 2:3] # matrix[rows, columns] mydf['row1', 'b'] # data frame by name mydf[mydf$a >= 2, ] # boolean ``` --- class: inverse # Indexing: List extraction *[* : grab a slice of elements/columns *[[* : grab specific elements/columns *$* : grab specific elements/columns *@*: extract slot for S4 objects ```r my_list_or_df[2:4] my_list_or_df[['name']] my_list_or_df$name ``` --- class: inverse # Indexing: Exercises .pull-left[ Here is a matrix, a data.frame and a list. ```r mymatrix = matrix( rnorm(100), nrows = 10, ncols = 10 ) mydf = mtcars mylist = list( mat = mymatrix, thisdf = mydf ) ``` ] .pull-right[ - Exercise 1 - For the matrix, in separate operations, take a slice of rows, a selection of columns, and a single element. - Exercise 2 - For the data.frame, grab a column in 3 different ways. - Exercise 3 - For the list, grab an element by number and by name. ] --- class: tidyverse background-image: url(img/tidyverse.png) <!-- # Tidyverse --> <!-- <img src="img/tidyverse.png" style="display:block; margin: 0 auto;"> --> --- class: inverse # Tidyverse What is the *tidyverse*? ```r library(tidyverse) ``` ``` ⬢ __ _ __ . ⬡ ⬢ . / /_(_)__/ /_ ___ _____ _______ ___ / __/ / _ / // / |/ / -_) __(_-</ -_) \__/_/\_,_/\_, /|___/\__/_/ /___/\__/ ⬢ . /___/ ⬡ . ⬢ ``` ``` ── Attaching packages ────────────── tidyverse 1.3.0 ── ✓ ggplot2 3.3.2 ✓ purrr 0.3.4 ✓ tibble 3.0.3 ✓ dplyr 1.0.2 ✓ tidyr 1.1.2 ✓ stringr 1.4.0 ✓ readr 1.3.1 ✓ forcats 0.5.0 ``` --- class: inverse # Tidyverse: Packages - <span class="pack" style = "">ggplot2</span>: data visualization - <span class="pack" style = "">tibble</span>: a re-imagining of data frames - <span class="pack" style = "">tidyr</span>: data tidying - <span class="pack" style = "">readr</span>: data import - <span class="pack" style = "">purrr</span>: functional programming - <span class="pack" style = "">dplyr</span>: data manipulation - <span class="pack" style = "">stringr</span>: string processing - <span class="pack" style = "">forcats</span>: easier factors --- class: inverse # Tidyverse: Tidiness What is *tidy data*? - Arranged in a way that makes processing, analysis, and visualization simpler. In a tidy data set: - Each variable must have its own column. - Each observation must have its own row. - Each value must have its own cell. - In theory... --- class: inverse # Tidyverse: dplyr The workhorse package. It has three main goals: - Make the most important data manipulation tasks *easier*. - Do them *faster*. - Use the same interface to work with data frames, data tables or a database. --- class: inverse # Tidyverse: dplyr Some key operations include: - <span class="func">select</span>: grab columns - select helpers: <span class="func">one\_of</span>, <span class="func">starts\_with</span>, <span class="func">num_range</span> etc. - <span class="func">filter</span>/<span class="func">slice</span>: grab rows - <span class="func">group_by</span>: grouped operations - <span class="func">mutate</span>/<span class="func">transmute</span>: create new variables - <span class="func">summarize</span>: summarize/aggregate --- class: inverse # Tidyverse: Piping The pipe: <div style = "text-align:center"> <h1><span class="" style = "color: #ECD078FF; font-size: 2em; vertical-align: top;">%>%</span> </div> What goes before is provided as the first argument to the subsequent function. ```r mydata %>% summary() ``` --- class: inverse # Tidyverse: Example ```r ## load('data/bball.RData') glimpse(bball[,1:5]) ``` ``` Rows: 734 Columns: 5 $ Rk <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "16", "16", "17", "18", "19", "20", "Rk", "21", "22", "23", "23", "23", "24", "25", "26", "27", "28", "28", "28", "… $ Player <chr> "Álex Abrines", "Quincy Acy", "Jaylen Adams", "Steven Adams", "Bam Adebayo", "Deng Adel", "DeVaughn Akoon-Purcell", "LaMarcus Aldridge", "Rawle Alkins", "Grayson Allen", "Jarrett Allen", "Kadeem Allen",… $ Pos <chr> "SG", "PF", "PG", "C", "C", "SF", "SG", "C", "SG", "SG", "C", "SG", "PF", "SF", "SF", "PF", "PF", "PF", "C", "PF", "PF", "PF", "Pos", "SF", "PG", "SF", "SF", "SF", "PG", "C", "SG", "PF", "SG", "SG", "SG… $ Age <chr> "25", "28", "22", "25", "21", "21", "25", "33", "21", "23", "20", "26", "28", "25", "25", "30", "30", "30", "20", "24", "21", "34", "Age", "21", "24", "33", "33", "33", "31", "20", "23", "19", "25", "25… $ Tm <chr> "OKC", "PHO", "ATL", "OKC", "MIA", "CLE", "DEN", "SAS", "CHI", "UTA", "BRK", "NYK", "POR", "ATL", "MEM", "TOT", "PHO", "MIA", "IND", "MIL", "DAL", "HOU", "Tm", "TOR", "CHI", "TOT", "PHO", "WAS", "ORL", … ``` --- class: inverse # Tidyverse: Selecting columns ```r bball %>% select(Player, Tm, Pos) %>% head() ``` ``` # A tibble: 6 x 3 Player Tm Pos <chr> <chr> <chr> 1 Álex Abrines OKC SG 2 Quincy Acy PHO PF 3 Jaylen Adams ATL PG 4 Steven Adams OKC C 5 Bam Adebayo MIA C 6 Deng Adel CLE SF ``` Use the *-* in front of the name to drop. --- class: inverse # Tidyverse: Selecting columns Select helpers: - <span class="func">starts_with</span>: starts with a prefix - <span class="func">ends_with</span>: ends with a suffix - <span class="func">contains</span>: contains a literal string - <span class="func">matches</span>: matches a regular expression - <span class="func">num_range</span>: a numerical range like x01, x02, x03. - <span class="func">one_of</span>: variables in character vector. - <span class="func">everything</span>: all variables. ```r bball %>% select(starts_with('p'), contains('3')) ``` --- class: inverse # Tidyverse: Filtering rows Filtering requires input that can be converted to a logical vector. ```r bball = bball %>% filter(Rk != "Rk") ``` ```r bball %>% filter(Age > 35, Pos == "SF" | Pos == "PF") %>% distinct(Player, Pos, Age) ``` ``` # A tibble: 3 x 3 Player Pos Age <chr> <chr> <chr> 1 Vince Carter PF 42 2 Kyle Korver PF 37 3 Dirk Nowitzki PF 40 ``` --- class: inverse Everything's a character string! ```r glimpse(bball, width = 50) ``` ``` Rows: 708 Columns: 30 $ Rk <chr> "1", "2", "3", "4", "5", "6", "7… $ Player <chr> "Álex Abrines", "Quincy Acy", "J… $ Pos <chr> "SG", "PF", "PG", "C", "C", "SF"… $ Age <chr> "25", "28", "22", "25", "21", "2… $ Tm <chr> "OKC", "PHO", "ATL", "OKC", "MIA… $ G <chr> "31", "10", "34", "80", "82", "1… $ GS <chr> "2", "0", "1", "80", "28", "3", … $ MP <chr> "588", "123", "428", "2669", "19… $ FG <chr> "56", "4", "38", "481", "280", "… $ FGA <chr> "157", "18", "110", "809", "486"… $ FG. <chr> ".357", ".222", ".345", ".595", … $ X3P <chr> "41", "2", "25", "0", "3", "6", … $ X3PA <chr> "127", "15", "74", "2", "15", "2… $ X3P. <chr> ".323", ".133", ".338", ".000", … $ X2P <chr> "15", "2", "13", "481", "277", "… $ X2PA <chr> "30", "3", "36", "807", "471", "… $ X2P. <chr> ".500", ".667", ".361", ".596", … $ eFG. <chr> ".487", ".278", ".459", ".595", … $ FT <chr> "12", "7", "7", "146", "166", "4… $ FTA <chr> "13", "10", "9", "292", "226", "… $ FT. <chr> ".923", ".700", ".778", ".500", … $ ORB <chr> "5", "3", "11", "391", "165", "3… $ DRB <chr> "43", "22", "49", "369", "432", … $ TRB <chr> "48", "25", "60", "760", "597", … $ AST <chr> "20", "8", "65", "124", "184", "… $ STL <chr> "17", "1", "14", "117", "71", "1… $ BLK <chr> "6", "4", "5", "76", "65", "4", … $ TOV <chr> "14", "4", "28", "135", "121", "… $ PF <chr> "53", "24", "45", "204", "203", … $ PTS <chr> "165", "17", "108", "1108", "729… ``` --- class: inverse # Tidyverse: Generating New Data ```r bball = bball %>% mutate(across(c(-Player, -Pos, -Tm), as.numeric)) ``` ```r bball = bball %>% mutate( trueShooting = PTS / (2 * (FGA + (.44 * FTA))), effectiveFG = (FG + (.5 * X3P)) / FGA, shootingDif = trueShooting - FG. ) bball %>% select(Player, trueShooting:shootingDif) ``` ``` # A tibble: 708 x 4 Player trueShooting effectiveFG shootingDif <chr> <dbl> <dbl> <dbl> 1 Álex Abrines 0.507 0.487 0.150 2 Quincy Acy 0.379 0.278 0.157 3 Jaylen Adams 0.474 0.459 0.129 4 Steven Adams 0.591 0.595 -0.00405 5 Bam Adebayo 0.623 0.579 0.0466 6 Deng Adel 0.424 0.389 0.118 7 DeVaughn Akoon-Purcell 0.322 0.3 0.0217 8 LaMarcus Aldridge 0.576 0.522 0.0566 9 Rawle Alkins 0.418 0.372 0.0848 10 Grayson Allen 0.516 0.466 0.140 # … with 698 more rows ``` --- class: inverse # Tidyverse: Grouping & Summarizing Another very common task is to look at group-based statistics Primary functions: - <span class='func'>group_by</span> - <span class="func">summarize</span> --- class: inverse # Tidyverse: Grouping & Summarizing ```r bball %>% * group_by(Pos) %>% summarize( `Mean FG%` = mean(FG., na.rm = TRUE), `Mean True Shooting` = mean(trueShooting, na.rm = TRUE) ) ``` ``` # A tibble: 11 x 3 Pos `Mean FG%` `Mean True Shooting` <chr> <dbl> <dbl> 1 C 0.522 0.572 2 C-PF 0.407 0.530 3 PF 0.442 0.536 4 PF-C 0.356 0.492 5 PF-SF 0.419 0.544 6 PG 0.409 0.512 7 SF 0.425 0.528 8 SF-SG 0.431 0.558 9 SG 0.407 0.517 10 SG-PF 0.416 0.582 11 SG-SF 0.38 0.466 ``` ```r bball %>% mutate( Pos = case_when( Pos == 'PG-SG' ~ 'PG', Pos == 'C-PF' ~ 'C', Pos == 'SF-SG' ~ 'SF', Pos == 'PF-C' | Pos == 'PF-SF' ~ 'PF', Pos == 'SG-PF' | Pos == 'SG-SF' ~ 'SG', TRUE ~ Pos )) %>% nest_by(Pos) %>% mutate(FgFt_Corr = list(cor(data$FG., data$FT., use = 'complete'))) %>% unnest(c(Pos, FgFt_Corr)) ``` --- class: inverse # Tidyverse: Renaming Columns Standard approach. ```r data %>% rename(new_name = old_name, new_name2 = old_name2) ``` More complex. ```r bball %>% rename_with( str_replace, # function contains('.'), # columns pattern = '\\.', # function arguments replacement = '%' ) %>% rename_with(str_remove, starts_with('X'), pattern = 'X') %>% colnames() ``` --- class: inverse # Tidyverse: Merging <span class="func">inner_join</span>: return all rows from x where there are matching values in y, and all columns from x and y. <span class="func">left_join</span>: return all rows from x, and all columns from x and y. <span class="func">right_join</span>: return all rows from y, and all columns from x and y. --- class: inverse # Tidyverse: Merging <span class="func">semi_join</span>: return all rows from x where there are matching values in y, keeping just columns from x. <span class="func">anti_join</span>: return all rows from x where there are not matching values in y, keeping just columns from x. <span class="func">full_join</span>: return all rows and all columns from both x and y. --- class: inverse # Tidyverse: Merging ```r band_members ``` ``` # A tibble: 2 x 2 Name Band <chr> <chr> 1 Seth Com Truise 2 Francis Pixies ``` ```r band_instruments ``` ``` # A tibble: 3 x 2 Name Instrument <chr> <chr> 1 Francis Guitar 2 Bubba Guitar 3 Seth Synthesizer ``` --- class: inverse # Tidyverse: Merging ```r left_join(band_members, band_instruments) ``` ``` # A tibble: 2 x 3 Name Band Instrument <chr> <chr> <chr> 1 Seth Com Truise Synthesizer 2 Francis Pixies Guitar ``` ```r full_join(band_members, band_instruments) ``` ``` # A tibble: 3 x 3 Name Band Instrument <chr> <chr> <chr> 1 Seth Com Truise Synthesizer 2 Francis Pixies Guitar 3 Bubba <NA> Guitar ``` --- class: inverse # Tidyverse: Pivoting Pivoting involves reshaping the data. <span class="func">pivot_longer</span>: convert data from a wider format to longer one <span class="func">pivot_wider</span>: convert data from a longer format to wider one <!-- 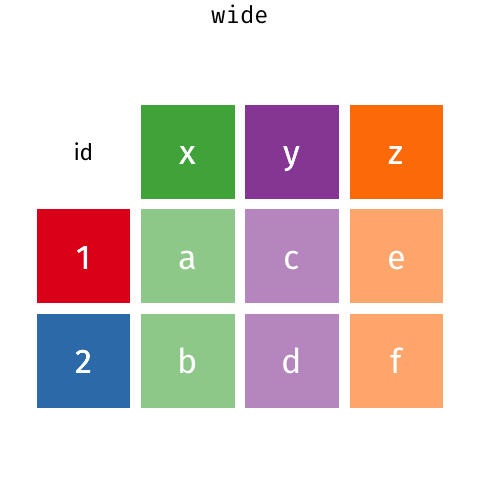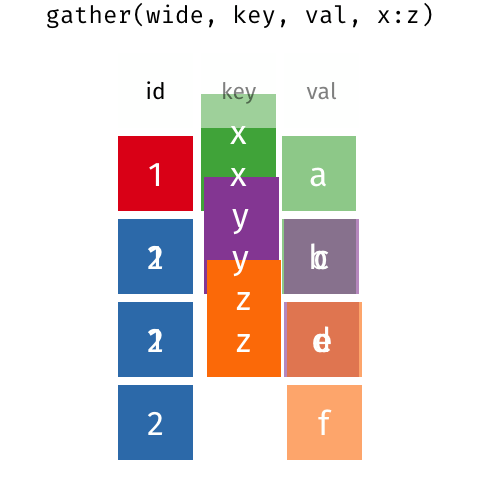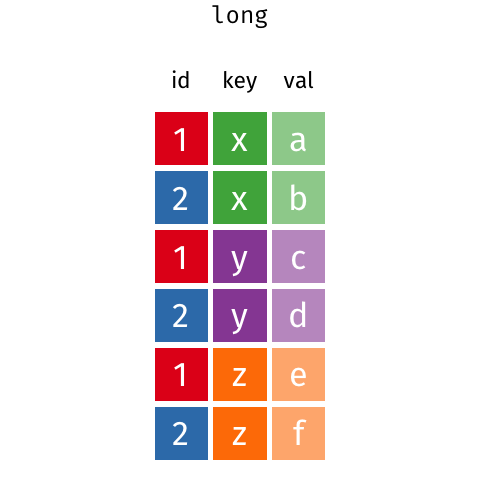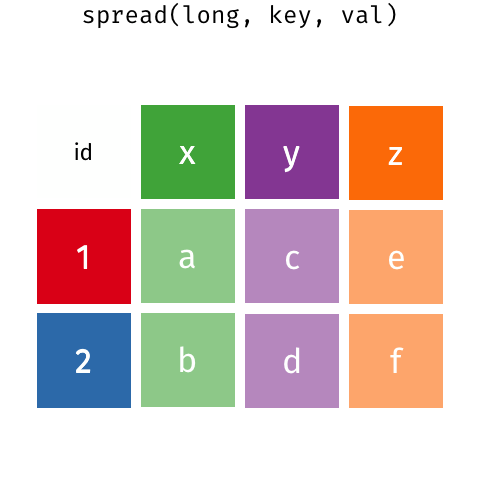{width:30%} --> <img src="img/tidyr-spread-gather.gif" style="display:block; margin: 0 auto; width:30%;"> --- class: inverse # Tidyverse: Pivoting ```r library(tidyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) head(stocks) ``` ``` time X Y Z 1 2009-01-01 2.2717401 0.8996038 4.0738061 2 2009-01-02 0.0708918 0.8776203 0.8981631 3 2009-01-03 -0.4524709 -3.9142764 -8.9257966 4 2009-01-04 -1.1678554 0.3156956 7.7532890 5 2009-01-05 0.2341694 4.2079608 -1.7337537 6 2009-01-06 -1.6258130 0.9685308 -1.3621592 ``` --- class: inverse # Tidyverse: Pivoting ```r stocks %>% pivot_longer( cols = -time, # works similar to using select() names_to = 'stock', # the name of the column that will have column names as labels values_to = 'price' # the name of the column for the values ) %>% head() ``` ``` # A tibble: 6 x 3 time stock price <date> <chr> <dbl> 1 2009-01-01 X 2.27 2 2009-01-01 Y 0.900 3 2009-01-01 Z 4.07 4 2009-01-02 X 0.0709 5 2009-01-02 Y 0.878 6 2009-01-02 Z 0.898 ``` --- class: inverse # Tidyverse: More Other packages are in the *Hadleyverse* or *RStudioverse* that stick to tidy principles. Beyond that, many modeling and visualization packages are now tidy aware. --- class: inverse # Tidyverse: Exercises ### Exercise 0 Install and load the <span class="pack">dplyr</span> <span class="pack">ggplot2movies</span> packages. Look at the help file for the `movies` data set, which contains data from IMDB. ```r install.packages('ggplot2movies') data('movies', package = 'ggplot2movies') ``` --- class: inverse # Tidyverse: Exercises ### Exercise 1a Use <span class="func">mutate</span> to create a centered version of the rating variable. A centered variable is one whose mean has been subtracted from it. The process will take the following form: ```r data %>% mutate(new_var_name = '?') ``` --- class: inverse # Tidyverse: Exercises ### Exercise 1b Use <span class="func">filter</span> to create a new data frame that has only movies from the years 2000 and beyond. Use the greater than or equal operator `>=`. ### Exercise 1c Use <span class="func">select</span> to create a new data frame that only has the `title`, `year`, `budget`, `length`, `rating` and `votes` variables. There are at least 3 ways to do this. --- class: inverse # Tidyverse: Exercises ### Exercise 1d Rename the `length` column to `length_in_min` (i.e. length in minutes). --- class: inverse # Tidyverse: Exercises ### Exercise 2 Use <span class="func">group_by</span> to group the data by year, and <span class="func">summarize</span> to create a new variable that is the average budget. The <span class="func">summarize</span> function works just like <span class="func">mutate</span> in this case. Use the <span class="func">mean</span> function to get the average, but you'll also need to use the argument `na.rm = TRUE` within it because the earliest years have no budget recorded. --- class: inverse # Tidyverse: Exercises ### Exercise 3 Use <span class="func">pivot_longer</span> to create a 'tidy' data set from the following. ```r dat = tibble(id = 1:10, x = rnorm(10), y = rnorm(10)) ``` --- class: inverse # Tidyverse: Exercises ### Exercise 4 Now put several actions together in one set of piped operations. - Filter movies released *after* 1990 - select the same variables as before but also the `mpaa`, `Action`, and `Drama` variables - group by `mpaa` *and* (your choice) `Action` *or* `Drama` - get the average rating It should spit out something like the following: --- class: inverse, other-stuff # Other Stuff .pull-left[ *base R* - still okay! *data.table* - faster, specialized data frame syntax, good for larger data *tidyfast*: - use data.table in a dplyr way *disk.frame* - for processing data too large for memory ] .pull-right[ <br> <img src="img/data-processing-timings.png" width="125%" style="display: block; margin: auto;" /> ] --- class: last-slide, inverse, center, middle 