Web scraping
We begin with a discussion on web scraping. The term itself is ambiguous, and could potentially mean anything1, but the gist is that there is something out on the web (or some connected machine) that we want, and we’d like to use R to get it. This section won’t (at least for now) get into lower level utilities such as that provided by httr or Rcurl, though some packages will be using them under the hood. Instead, focus will be on higher-level approaches with an eye toward common tasks.
As a starting point, open a browser and go to a website of your preference. For most browsers, Ctrl+U will open up the underlying html file. If you’re on a typical webpage it will almost certainly look like a mess of html, JavaScript, XML and possibly other things. Simpler pages are more easily discernible, while more complex/secure pages are not. The take home message is that what you want is represented by something in there, and you’ll have to know something about that structure in order to get it.
Unfortunately, a lot of web design is quite poor2, which will make your job difficult. Even when the sole purpose of a site is to provide data, you can almost be sure that the simplest/most flexible path will not be taken to do so. Thankfully you can use R and possibly other tools to make the process at least somewhat less painful.
Direct data download
One thing to be aware of is that you can get data from the web that are in typical formats just as you would any file on your own machine. For example:
I wouldn’t even call this web scraping, just as you wouldn’t if you were getting a file off a network connection. However, if you’re just starting out with R, it’s important to know this is possible. In any case, do not make things more difficult than they need to be- if the file is available just grab it.
Key concepts
The web works in mysterious ways, but you don’t have to know a lot about it to use it or benefit from its data. Many people have had their own websites for years without knowing any html. For our purposes, it helps to know a little and is actually required, at least so that we know what to look for.
Common elements or tags3 of a webpage include things like div table and ul and body, and within such things our data will be found. Some common ones include:
divandspan: used when other elements are not appropriate but one still wants to define classes, ids etc.pparagraphalink (technically ‘anchor’)ulolliststabletrtdtables, table rows, table data (cell)h#i.e.h1h2etc. headersimgimages
Consider the following:
<h3> This header denotes a section of text
<img src="picture_of_cat.png"></img>
<p> This is a paragraph! </p>
<p> Here is another! This one has <a href="www.someurl.com">a link</a>! </p>As an example, if we wanted to scrape every paragraph that had the word paragraph in it, we’d need to first get all the <p> elements and work from there.
Just like in other programming languages, these parts of a webpage have their own class, e.g. <table class="wikitable sortable">, and this allows even easier access to the objects of specific interest. Take a look at the source for the Wikipedia page for towns in Michigan.

The id is another attribute, or way to note specific types of objects. Unlike classes, which might be used over and over within a page, ids are unique, and thus for web scraping, probably more useful when appropriate to the task. Also, while elements can have multiple classes, they can have only one id. Any particular element might also have different attributes that specify things like style, alignment, color, file source etc.
The sad thing is that attributes are greatly underutilized in general. For example, perhaps you found a page with several html tables of data, one for each year. It would have been simple to add an id = year to each one, enabling you to grab just the specific year(s) of interest, but it’ll be rare that you’d find a page that goes that far. Part of this could be due to the fact that much content is auto-generated via WYSIWYG editors, but these are not very professional pages if so, which might cause concern for the data given such a source. Take a look at the open.fda.gov site4:
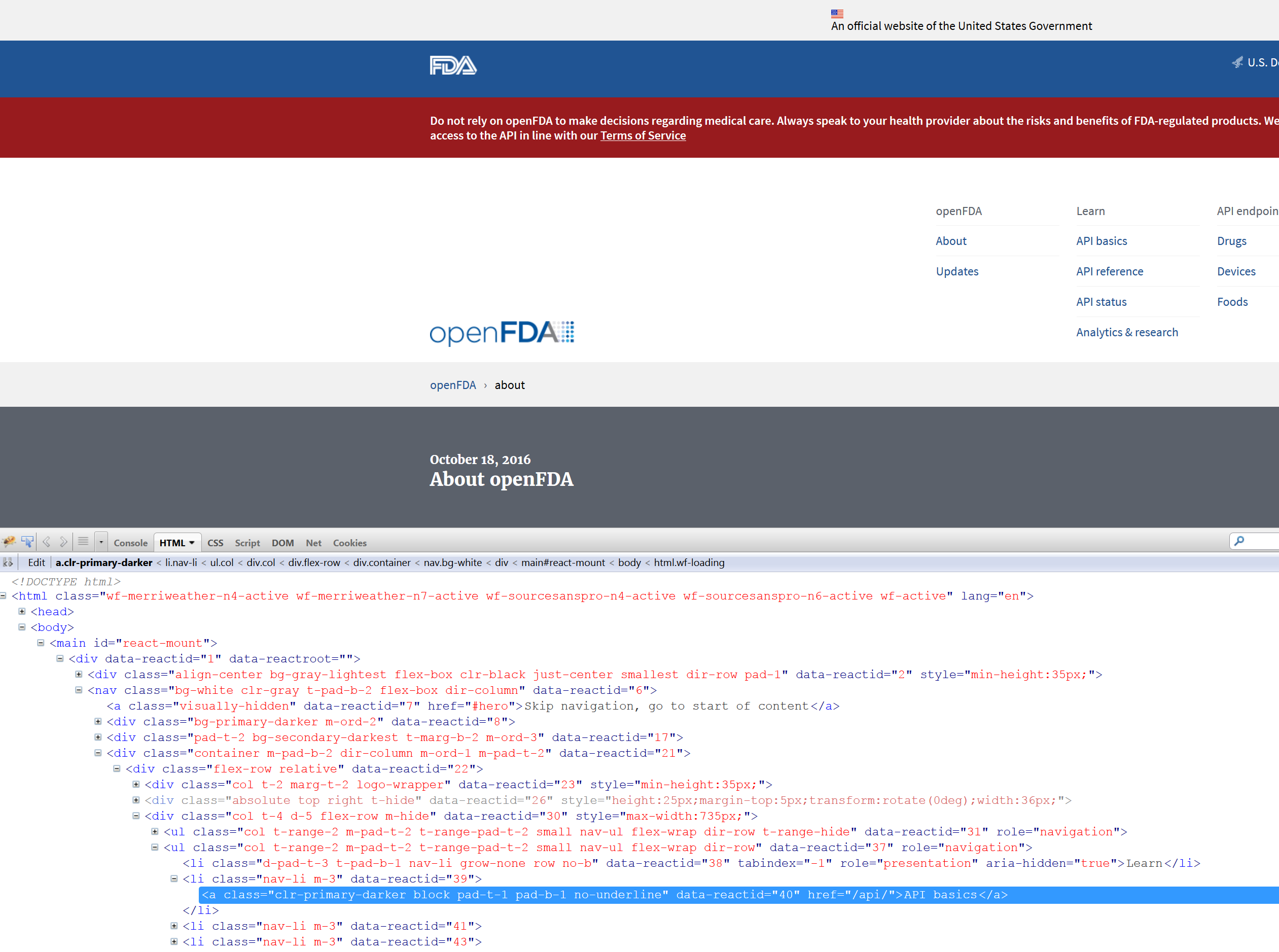
It has lots of attributes for practically every element, which would make getting stuff off the page fairly easy, if it didn’t already have an API.
In any case, you’ll at least need to know the tag within which the data or link to it may be found. Classes and ids will help to further drill down the web page content, but often won’t be available. In such a case you might have to grab, for example, all the links, and then use some regular expression to grab only the one you want. See this link for more on relations between attributes and elements.
The basic approach
To summarize the basic approach, we can outline a few steps:
- If a direct link or API is available use it5
- Inspect the page to find the relevant tags within which the content is found
- Start with a base URL
- Use the relevant R packages to parse the base page
- Extract the desired content
Examples
One of the packages that can make scraping easy is rvest, which is modeled after/inspired by the Beautiful Soup module in Python6. As the goal here is to get you quickly started, we won’t inundate you with a lot of packages yet. I recommend getting comfy with rvest and moving to others when needed.
Tables
Wikipedia
A lot of Wikipedia has pages ripe for the scraping, but it also has an API, so that we can use it as an example later as well. Between the page layout and rvest it will be very easy to get the content. So let’s do so. Back to the page of towns in Michigan. Let’s see if we can get the table of towns with their type, county, and population. First things first, we need to get the page.
page = 'https://en.wikipedia.org/wiki/List_of_cities,_villages,_and_townships_in_Michigan'
library(rvest)
towns = read_html(page)
str(towns)List of 2
$ node:<externalptr>
$ doc :<externalptr>
- attr(*, "class")= chr [1:2] "xml_document" "xml_node"{xml_document}
<html class="client-nojs" lang="en" dir="ltr">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<meta charset="UTF-8">\n<title>List of cities, villages, and townships in Michigan - Wikipedia</title>\n<script>document.documentElement ...
[2] <body class="mediawiki ltr sitedir-ltr mw-hide-empty-elt ns-0 ns-subject page-List_of_cities_villages_and_townships_in_Michigan rootpage-List_of_cities_villages_and_townships_in_Michigan skin-vector action-view">\ ...The result of read_html is an xml_document class object. For the uninitiated, XML is a markup language (Extensible Markup Language) like HTML, and which allows one to access its parts as nodes in tree7, where parents have children and grandchildren etc. It will require further parsing in order to get what we want, but it was easy enough to snag the page. Let’s look at some of the nodes.
{xml_nodeset (6)}
[1] <ul>\n<li><a href="#A">A</a></li>\n<li><a href="#B">B</a></li>\n<li><a href="#C">C</a></li>\n<li><a href="#D">D</a></li>\n<li><a href="#E">E</a></li>\n<li><a href="#F">F</a></li>\n<li><a href="#G">G</a></li>\n<li> ...
[2] <ul>\n<li><a href="#See_also">See also</a></li>\n<li><a href="#References">References</a></li>\n<li><a href="#External_links">External links</a></li>\n</ul>
[3] <ul>\n<li><a href="/wiki/Administrative_divisions_of_Michigan" title="Administrative divisions of Michigan">Administrative divisions of Michigan</a></li>\n<li><a href="/wiki/List_of_counties_in_Michigan" title="Li ...
[4] <ul>\n<li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20040908085409/http://www.viennatwp.com/News/township_government_in_michigan.htm">Township Government in Michigan</a></li>\n<li>< ...
[5] <ul>\n<li><a rel="nofollow" class="external text" href="https://web.archive.org/web/20020802223743/http://www.census.gov/geo/www/gazetteer/places2k.html">Census 2000 Gazetteer</a></li>\n<li><a rel="nofollow" class ...
[6] <ul>\n<li class="nv-view"><a href="/wiki/Template:Michigan" title="Template:Michigan"><abbr title="View this template" style=";;background:none transparent;border:none;-moz-box-shadow:none;-webkit-box-shadow:none; ...{xml_nodeset (6)}
[1] <a id="top"></a>
[2] <a class="mw-jump-link" href="#mw-head">Jump to navigation</a>
[3] <a class="mw-jump-link" href="#p-search">Jump to search</a>
[4] <a href="/wiki/Wikipedia:Citing_sources" title="Wikipedia:Citing sources">list of references</a>
[5] <a href="/wiki/Wikipedia:Citing_sources#Inline_citations" title="Wikipedia:Citing sources">inline citations</a>
[6] <a href="/wiki/Wikipedia:WikiProject_Fact_and_Reference_Check" title="Wikipedia:WikiProject Fact and Reference Check">improve</a>{xml_nodeset (5)}
[1] <table class="plainlinks metadata ambox ambox-style ambox-More_footnotes" role="presentation"><tbody><tr>\n<td class="mbox-image"><div style="width:52px"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/t ...
[2] <table class="wikitable sortable"><tbody>\n<tr>\n<th>Place</th>\n<th>Type</th>\n<th>County</th>\n<th>2010 Population</th>\n<th>2017 Estimate\n</th>\n</tr>\n<tr id="A">\n<td><a href="/wiki/Acme,_Michigan" class="mw ...
[3] <table role="presentation" class="mbox-small plainlinks sistersitebox" style="background-color:#f9f9f9;border:1px solid #aaa;color:#000"><tbody><tr>\n<td class="mbox-image"><img alt="" src="//upload.wikimedia.org/ ...
[4] <table class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody>\n<tr><th scope="col" class="navbox-title" colspan="3">\n<div class="plainlinks ...
[5] <table class="nowraplinks collapsible autocollapse navbox-inner" style="border-spacing:0;background:transparent;color:inherit"><tbody>\n<tr><th scope="col" class="navbox-title" colspan="2">\n<div class="plainlinks ...Perhaps now you are getting a sense of what we can possibly extract from this page. It turns out that what we want is a table element, and in particular, the one that is of class wikitable sortable. This will make things very easy. But what if we didn’t know what the element was? it turns out browsers come with the ability to inspect the elements of any webpage, and even change them. The following depicts what the Michigan towns looks like when using Chrome’s built-in developer tools and selecting a link.
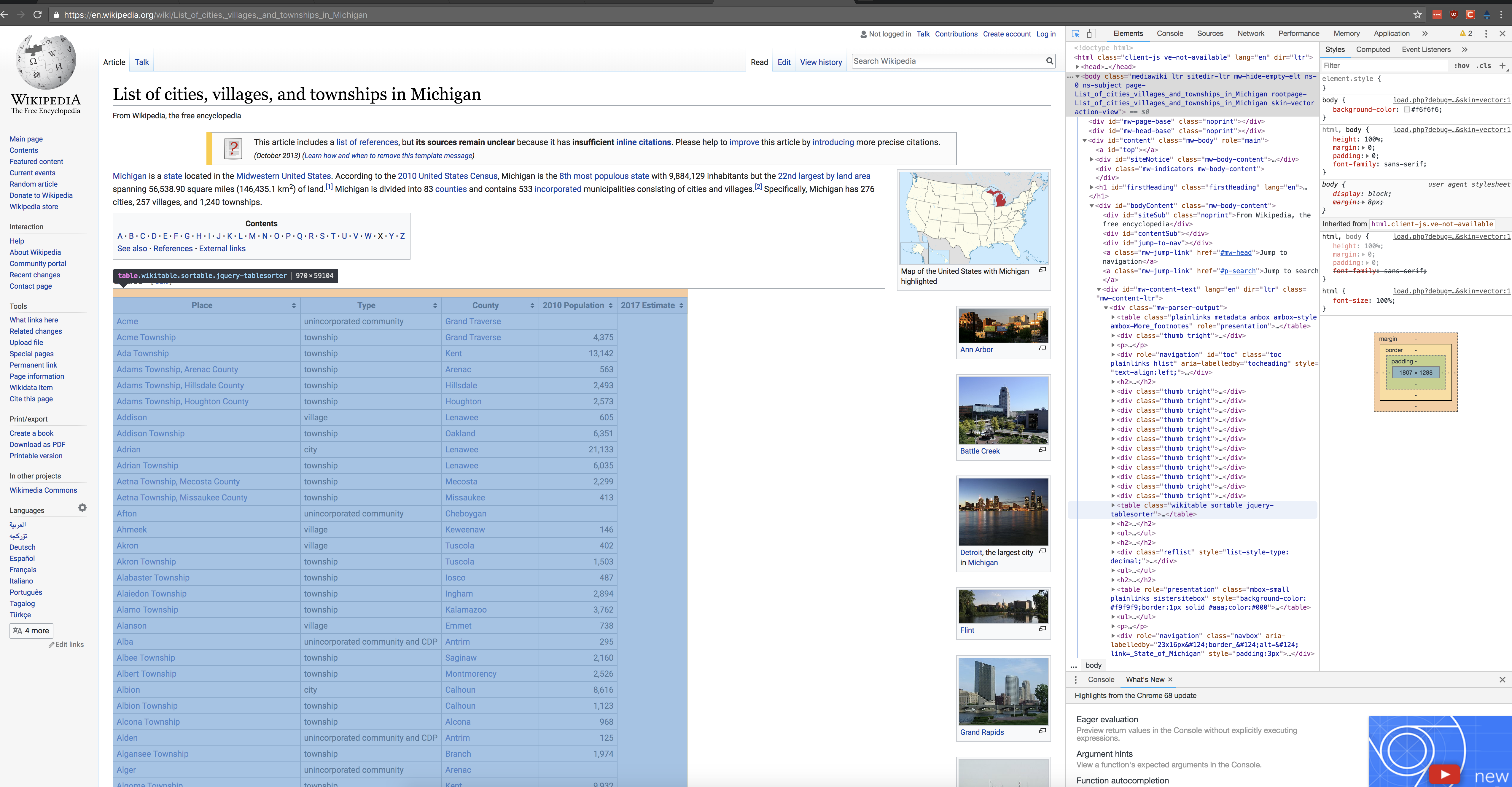
It highlights everything else in the page that is of a similar type (i.e. other links), as well as provides the css/xml info that we would need to grab that particular item.
As mentioned, we want the wikitable sortable class table, so lets grab that. The rvest package comes with the html_table function, that will grab any table and attempt to put it into a data.frame object. I only show the first couple because one of the tables comes out pretty messy at the R console.
List of 3
$ :'data.frame': 1 obs. of 2 variables:
..$ X1: logi NA
..$ X2: chr "This article includes a list of references, but its sources remain unclear because it has insufficient inline c"| __truncated__
$ :'data.frame': 2188 obs. of 5 variables:
..$ Place : chr [1:2188] "Acme" "Acme Township" "Ada Township" "Adams Township, Arenac County" ...
..$ Type : chr [1:2188] "unincorporated community" "township" "township" "township" ...
..$ County : chr [1:2188] "Grand Traverse" "Grand Traverse" "Kent" "Arenac" ...
..$ 2010 Population: chr [1:2188] "" "4,375" "13,142" "563" ...
..$ 2017 Estimate : logi [1:2188] NA NA NA NA NA NA ...
$ :'data.frame': 1 obs. of 2 variables:
..$ X1: logi NA
..$ X2: chr "Wikimedia Commons has media related to Populated places in Michigan."We know which class object we want though, so we could have used html_nodes to grab only that object and work with it.
Place Type County 2010 Population 2017 Estimate
1 Acme unincorporated community Grand Traverse NA
2 Acme Township township Grand Traverse 4,375 NA
3 Ada Township township Kent 13,142 NA
4 Adams Township, Arenac County township Arenac 563 NA
5 Adams Township, Hillsdale County township Hillsdale 2,493 NA
6 Adams Township, Houghton County township Houghton 2,573 NAHere the . in .wikitable.sortable represents the class/subclass (use # for ids). In general though, if you know it’s a table, then use html_table. When the table has no class then you’ll have to use a magic number or some other means to grab it, which may not be as robust. Of course, the class itself might change over time also.
So let’s put this all together.
library(stringr)
towns %>%
html_table(fill = TRUE) %>%
.[[2]] %>%
rename(Population = `2010 Population`) %>%
mutate(Population = strtoi(str_replace_all(Population, ',', '')),
Type = factor(str_squish(str_trim(Type))),
Type = forcats::fct_collapse(Type, unincorporated = c('unincorporated community', 'unincorporated community and CDP', 'CDP'))) %>%
ggplot(aes(x=Population, fill=Type, color=Type)) +
scale_x_log10() +
geom_density(alpha=.2) +
theme(panel.background=element_rect(fill='transparent', color=NA),
plot.background=element_rect(fill='transparent', color=NA))
I won’t go into details about the rest of the code regarding data processing, as that’s for another workshop. For now it suffices to say that it didn’t take much to go from URL to visualization.
Basketball Reference
As an additional example let’s get some data from basketball-reference.com. The following gets the totals table from the URL8. Issues include header rows after every 20th row of data, and converting all but a few columns from character to numeric.
url = "http://www.basketball-reference.com/leagues/NBA_2018_totals.html"
bball = read_html(url) %>%
html_node("#totals_stats") %>% # grab element with id 'total_stats'
html_table() %>% # the data
filter(Rk != "Rk") %>% # remove header rows
mutate_at(vars(-Player, -Pos, -Tm), as.numeric) # convert to numeric
str(bball)'data.frame': 664 obs. of 30 variables:
$ Rk : num 1 2 3 4 5 6 7 8 9 10 ...
$ Player: chr "Alex Abrines" "Quincy Acy" "Steven Adams" "Bam Adebayo" ...
$ Pos : chr "SG" "PF" "C" "C" ...
$ Age : num 24 27 24 20 32 29 32 19 25 36 ...
$ Tm : chr "OKC" "BRK" "OKC" "MIA" ...
$ G : num 75 70 76 69 53 21 75 72 18 22 ...
$ GS : num 8 8 76 19 3 0 75 31 1 0 ...
$ MP : num 1134 1359 2487 1368 682 ...
$ FG : num 115 130 448 174 65 5 687 234 6 44 ...
$ FGA : num 291 365 712 340 162 ...
$ FG% : num 0.395 0.356 0.629 0.512 0.401 0.333 0.51 0.589 0.273 0.484 ...
$ 3P : num 84 102 0 0 27 0 27 5 0 4 ...
$ 3PA : num 221 292 2 7 70 0 92 15 11 12 ...
$ 3P% : num 0.38 0.349 0 0 0.386 NA 0.293 0.333 0 0.333 ...
$ 2P : num 31 28 448 174 38 5 660 229 6 40 ...
$ 2PA : num 70 73 710 333 92 ...
$ 2P% : num 0.443 0.384 0.631 0.523 0.413 0.333 0.526 0.599 0.545 0.506 ...
$ eFG% : num 0.54 0.496 0.629 0.512 0.485 0.333 0.52 0.596 0.273 0.505 ...
$ FT : num 39 49 160 129 22 2 334 114 7 11 ...
$ FTA : num 46 60 286 179 26 6 399 147 9 21 ...
$ FT% : num 0.848 0.817 0.559 0.721 0.846 0.333 0.837 0.776 0.778 0.524 ...
$ ORB : num 26 40 384 118 4 3 246 144 4 20 ...
$ DRB : num 88 217 301 263 62 12 389 244 7 27 ...
$ TRB : num 114 257 685 381 66 15 635 388 11 47 ...
$ AST : num 28 57 88 101 30 3 152 49 12 9 ...
$ STL : num 38 33 92 32 4 2 43 28 3 11 ...
$ BLK : num 8 29 78 41 9 1 90 88 2 3 ...
$ TOV : num 25 60 128 66 21 1 111 82 9 19 ...
$ PF : num 124 149 215 138 56 11 161 147 15 49 ...
$ PTS : num 353 411 1056 477 179 ...Text
A lot of times we’ll want to grab text as opposed to tables. See the API chapter for an example, and the html_text function in the rvest package.
Images
Images are fairly easy because they are simply files with specific extensions like svg, png, gif etc. In that sense, if one knows the actual location of the image already, a function like download.files can be used to grab it directly. Other times it may not be known, and so we can use a similar approach as before to grab the file.
base_page = read_html('https://en.wikipedia.org/wiki/Main_Page')
picofday_location = base_page %>% # get the main page
html_nodes('#mp-tfp') %>% # extract the div with 'today's featured picture', i.e. tfp
html_nodes('img') %>% # extract the img
html_attr('src') # grab the source locationWith location in hand we can now download the file, and even display it in R. The following requires the grid and jpeg packages.
download.file(url=paste0('https:', picofday_location), destfile='img/picofday.jpg', mode='wb')
picofday = jpeg::readJPEG(source='img/picofday.jpg')
df = data.frame(x=rnorm(1), y=rnorm(1)) # note that any random df will suffice
qplot(data=df, geom='blank') +
annotation_custom(grid::rasterGrob(picofday)) +
theme_void()
Note that an alternative approach that might work on some websites would be to extract all the images and then the one with a relevant naming convention. This doesn’t work for the Wikipedia main page because there is nothing to identify which image is the featured picture by file name alone.
Issues
As mentioned, the ease with which you will be able to scrape a website will depend a lot on how well the page/site is put together. Many are cookie-cutter templates designed with no regard to data availability whatsoever, others are just the result of amateurs (like me!) that do not do web design for a living, and still others are just poorly designed. In addition, some websites may have security or other server back end things to consider that require much of the content to be less accessible, perhaps intentionally.
On the other hand, other sites will make it as easy as a URL pointing to a csv file, or an API that is easily maneuverable. The main thing is that you must plan ahead for encountering difficulty, and/or to be ready for heavy post-processing even when you get the bulk of what you want. The goal should be to make the process automatic such that only a fundamental site or API change will cause you to have to change your code again.
Called by various names: web harvesting, data scraping (presumptuous), etc.↩
Think about your R code, now remove the spaces, indent as irregularly as possible, do not comment anything, use reserved words for common names, don’t name important parts of your site, reject any known coding style, and use default settings. That would describe much of the typical website design I come across, and the rest is automatically generated, so possibly not even intended to be human-readable.↩
There is subtle distinction between tags versus elements, but which won’t really matter to us.↩
The openfda site was depicted using the Mozilla firebug extension.↩
APIs change so regularly that in some cases it might be easier to scrape as above, especially if the site itself changes relatively rarely and still allows direct access to the desired content.↩
I highly recommend Beautiful Soup also. Until rvest and related packages came along, I preferred using Beautiful Soup to what was available in R.↩
Think graphical models rather than spruce.↩
Technically this data can be downloaded as a supplied csv.↩