create_data <- function(
obs_per_cluster = 10,
n_cluster = 100,
intercept = 1,
beta = .5,
sigma = 1,
sd_int = .5,
sd_slope = .25,
cor = 0,
balanced = TRUE,
seed = 888
) {
set.seed(seed)
cluster = rep(1:n_cluster, each = obs_per_cluster)
N = n_cluster * obs_per_cluster
x = rnorm(N)
varmat = matrix(c(sd_int^2, cor, cor, sd_slope^2), 2, 2)
re = mvtnorm::rmvnorm(n_cluster, sigma = varmat)
colnames(re) = c('Intercept', 'x')
y = (intercept + re[cluster, 'Intercept']) + (beta + re[cluster, 'x'])*x + rnorm(N, sd = sigma)
df = tibble(
y,
x,
cluster
)
if (balanced < 0 | balanced > 1) {
stop('Balanced should be a proportion to sample.')
} else {
df = sample_frac(df, balanced)
}
df
}NB: This post was revisited when updating the website early 2025, and some changes were required. Attempts to keep things consistent were made, but if you feel you’ve found an issue, please post it at GitHub.
Introduction
The following is a demonstration of shrinkage, sometimes called partial-pooling, as it occurs in mixed effects models. For some background, one can see the section of my document on mixed models here, and the document in general for an introduction to mixed models. Part of the inspiration of this document comes from some of the visuals seen here.
It is often the case that we have data such that observations are clustered in some way (e.g. repeated observations for units over time, students within schools, etc.). In mixed models, we obtain cluster-specific effects in addition to those for standard coefficients of our regression model. The former are called random effects, while the latter are typically referred to as fixed effects or population-average effects.
In other circumstances, we could ignore the clustering, and run a basic regression model. Unfortunately this assumes that all observations behave in the same way, i.e. that there are no cluster-specific effects, which would often be an untenable assumption. Another approach would be to run separate models for each cluster. However, aside from being problematic due to potentially small cluster sizes in common data settings, this ignores the fact that clusters are not isolated and potentially have some commonality.
Mixed models provide an alternative where we have cluster specific effects, but ‘borrow strength’ from the population-average effects. In general, this borrowing is more apparent for what would otherwise be more extreme clusters, and those that have less data. The following will demonstrate how shrinkage arises in different data situations.
Analysis
For the following we run a basic mixed model with a random intercept and random slopes for a single predictor variable. There are a number of ways to write such models, and the following does so for a single cluster \(c\) and observation \(i\). \(y\) is a function of the lone covariate \(x\), and otherwise we have a basic linear regression model. In this formulation, the random effects for a given cluster (\(re_{*c}\)) are added to each fixed effect (intercept \(b_0\) and the effect of \(x\), \(b_1\)). The random effects are multivariate normally distributed with some covariance. The per observation noise \(\sigma\) is assumed constant across observations.
\[\mu_{ic} = (b_0 + \mathrm{re}_{0c})+ (b_1+\mathrm{re}_{1c})*x_{ic}\] \[\mathrm{re}_{0}, \mathrm{re}_{1} \sim \mathcal{N}(0, \Sigma)\] \[y \sim \mathcal{N}(\mu, \sigma^2)\]
Such models are highly flexible and have many extensions, but this simple model is enough for our purposes.
Data
Default settings for data creation are as follows:
obs_per_cluster(observations per cluster) = 10n_cluster(number of clusters) = 100intercept(intercept) = 1beta(coefficient for x) = .5sigma(observation level standard deviation) = 1sd_int(standard deviation for intercept random effect)= .5sd_slope(standard deviation for x random effect)= .25cor(correlation of random effect) = 0balanced(fraction of overall sample size) = 1seed(for reproducibility) = 888
In this setting, \(x\) is a standardized variable with mean zero and standard deviation of 1. Unless a fraction is provided for balanced, the \(N\), i.e. the total sample size, is equal to n_cluster * obs_per_cluster. The following is the function that will be used to create the data, which tries to follow the model depiction above. It requires the tidyverse package to work.
The plotting functions can be found on GitHub for those interested, but won’t be shown here1.
Run the baseline model
We will use lme4 to run the analysis. We can see that the model recovers the parameters fairly well, even with the default of only 1000 observations.
df = create_data()
library(lme4)
mod = lmer(y ~ x + (x|cluster), df)
summary(mod, cor=F) Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (x | cluster)
Data: df
REML criterion at convergence: 3012.2
Scaled residuals:
Min 1Q Median 3Q Max
-2.9392 -0.6352 -0.0061 0.6156 2.8721
Random effects:
Groups Name Variance Std.Dev. Corr
cluster (Intercept) 0.29138 0.5398
x 0.05986 0.2447 0.30
Residual 0.99244 0.9962
Number of obs: 1000, groups: cluster, 100
Fixed effects:
Estimate Std. Error t value
(Intercept) 0.93647 0.06282 14.91
x 0.54405 0.04270 12.74Visualize the baseline model
Now it is time to visualize the results. We will use gganimate to bring the shrinkage into focus. We start with the estimates that would be obtained by a fixed effects, or ‘regression-by-cluster’ approach. The movement shown will be of those (default 100) cluster-specific estimates toward the mixed model estimates. On the x axis is the estimate for the intercepts, on the y axis are the estimated slopes of the x covariate. The plots for this and other settings are zoomed in based on the random effect variance inputs for this baseline model, in an attempt to make the plots more consistent and comparable across the different settings. As such, the most extreme points often will not be shown at their starting point.
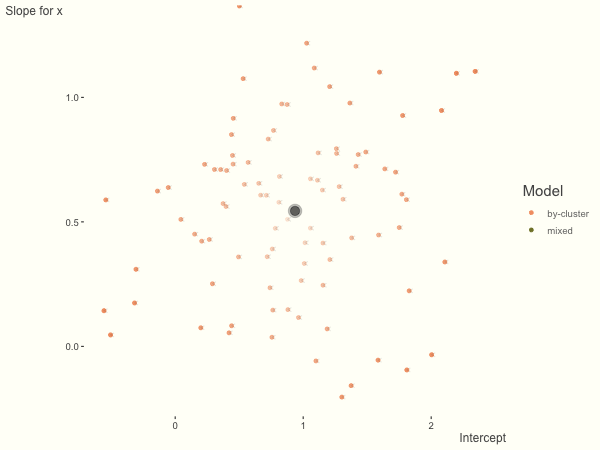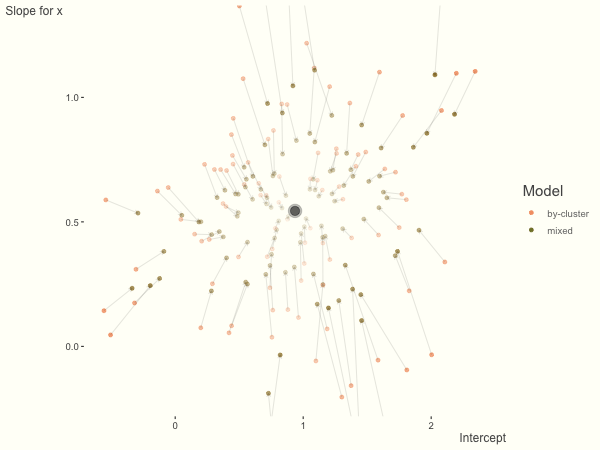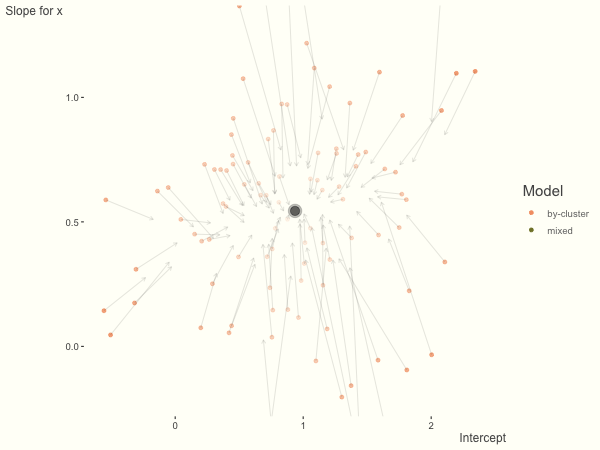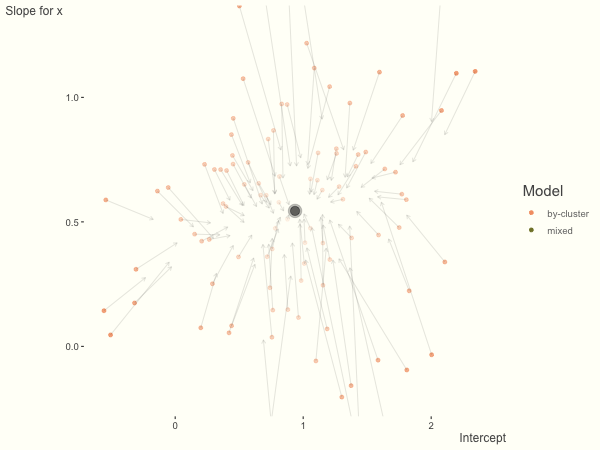

We see more clearly what the mixed model does. The general result is that cluster-specific effects (lighter color) are shrunk back toward the population-average effects (the ‘black hole’), as the imposed normal distribution for the random effects makes the extreme values less probable. Likewise, those more extreme cluster-specific effects, some of which are not displayed as they are so far from the population average, will generally have the most shrinkage imposed. In terms of prediction, it is akin to introducing bias for the cluster specific effects while lowering variance for prediction of new data, and allows us to make predictions on new categories we have not previously seen - we just assume an ‘average’ cluster effect, i.e. a random effect of 0.
Now we’ll look at what happens under different data circumstances.
More subject level variance
What happens when we add more subject level variance relative to the residual variance? The mixed model will show relatively less shrinkage, and what were previously less probable outcomes are now more probable2, and thus opting for the clusters to speak for themselves.
df = create_data(sd_int = 1, sd_slope = 1)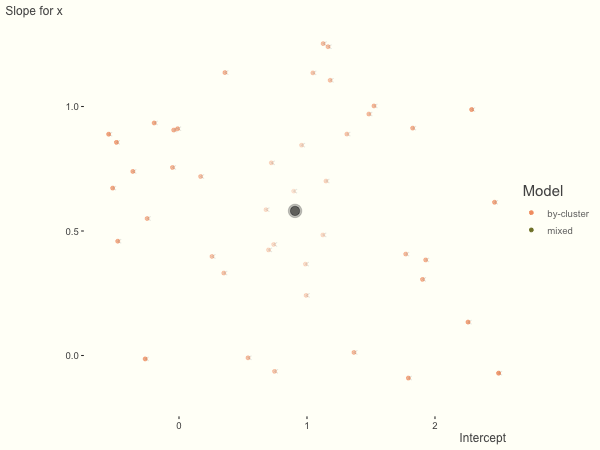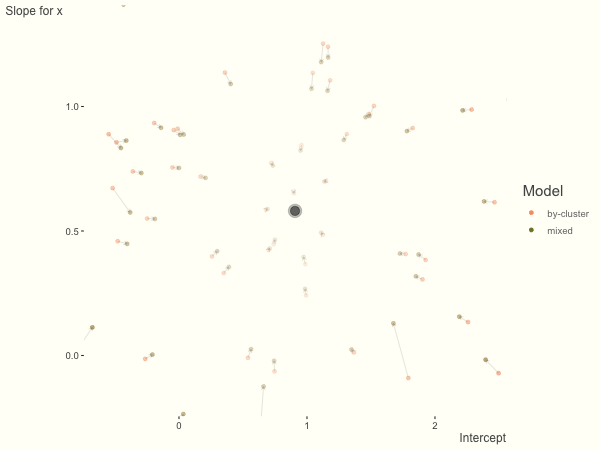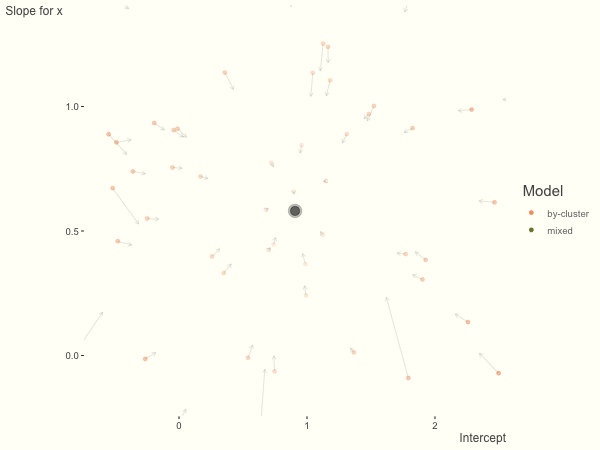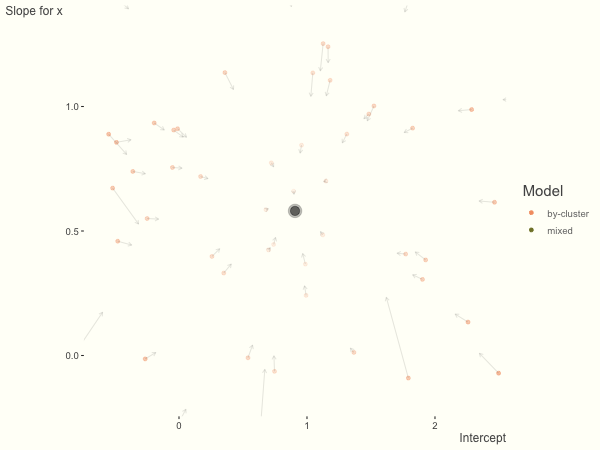

More slope variance
If we add more slope variance relative to the intercept variance, this more or less changes the orientation of the original plot. The shrinkage will be more along the x axis.
One point to keep in mind is that the slope variance is naturally on a very different scale than the intercept variance, usually many times smaller3. This can make the model more difficult to estimate. As such, scaling the covariate (e.g. to mean 0 and standard deviation of 1) is typically recommended, and at least in the linear model case, scaling the target variable can help as well.
df = create_data(sd_int = .25, sd_slope = 1)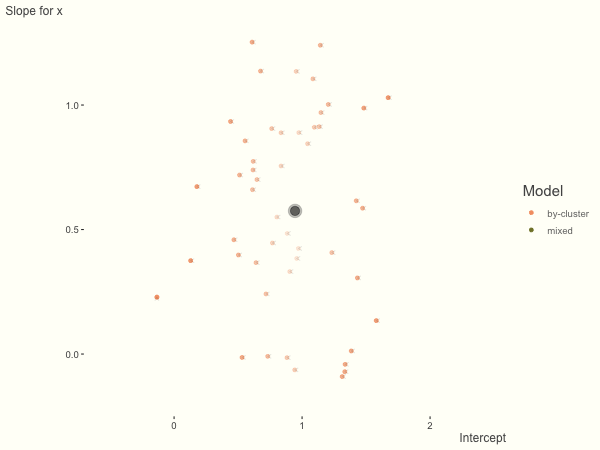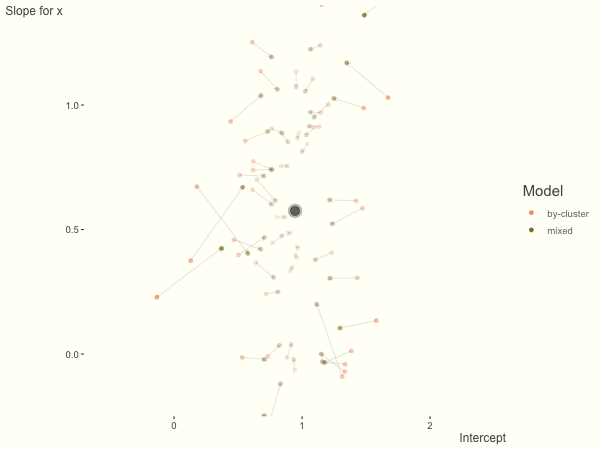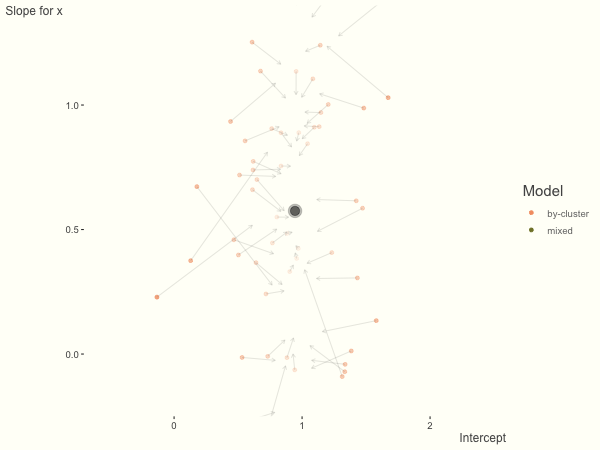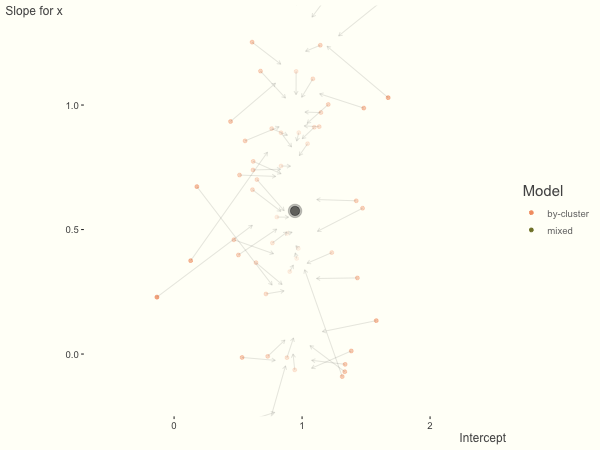

Fewer observations per cluster
If we have fewer observations within each cluster, the more likely extreme values will present in the by-cluster approach, and thus more shrinkage is applied when using a mixed model. In this setting, we have relatively less knowledge about the groups, so we would prefer to lean our cluster estimates toward the population average. In the most extreme case of having only one or two observations per cluster, we could only estimate the fixed effects as the cluster-specific effects4.
df = create_data(obs_per_cluster = 3)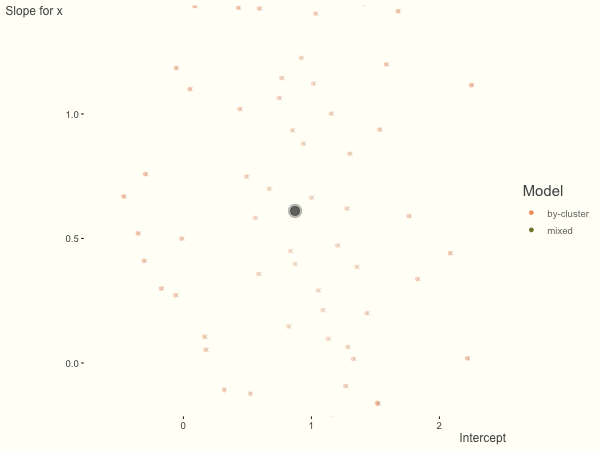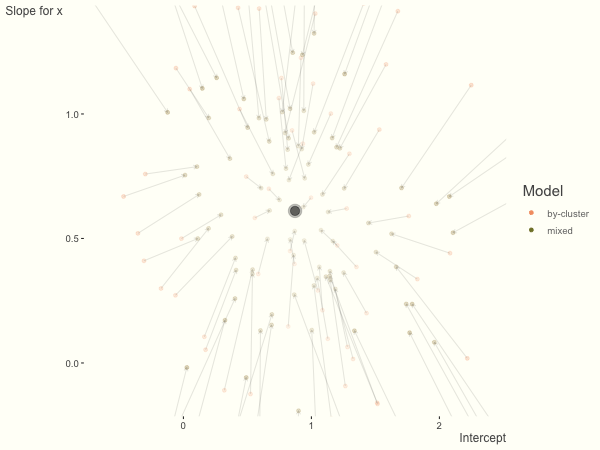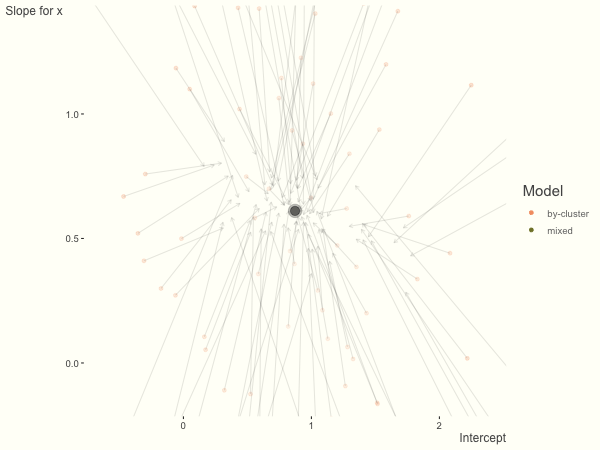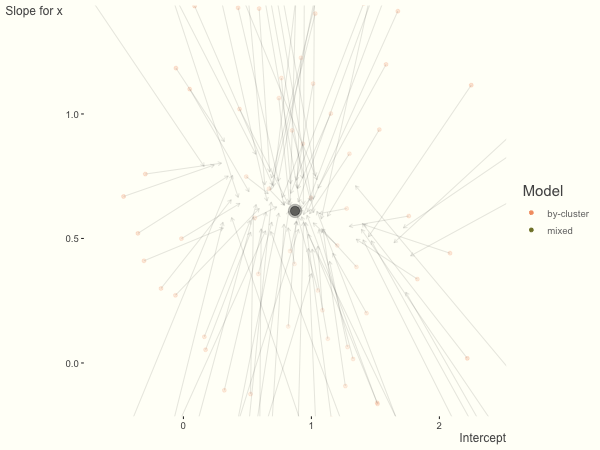

More observations per cluster
The opposite case is seen with more observations. We see that the estimates do not so easily fly to extreme values to begin with. With enough observations per cluster, you likely will see little shrinkage except with the more extreme cases.
df = create_data(obs_per_cluster = 100)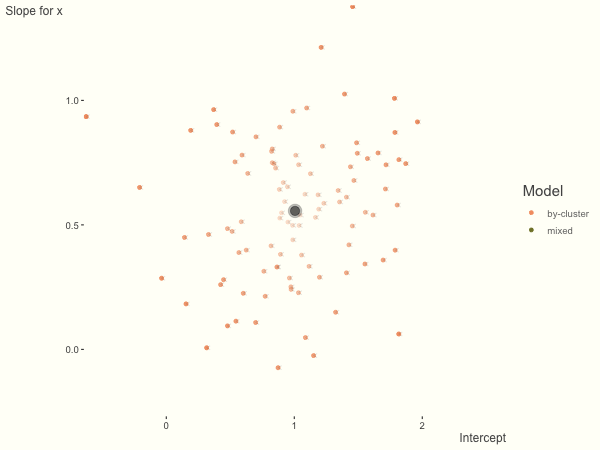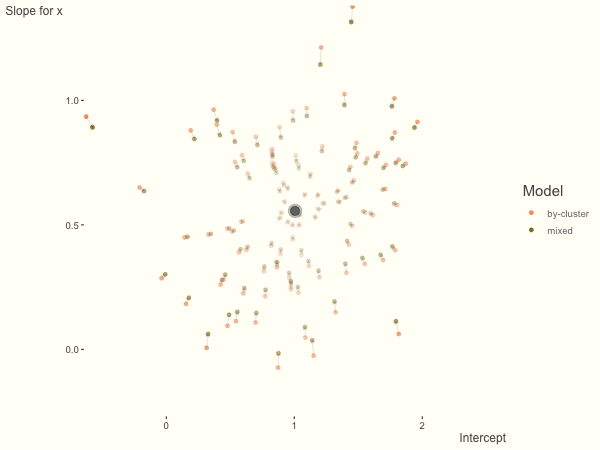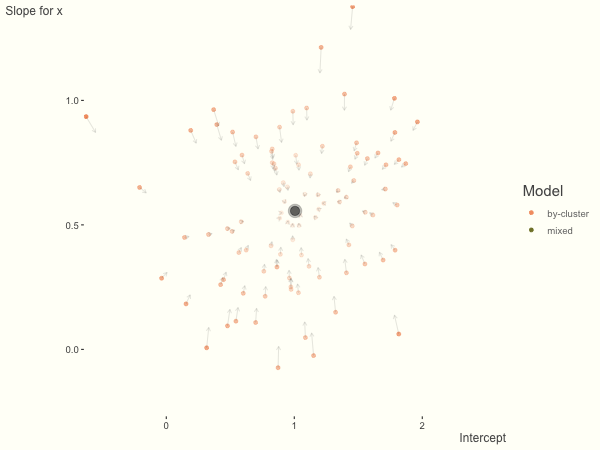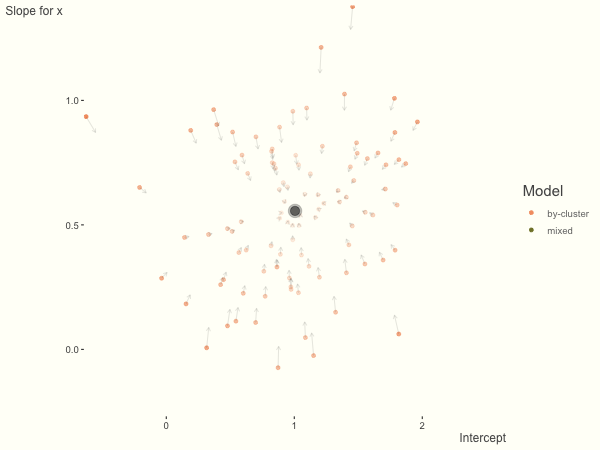

Unbalanced
With unbalanced data, we see the combination of having more vs. fewer observations per group. Those clusters with more observations will generally exhibit less shrinkage, and those with fewer observations the opposite, though this is tempered by the relative variance components. In the following, the point size represents the cluster size.
df = create_data(balanced = .5, sd_int = .5, sd_slope = .5, sigma = .25)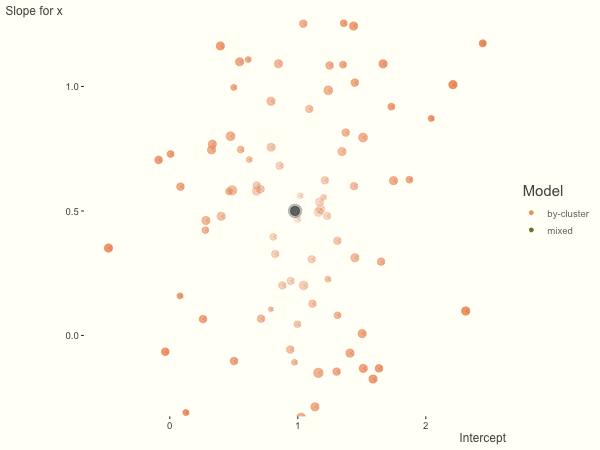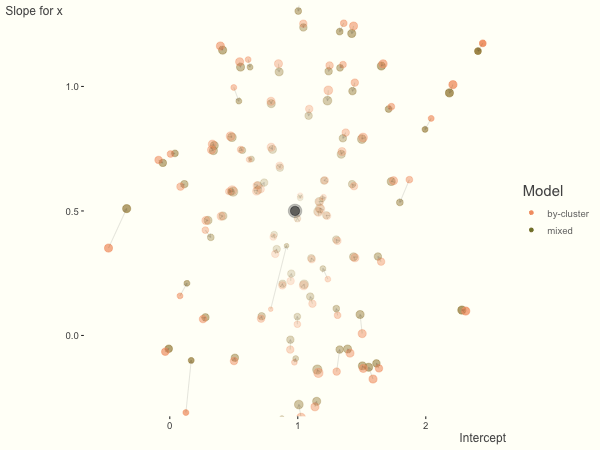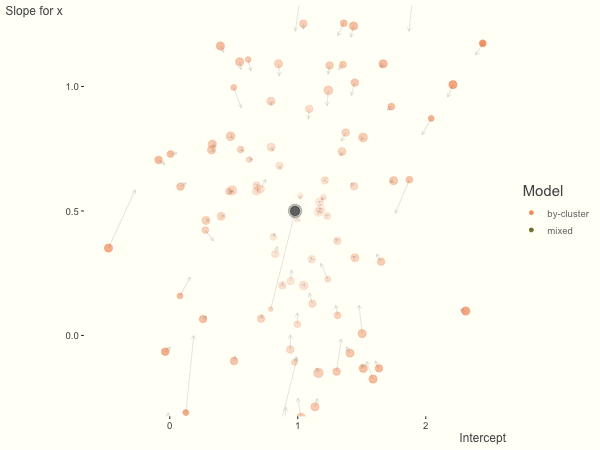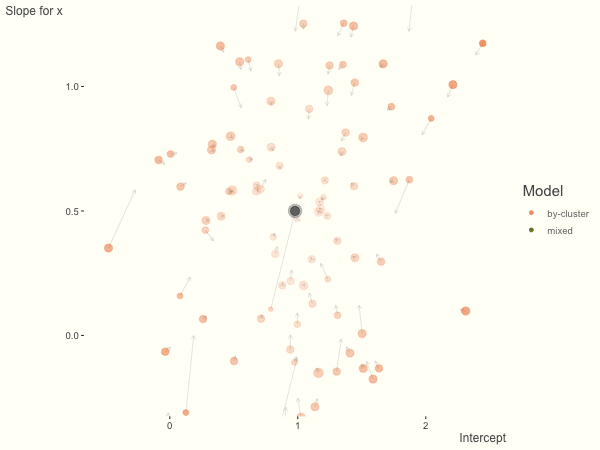

Summary
Mixed models incorporate some amount of shrinkage for cluster-specific effects. Data nuances will determine the relative amount of ‘strength borrowed’, but in general, such models provide a good way for the data to speak for itself when it should, and reflect an ‘average’ when there is little information. An additional benefit is that thinking about models in this way can be seen as a precursor to Bayesian approaches, which can allow for even more flexibility via priors, and more control over how shrinkage is added to the model.
Other demos
Ben Bolker, author lme4 on stackexchange
Tristan Mahr, Plotting partial pooling in mixed-effects models
Footnotes
They are a bit messy, as I’m sort of tricking gganimate to do this sort of plot while supplying numerous options for myself for testing and eventual use.↩︎
Think of a normal distribution with standard deviation of 1- almost all of the probability is for values falling between 3 and -3. The probability of values beyond that would be less than .001. On the other hand, if the standard deviation is 3, the probability of a value beyond \(\pm\) 3 is ~ .32, i.e. very likely.↩︎
For example, if you had income in dollars as a target and education level (in years) as a covariate, the intercept would be on the scale of income, roughly somewhere between 0 - max income (i.e. a range of potentially millions), while the effect of one year of education might only have a range of 0 to a few thousand.↩︎
In order to have a random effects model you’d need at least two observations per cluster, though this would only allow you to estimate random intercepts. Note that with unbalanced data, it is fine to have singletons or only very few observations. Singletons can only contribute to the intercept estimate however.↩︎
Reuse
Citation
BibTeX citation:
@online{clark2019,
author = {Clark, Michael and Clark, Michael},
title = {Shrinkage in {Mixed} {Effects} {Models}},
date = {2019-05-14},
url = {https://m-clark.github.io/posts/2019-05-14-shrinkage-in-mixed-models/},
langid = {en}
}
For attribution, please cite this work as:
Clark, Michael, and Michael Clark. 2019. “Shrinkage in Mixed
Effects Models.” May 14, 2019. https://m-clark.github.io/posts/2019-05-14-shrinkage-in-mixed-models/.