Model Exploration
As with modeling in traditional approaches, it is not enough to simply run a model and go with whatever results are returned without further inspection. One must examine the results to assess model integrity and have more confidence in the results that have been produced31.
Monitoring Convergence
There are various ways to assess whether or not the model has converged to a target distribution32, but as with more complex models in MLE, there is nothing that can tell you for sure that you’ve hit upon the true solution. As a starting point, Stan or other modeling environments will likely return repeated warnings or errors if something is egregiously wrong, or perhaps take an extraordinarily long time to complete relative to expectations, if it ever finishes at all. Assuming you’ve at least gotten past that point, there is more to be done.
Visual Inspection: Traceplot & Densities
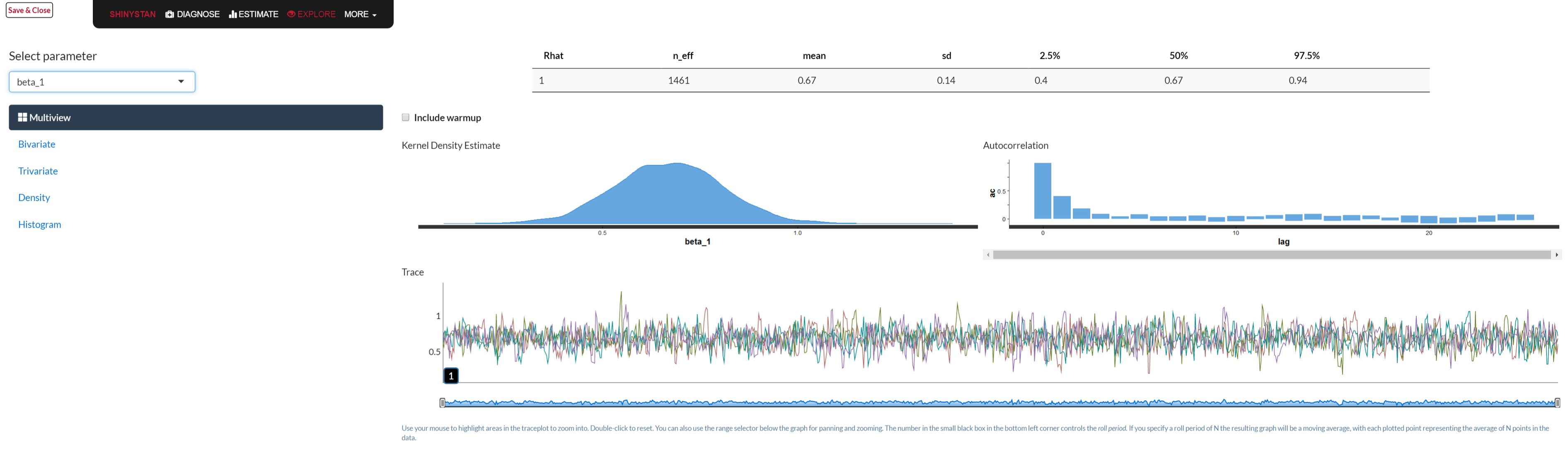
In the previous model we noted the traceplot for a single parameter, and a visual approach to monitoring convergence is certainly one good method. In general, we look for a plot that shows random scatter around a mean value, and our model results suggest that the chains mixed well and the traceplot looked satisfactory.

This above shows an example where things have gone horribly wrong. The chains never converge, nor do they mix with one another. One reason for running multiple chains is that any individual chain might converge toward one target, while another chain might converge elsewhere, and this would still be a problem. Also, you might see otherwise healthy chains get stuck on occasion over the course of the series, which might suggest more model tweaking or a change in the sampler settings is warranted.
We can examine the mixed chains and density plots of the posterior with standard functions in the rstan package displayed previously, various functions in the bayesplot package, or interactively via shinyStan package and its launch_shiny function. In the Bayesian approach, increasing amounts of data leads to a posterior distribution of the parameter vector approaching multivariate normality. The following shows a density, trace and autocorrelation plots for one of the regression coefficients using shinyStan.
Statistical Measures
To go along with visual inspection, we can examine various statistics that might help our determination of convergence or lack thereof. Gelman and Rubin’s potential scale reduction factor, \(\hat{R}\), provides an estimate of convergence based on the variance of an estimated parameter \(\theta\) between chains, and the variance within a chain. It is interpreted as the factor by which the variance in the estimate might be reduced with longer chains. We are looking for a value near 1 (and at the very least less than 1.1), and it will get there as \(N_{sim} \rightarrow \infty\). In the regression model things are looking good in this respect.
| term | estimate | rhat |
|---|---|---|
| beta[1] | 4.889 | 1.000 |
| beta[2] | 0.083 | 1.006 |
| beta[3] | -1.475 | 0.999 |
| beta[4] | 0.816 | 0.999 |
| sigma | 2.029 | 0.998 |
The coda package provides other convergence statistics based on Geweke (1992) and Heidelberger and Welch (1983). Along with those statistics, it also has plots for the \(\hat{R}\) and Geweke diagnostics.
Autocorrelation
As noted previously, each estimate in the MCMC process is serially correlated with the previous estimates by definition. Furthermore, other aspects of the data, model, and estimation settings may contribute to this. Higher serial correlation typically has the effect of requiring more samples in order to get to a stationary distribution. If inspection of the traceplots look more ‘snake-like’ than like a fat hairy caterpillar, this might suggest such a situation, and that more samples are required.
We can also look at the autocorrelation plot, in which the chain’s correlation with successive lags of the chain are plotted. The first plot is the autocorrelation plot from our model (starting at lag 1). The correlation is low to begin with and then just bounces around zero after. The next plot shows a case of high serial correlation, where the correlation with the first lag is high and the correlation persists even after longer lags. A longer chain with more thinning could help with this.


The effective number of simulation draws is provided as \(n_{\textrm{eff}}\) in the Stan output, and is similarly obtained in BUGS/JAGS. Ideally, we would desire this number to equal the number of posterior draws requested, and in the presence of essentially no autocorrelation the values would be equal. This is not a requirement though, and technically a low number of draws would still be usable. However, a notable discrepancy might suggest there are some issues with the model, or simply that longer chains could be useful. In our current model, all our effective sample sizes are at or near the total number of posterior draws.
| term | estimate | ess |
|---|---|---|
| beta[1] | 4.889 | 1142 |
| beta[2] | 0.083 | 912 |
| beta[3] | -1.475 | 910 |
| beta[4] | 0.816 | 988 |
| sigma | 2.029 | 844 |
Monte Carlo error is an estimate of the uncertainty contributed by only having a finite number of posterior draws. We’d typically want roughly less than 5% of the posterior standard deviation (reported right next to it in the Stan output), but might as well go for less than 1%. With no autocorrelation it would equal \(\sqrt{\frac{var(\theta)}{n_{\textrm{eff}}}}\)33. and \(n_{\textrm{eff}}\) would equal the number of simulation draws requested.
| mean | se_mean | |
|---|---|---|
| beta[1] | 4.891 | 0.004 |
| beta[2] | 0.083 | 0.004 |
| beta[3] | -1.473 | 0.004 |
| beta[4] | 0.819 | 0.004 |
| sigma | 2.033 | 0.003 |
Model Criticism
Checking the model for suitability is crucial to the analytical process34. Assuming initial diagnostic inspection for convergence has proven satisfactory, we must then see if the model makes sense in its own right. This can be a straightforward process in many respects, and with Bayesian analysis one has a much richer environment in which to do so compared to traditional methods.
Sensitivity Analysis
Sensitivity analysis entails checks on our model settings to see if changes in them, perhaps even slight ones, result in changes in posterior inferences. This may take the form of comparing models with plausible but different priors, different sampling distributions, or differences in other aspects of the model such as the inclusion or exclusion of explanatory variables. While an exhaustive check is impossible, at least some effort in this area should be made.
Predictive Accuracy & Model Comparison
A standard way to check for model adequacy is simply to investigate whether the predictions on new data are accurate. In general, the measure of predictive accuracy will be specific to the data problem, and involve posterior simulation of the sort covered in the next section. In addition, while oftentimes new data is hard to come by, assuming one has sufficient data to begin with, one could set aside part of it specifically for this purpose. In this manner one trains and tests the model in much the same fashion as machine learning approaches. In fact, one can incorporate the validation process as an inherent part of the modeling process in the Bayesian context just as you would there.
For model comparison of out of sample predictive performance, there are information measures similar to the Akaike information criterion (AIC), that one could use in the Bayesian environment. One not to use is the so-called Bayesian information criterion (or BIC), which is not actually Bayesian nor a measure of predictive accuracy. Some approaches favor the DIC, or deviance information criterion, as part of its summary output, which is a somewhat Bayesian version of the AIC. More recently developed are measures like LOO (leave-one-out criterion) and the WAIC, or Watanabe-AIC35, which are fully Bayesian approaches. Under some conditions, the DIC and WAIC measures are asymptotically equivalent to Bayesian leave-one-out cross validation, as the AIC is under the classical setting.
Posterior Predictive Checking: Statistical
For an overall assessment of model fit, we can examine how well the model can reproduce the data at hand given the \(\theta\) draws from the posterior. We discussed earlier the posterior predictive distribution for a future observation \(\tilde{y}\)36, and here we’ll dive in to using it explicitly. There are two sources of uncertainty in our regression model, the variance in \(y\) not explained by the model (\(\sigma^2\)), and posterior uncertainty in the parameters due to having a finite sample size. As \(N\rightarrow\infty\), the latter goes to zero, and so we can simulate draws of \(\tilde{y} \sim N(\tilde{X}\beta, \sigma^2I)\)37. If \(\tilde{X}\) is the model data as in the following, then we will refer to \(y^{\textrm{Rep}}\) instead of \(\tilde{y}\).
For our model, this entails extracting the simulated values from the model object, and taking a random draw from the normal distribution based on the \(\beta\) and \(\sigma\) that are drawn to produce our replicated data, \(y^{\textrm{Rep}}\) (see Gelman et al. (2013), Appendix C). In what follows, I write out the process explicitly, but bayesplot, rstanarm, and brms make this straightforward, possibly with a single line of code, the latter packages using bayesplot. In addition, it’s often simpler to create the \(y^{\textrm{Rep}}\) as part of your generated quantities section of the model code if modeling with Stan explicitly.
# extract the simulated draws from the posterior and note the number for nsims
theta = extract(fit)
betas = theta$beta
sigmas = theta$sigma
nsims = length(theta$sigma)
# produce the replications and inspect
yRep = sapply(1:nsims, function(s) rnorm(250, X %*% betas[s,], sigmas[s]))
str(yRep) num [1:250, 1:1000] 4.44 4.47 1.12 4.3 10.04 ...With the \(y^{\textrm{Rep}}\) in hand we can calculate all manner of statistics that might be of interest38.
As a starting point, we can check our minimum value among the replicated data sets versus that observed in the data.
min_rep = apply(yRep, 2, min)
min_y = min(y)
c(mean(min_rep), min_y)[1] -2.831253 -6.056495prop.table(table(min_rep > min_y))
FALSE TRUE
0.013 0.987 sort(y)[1:5][1] -6.0564952 -3.2320527 -2.6358579 -2.1649084 -0.8366149
These results suggest we may be having difficulty picking up the lower tail of the target variable, as our average minimum is notably higher than that seen in the data, and almost all our minimums are greater than the observed minimum (\(p=.99\)). While in this case where we are dealing with a simulated data set and we know that assuming the normal distribution for our sampling distribution is appropriate, this might otherwise have given us pause for further consideration. A possible solution would be to assume a \(t\) distribution for the likelihood, which would have fatter tails and thus possibly be better able to handle extreme values. We’ll show an example of this later. In this case it is just that by chance one of the \(y\) values, -6.056, is fairly extreme relative to the others. Also, it is typically difficult to capture extreme values in practice. As a comparison, the model actually captures the 5th, 10th (shown), and 25th quantile values very well.

See ppc_stat in bayesplot.
In general, we can devise a test statistic, \(T_{\textrm{Rep}}\), and associated p-value to check any particular result of interest based on the simulated data. The p-value in this context is simply the percentage of times the statistic of interest is equal to or more extreme than the statistic, \(T_y\), calculated for the original data. Thus p-values near 0 or 1 are indicative of areas where the model is falling short in some fashion. Sometimes \(T_y\) may be based on the \(\theta\) parameters being estimated, and thus you’d have a \(T_y\) for every posterior draw. In such a case, one might examine the scatterplot of \(T_{\textrm{Rep}}\) vs. \(T_y\), or examine a density plot of the difference between the two. In short, this is an area where one can get creative, and the bayesplot package can help with make this fairly easy. However, it must be stressed that we are not trying to accept or reject a model hypothesis as in the frequentist setting- we’re not going to throw a model out because of an extreme p-value in our posterior predictive check. We are merely trying to understand the model’s shortcomings as best we can, and make appropriate adjustments if applicable. It is often the case that the model will still be good enough for practical purposes.
Posterior Predictive Checking: Graphical
As there are any number of ways to do statistical posterior predictive checks, we have many options for graphical inspection as well. I show a graph of our average fitted values versus the observed data as a starting point. The average is over all posterior draws of \(\theta\).

See ppc_scatter_avg in bayesplot.
Next, I show density plots for a random sample of 20 of the replicated data sets along with that of the original data (shaded). It looks like we’re doing pretty well here. The subsequent figure displays the density plot for individual predictions for a single value of \(y\) from our data. In general, the model captures this particular observation of the data decently.


See ppc_dens_overlay in bayesplot.
We can also examine residual plots of \(y - E(y|X,\theta)\) as with standard analysis, shown as the final two figures for this section. The first shows such ‘realized’ residuals, so-called as they are based on a posterior draw of \(\theta\) rather than point estimation of the parameters, versus the expected values from the model. The next plot shows the average residual against the average fitted value. No discernible patterns are present, so we may conclude that the model is adequate in this regard39.


Summary
As with standard approaches, every model should be checked to see whether it holds up under scrutiny. The previous discussion suggests only a few ways one might go about checking whether the model is worthwhile, but this is a very flexible area where one can answer questions beyond model adequacy and well beyond what traditional models can tell us. Not only is this phase of analysis a necessity, one can use it to explore a vast array of potential questions the data presents, and maybe even answer a few.
References
I wonder how many results have been published on models that didn’t converge with the standard MLE. People will often ignore warnings as long as they get some sort of result.↩︎
Recall again that we are looking for convergence to a distribution, not a point estimate of a specific parameter.↩︎
This is the ‘naive’ estimate that packages like coda might provide in the summary output.↩︎
Gelman devotes an entire chapter to this topic to go along with examples of model checking throughout his text. Much of this section follows that outline.↩︎
See Gelman et al. (2013) for a review and references. See Vehtari & Gelman (2014) for some more on WAIC, as well as the R package loo. In general, the Stan group prefers loo Vehtari, Gelman, and Gabry (2017).↩︎
\(p(\tilde{y}|y) = \int p(\tilde{y}|\theta)p(\theta|y)\mathrm{d}\theta\)↩︎
Technically, in the conjugate case the posterior predictive is t-distributed because of the uncertainty in the parameters, though it doesn’t take much sample size for simple models to get to approximately normal. Formally, with \(\hat{\beta}\) being our mean \(\beta\) estimate from the posterior, this can be represented as:
\(\tilde{y} \sim t(\tilde{X}\hat{\beta}, \sigma^2 + \textrm{parUnc}, \textrm{df}=N-k)\)↩︎In many cases you might want to produce this in the generated quantities section of your Stan code, but doing so outside of it will keep the stanfit object smaller, which may be desirable.↩︎
The two plots directly above replicate the figures in 6.11 in Gelman 2013.↩︎