Graphical Models
A graphical model can be seen as a mathematical or statistical construct connecting nodes (or vertices) via edges (or links). When pertaining to statistical models, the nodes might represent variables of interest in our data set, and edges specify the relationships among them. Visually they are depicted in the style of the following examples.
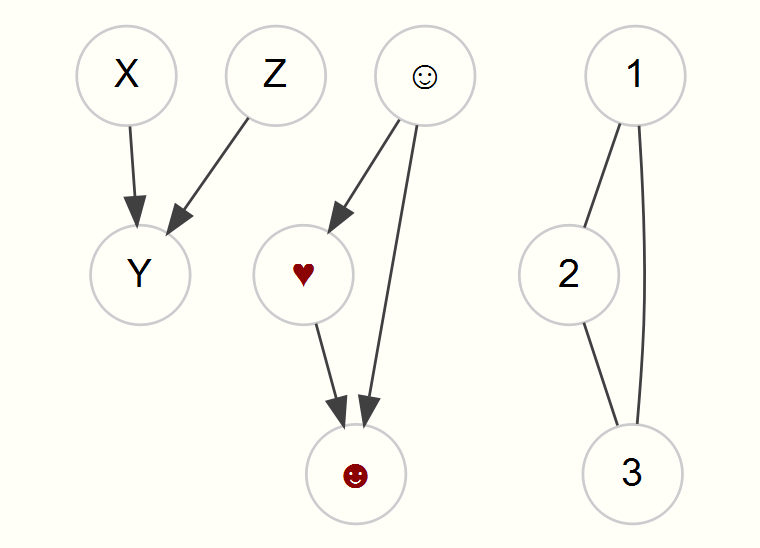
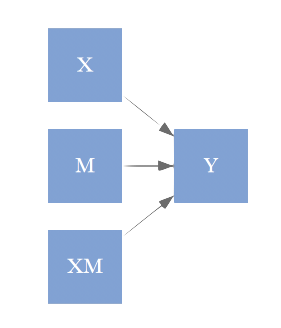
Any statistical model you’ve conducted can be expressed as a graphical model. As an example, the first graph with nodes X, Y, and Z might represent a regression model in which X and Z predict Y. The emoticon graph shows an indirect effect, and the 123 graph might represent a correlation matrix.
A key idea of a graphical model is that of conditional independence, something one should keep in mind when constructing their models. The concept can be demonstrated with the following graph.
In this graph, X is conditionally independent of Z given Y- there is no correlation between X and Z once Y is accounted for2. We will revisit this concept when discussing path analysis and latent variable models. Graphs can be directed, undirected, or mixed. Directed graphs have arrows, sometimes implying a causal flow (a difficult endeavor to demonstrate explicitly) or noting a time component. Undirected graphs merely denote relations among the nodes, while mixed graphs might contain both directional and symmetric relationships. Most of the models discussed in this document will be directed or mixed.
Directed Graphs
As noted previously, we can represent standard models as graphical models. In most of these cases we’d be dealing with directed or mixed graphs. Almost always we are specifically dealing with directed acyclic graphs, where there are no feedback loops.
Standard linear model
Let’s start with the standard linear model (SLiM), i.e. a basic regression we might estimate via ordinary least squares (but not necessarily). In this setting, we want to examine the effect of each potential predictor (x* in the graph) on the target variable (y). The following shows what the graphical model might look like.
While we start simpler, we can use much of the same sort of thinking with more complex models later. In what follows, we’ll show that whether we use a standard R modeling approach (via the lm function), or an SEM approach (via the sem function in lavaan), the results are identical aside from the fact that sem is using maximum likelihood (so the variances will be slightly different). First, we’ll with the standard lm approach.
mcclelland = haven::read_dta('data/path_analysis_data.dta')
lmModel = lm(math21 ~ male + math7 + read7 + momed, data=mcclelland)Now we can do the same model using the lavaan package, and while the input form will change a bit, and the output will be presented in a manner consistent with SEM, the estimated parameters are identical. Note that the square of the residual standard error in the lm output is compared to the variance estimate in the lavaan output.
library(lavaan)
model = "
math21 ~ male + math7 + read7 + momed
"
semModel = sem(model, data=mcclelland, meanstructure = TRUE)
summary(lmModel)
Call:
lm(formula = math21 ~ male + math7 + read7 + momed, data = mcclelland)
Residuals:
Min 1Q Median 3Q Max
-6.9801 -1.2571 0.1376 1.4544 5.7471
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.84310 1.16418 4.160 4.08e-05 ***
male 1.20609 0.25831 4.669 4.44e-06 ***
math7 0.31306 0.04749 6.592 1.76e-10 ***
read7 0.08176 0.01638 4.991 9.81e-07 ***
momed -0.01684 0.06651 -0.253 0.8
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.329 on 324 degrees of freedom
(101 observations deleted due to missingness)
Multiple R-squared: 0.258, Adjusted R-squared: 0.2488
F-statistic: 28.16 on 4 and 324 DF, p-value: < 2.2e-16lavaan 0.6-2 ended normally after 21 iterations
Optimization method NLMINB
Number of free parameters 6
Used Total
Number of observations 329 430
Estimator ML
Model Fit Test Statistic 0.000
Degrees of freedom 0
Minimum Function Value 0.0000000000000
Parameter Estimates:
Information Expected
Information saturated (h1) model Structured
Standard Errors Standard
Regressions:
Estimate Std.Err z-value P(>|z|)
math21 ~
male 1.206 0.256 4.705 0.000
math7 0.313 0.047 6.642 0.000
read7 0.082 0.016 5.030 0.000
momed -0.017 0.066 -0.255 0.799
Intercepts:
Estimate Std.Err z-value P(>|z|)
.math21 4.843 1.155 4.192 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.math21 5.341 0.416 12.826 0.000
R-Square:
Estimate
math21 0.258As we will see in more detail later, SEM incorporates more complicated regression models, but at this point the parameters have the exact same understanding as our standard regression, because there is no difference between the two models except conceptually, in that SEM explicitly brings a causal aspect to bear on the interpretation. As we go along, we can see the structural equation models statistically as generalizations of those we are already well acquainted with, and so one can use that prior knowledge as a basis for understanding the newer ones.
Path Analysis
Path Analysis, and thus SEM, while new to some, is in fact a very, very old technique, statistically speaking3. It can be seen as a generalization of the SLiM approach that can allow for indirect effects and multiple target variables. Path analysis also has a long history in the econometrics literature though under different names (e.g. instrumental variable regression, 2-stage least squares etc.), and through the computer science realm through the use of graphical models more generally. As such, there are many tools at your disposal for examining such models, and I’ll iterate that much of the SEM perspective on modeling comes largely from specific disciplines (especially psychology and education), while other approaches that are very common in other disciplines may be better for your situation.
Types of relationships
The types of potential relationships examined by path analysis can be seen below.
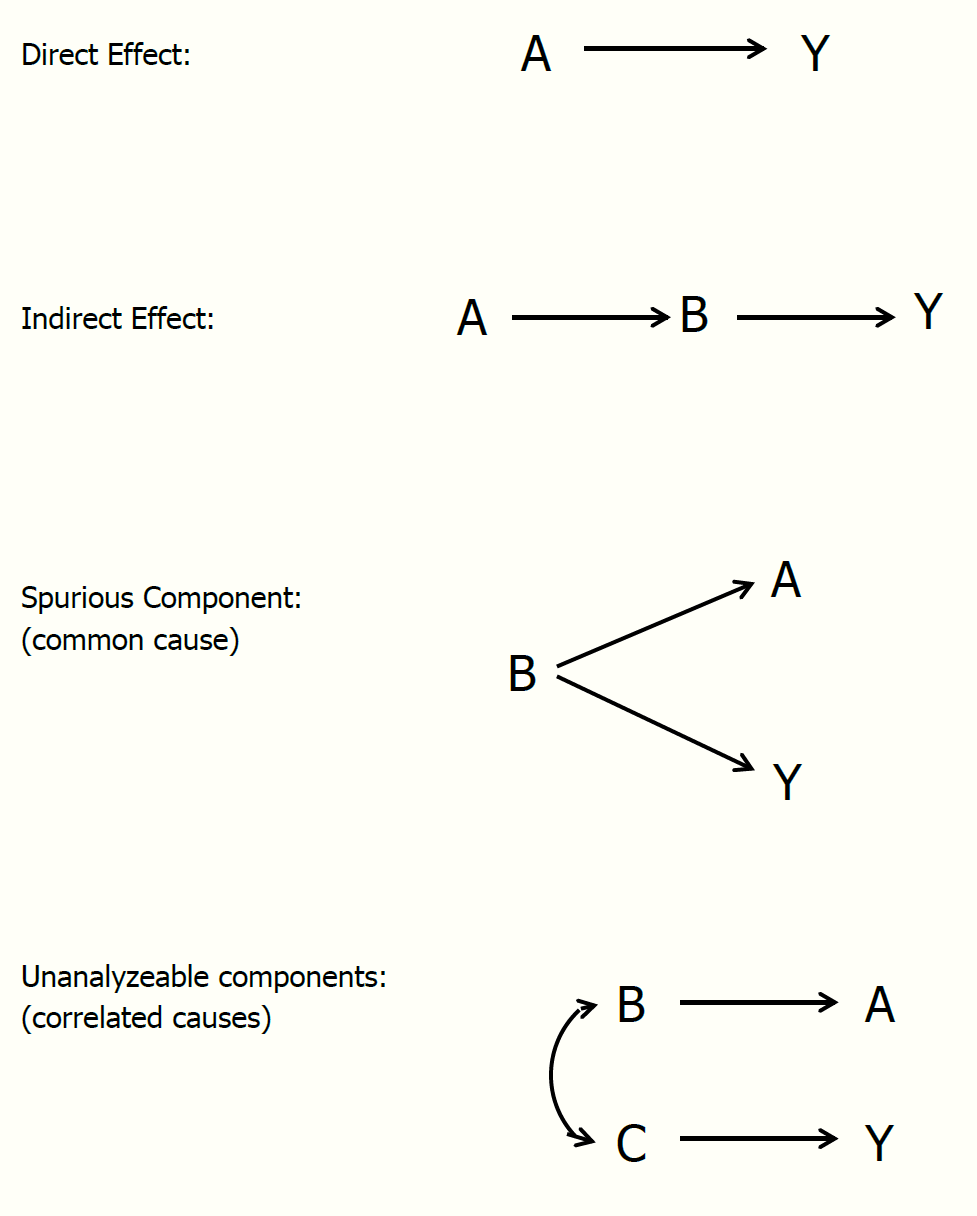
Most models deal only with direct effects. In this case there are no intervening variables we wish to consider. If such variables do exist, we are then dealing with what is often called a mediation model, and must interpret both indirect and (potentially) direct effects. When dealing with multiple outcomes, some may have predictors in common, such that the outcomes’ correlation can be explained by those common causes (this will come up in factor analysis later). Often there are unanalyzed correlations. As an example, every time you run a regression, the correlations among predictor variables are left ‘unanalyzed’.
Multiple Targets
While relatively seldom used, multivariate linear regression4 is actually very straightforward in some programming environments such as R, and conducting models with multivariate outcomes does not require anything specific to SEM, but that is the realm we’ll stick with. Using the McClelland data, let’s try it for ourselves. First, let’s look at the data to get a sense of things.
| Variable | N | Mean | SD | Min | Q1 | Median | Q3 | Max | Missing |
|---|---|---|---|---|---|---|---|---|---|
| attention4 | 430 | 17.93 | 3.05 | 9 | 16 | 18 | 20 | 25 | 0 |
| math21 | 364 | 11.21 | 2.69 | 3 | 10 | 11 | 13 | 17 | 66 |
| college | 286 | 0.37 | 0.48 | 0 | 0 | 0 | 1 | 1 | 144 |
| vocab4 | 386 | 10.18 | 2.53 | 4 | 9 | 10 | 12 | 17 | 44 |
| math7 | 397 | 10.73 | 2.76 | 4 | 9 | 11 | 13 | 19 | 33 |
| read7 | 390 | 31.57 | 8.05 | 18 | 25 | 30 | 37 | 61 | 40 |
| read21 | 360 | 73.67 | 8.52 | 35 | 69 | 76 | 80 | 84 | 70 |
| adopted | 430 | 0.49 | 0.50 | 0 | 0 | 0 | 1 | 1 | 0 |
| male | 430 | 0.55 | 0.50 | 0 | 0 | 1 | 1 | 1 | 0 |
| momed | 419 | 14.83 | 2.03 | 10 | 13 | 15 | 16 | 21 | 11 |
| college_missing | 430 | 0.33 | 0.47 | 0 | 0 | 0 | 1 | 1 | 0 |
While these are only weakly correlated variables to begin with, one plausible model might try to predict math and reading at age 21 with measures taken at prior years.
model = "
read21 ~ attention4 + vocab4 + read7
math21 ~ attention4 + math7
read21 ~~ 0*math21
"
mvregModel = sem(model, data=mcclelland, missing='listwise', meanstructure = T)
coef(mvregModel)read21~attention4 read21~vocab4 read21~read7 math21~attention4 math21~math7 read21~~read21
0.128 0.377 0.537 0.091 0.347 51.837
math21~~math21 read21~1 math21~1
5.965 50.290 5.856 The last line of the model code clarifies that we are treating math21 and read21 as independent, and as such we are simply running two separate regressions simultaneously. Note also that the coefficients in the output with ~1 are the intercepts. We can compare this to standard R regression. A first step is taken to make the data equal to what was used in lavaan. For that we can use the dplyr package to select the necessary variables for the model, and then omit rows that have any missing.
mcclellandComplete = select(mcclelland, read21, math21, attention4, vocab4, read7, math7) %>%
na.omit
lm(read21 ~ attention4 + vocab4 + read7, data=mcclellandComplete)
Call:
lm(formula = read21 ~ attention4 + vocab4 + read7, data = mcclellandComplete)
Coefficients:
(Intercept) attention4 vocab4 read7
50.2904 0.1275 0.3770 0.5368
Call:
lm(formula = math21 ~ attention4 + math7, data = mcclellandComplete)
Coefficients:
(Intercept) attention4 math7
5.85633 0.09103 0.34732 Note that had the models for both outcomes been identical, we could have run both outcomes simultaneously using cbind on the dependent variables5. However, we can and probably should estimate the covariance of math and reading skill at age 21. Let’s rerun the path analysis removing that constraint.
model = "
read21 ~ attention4 + vocab4 + read7
math21 ~ attention4 + math7
"
mvregModel = sem(model, data=mcclelland, missing='listwise', meanstructure = T)
coef(mvregModel)read21~attention4 read21~vocab4 read21~read7 math21~attention4 math21~math7 read21~~read21
0.140 0.388 0.494 0.092 0.330 51.958
math21~~math21 read21~~math21 read21~1 math21~1
5.968 3.202 51.316 6.020 We can see that the coefficients are now slightly different from the SLiM approach. The read21~~math21 value represents the residual covariance between math and reading at age 21, i.e. after accounting for the other covariate relationships modeled, it tells us how correlated those skills are. Using summary will show it to be statistically significant. I additionally ask for standardized output to see the correlation along with the covariance. It actually is not very strong even if it is statistically significant.
lavaan 0.6-2 ended normally after 38 iterations
Optimization method NLMINB
Number of free parameters 10
Used Total
Number of observations 304 430
Estimator ML
Model Fit Test Statistic 26.965
Degrees of freedom 3
P-value (Chi-square) 0.000
Parameter Estimates:
Information Expected
Information saturated (h1) model Structured
Standard Errors Standard
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
read21 ~
attention4 0.140 0.134 1.043 0.297 0.140 0.051
vocab4 0.388 0.163 2.378 0.017 0.388 0.116
read7 0.494 0.050 9.942 0.000 0.494 0.486
math21 ~
attention4 0.092 0.045 2.041 0.041 0.092 0.109
math7 0.330 0.049 6.674 0.000 0.330 0.351
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.read21 ~~
.math21 3.202 1.026 3.119 0.002 3.202 0.182
Intercepts:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.read21 51.316 3.045 16.854 0.000 51.316 6.056
.math21 6.020 0.951 6.327 0.000 6.020 2.285
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.read21 51.958 4.214 12.329 0.000 51.958 0.724
.math21 5.968 0.484 12.329 0.000 5.968 0.860Whether or not to take a multivariate/path-analytic approach vs. separate regressions is left to the researcher. It’s perhaps easier to explain univariate models in some circumstances. But as the above shows, it doesn’t take much to take into account correlated target variables.
Indirect Effects
So path analysis allows for multiple target variables, with the same or a mix of covariates for each target. What about indirect effects? Standard regression models examine direct effects only, and the regression coefficients reflect that direct effect. However, perhaps we think a particular covariate causes some change in another, which then causes some change in the target variable. This is especially true when some measures are collected at different time points. Note that in SEM, any variable in which an arrow is pointing to it in the graphical depiction is often called an endogenous variable, while those that only have arrows going out from them are exogenous. Exogenous variables may still have (unanalyzed) correlations among them. As we will see later, both observed and latent variables may be endogenous or exogenous.
Consider the following model.
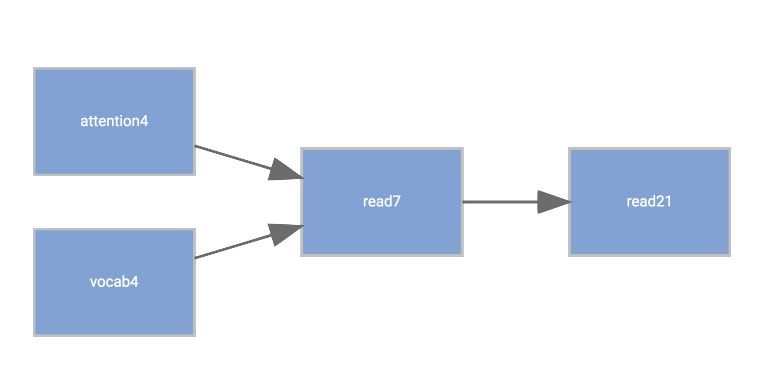
Here we posit attention span and vocabulary at age 4 as indicative of what to expect for reading skill at age 7, and that is ultimately seen as a precursor to adult reading ability. In this model, attention span and vocabulary at 4 only have an indirect effect on adult reading ability through earlier reading skill. At least temporally it makes sense, so let’s code this up.
model = "
read21 ~ read7
read7 ~ attention4 + vocab4
"
mediationModel = sem(model, data=mcclelland)
summary(mediationModel, rsquare=TRUE)lavaan 0.6-2 ended normally after 21 iterations
Optimization method NLMINB
Number of free parameters 5
Used Total
Number of observations 305 430
Estimator ML
Model Fit Test Statistic 6.513
Degrees of freedom 2
P-value (Chi-square) 0.039
Parameter Estimates:
Information Expected
Information saturated (h1) model Structured
Standard Errors Standard
Regressions:
Estimate Std.Err z-value P(>|z|)
read21 ~
read7 0.559 0.050 11.152 0.000
read7 ~
attention4 0.270 0.151 1.791 0.073
vocab4 0.488 0.186 2.629 0.009
Variances:
Estimate Std.Err z-value P(>|z|)
.read21 53.047 4.296 12.349 0.000
.read7 66.779 5.408 12.349 0.000
R-Square:
Estimate
read21 0.290
read7 0.035What does this tell us? As before, we interpret the results as we would any other regression model, though conceptually there are two sets of models to consider (though they are estimated simultaneously6), one for reading at age 7 and one for reading at age 21. And indeed, one can think of path analysis as a series of linked regression models7. Here we have positive relationships between both attention and vocabulary at age 4 and reading at age 7, and a positive effect of reading at age 7 on reading at age 21. Statistically speaking, our model appears to be viable, as there appear to be statistically significant estimates for each path.
However, look at the R2 value for reading at age 7. We now see that there is little to no practical effect of the age 4 variables at all, as all we are accounting for is < 4% of the variance, and all that we have really discovered is that prior reading ability affects later reading ability.
We can test the indirect effect itself by labeling the paths in the model code. In the following code, I label them based on the first letter of the variables involved (e.g. vr refers to the vocab to reading path), but note that these are arbitrary names. I also add the direct effects of the early age variable. While the indirect effect for vocab is statistically significant, as we already know there is not a strong correlation between these two variables, it’s is largely driven by the strong relationship between reading at age 7 and reading at age 21, which is probably not all that interesting. A comparison of AIC values, something we’ll talk more about later, would favor a model with only direct effects8.
model = "
read21 ~ rr*read7 + attention4 + vocab4
read7 ~ ar*attention4 + vr*vocab4
# Indirect effects
att4_read21 := ar*rr
vocab4_read21 := vr*rr
"
mediationModel = sem(model, data=mcclelland)
summary(mediationModel, rsquare=TRUE, fit=T, std=T)lavaan 0.6-2 ended normally after 28 iterations
Optimization method NLMINB
Number of free parameters 7
Used Total
Number of observations 305 430
Estimator ML
Model Fit Test Statistic 0.000
Degrees of freedom 0
Model test baseline model:
Minimum Function Test Statistic 121.544
Degrees of freedom 5
P-value 0.000
User model versus baseline model:
Comparative Fit Index (CFI) 1.000
Tucker-Lewis Index (TLI) 1.000
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2108.612
Loglikelihood unrestricted model (H1) -2108.612
Number of free parameters 7
Akaike (AIC) 4231.224
Bayesian (BIC) 4257.267
Sample-size adjusted Bayesian (BIC) 4235.066
Root Mean Square Error of Approximation:
RMSEA 0.000
90 Percent Confidence Interval 0.000 0.000
P-value RMSEA <= 0.05 NA
Standardized Root Mean Square Residual:
SRMR 0.000
Parameter Estimates:
Information Expected
Information saturated (h1) model Structured
Standard Errors Standard
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
read21 ~
read7 (rr) 0.536 0.050 10.607 0.000 0.536 0.515
attentin4 0.134 0.134 0.998 0.318 0.134 0.048
vocab4 0.381 0.166 2.299 0.021 0.381 0.111
read7 ~
attentin4 (ar) 0.270 0.151 1.791 0.073 0.270 0.101
vocab4 (vr) 0.488 0.186 2.629 0.009 0.488 0.148
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.read21 51.926 4.205 12.349 0.000 51.926 0.695
.read7 66.779 5.408 12.349 0.000 66.779 0.965
R-Square:
Estimate
read21 0.305
read7 0.035
Defined Parameters:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
att4_read21 0.145 0.082 1.766 0.077 0.145 0.052
vocab4_read21 0.261 0.102 2.552 0.011 0.261 0.076In the original article, I did not find their description or diagrams of the models detailed enough to know precisely what the model was in the actual study9, but here is at least one interpretation if you’d like to examine it further.
More mediation
Here I would like to demonstrate a powerful approach to mediation models using Imai’s mediation package. It is based on a theoretical framework that allows for notably complex models for mediator, outcome or both, including different types of variables for the mediator and outcome. While it is simple to conduct, the results suggest there are more things to think about when it comes to mediation.
To begin, we will run two separate models, one for the mediator and one for the outcome, using the mediate function to use them to estimate the mediation effect. In this case we’ll focus on the indirect effect of attention.
library(mediation)
mediator_model = lm(read7 ~ attention4 + vocab4, data=mcclellandComplete)
outcome_model = lm(read21 ~ read7 + attention4 + vocab4, data=mcclellandComplete)
results = mediate(mediator_model, outcome_model, treat="attention4", mediator = 'read7')
summary(results)
Causal Mediation Analysis
Quasi-Bayesian Confidence Intervals
Estimate 95% CI Lower 95% CI Upper p-value
ACME 0.1451 -0.0102 0.31 0.068 .
ADE 0.1281 -0.1213 0.39 0.348
Total Effect 0.2732 -0.0193 0.58 0.060 .
Prop. Mediated 0.5232 -0.6462 2.72 0.092 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Sample Size Used: 304
Simulations: 1000 The first thing to note is that there are multiple results to consider, we have the average causal mediated effect, the average direct effect, the total effect and the proportion mediated. What is an average causal mediated effect? First, think about a standard experimental design in which participants are assigned to control and treatment groups. Ideally, if we really wanted to know about true effects, we’d see the outcome when an individual was a control and when they were were in the treatment. The true causal effect for an individual would be the difference between their scores when in the control and when in the treatment. Thus there are two hypothetical situations of different conditions, or counterfactuals, of interest- what would be the potential outcome of a control case if they treated, and vice versa for those in the treated group10.
This potential outcomes framework is the essence of the mediate function. In the presence of a mediator variable, we can start by defining the average direct effect (ζ) as follows, where \(Y_i\) is the potential outcome for unit \(i\) (e.g. a person), \(M_i\) the potential outcome of the mediator, and \(T_i\) the treatment status. From the mediate function help file11:
The expected difference in the potential outcome when the treatment is changed but the mediator is held constant at the value that would realize if the treatment equals \(t\)
\[ζ(t) = E[Y(t_1, M(t)) - Y(t_0, M(t))]\]
The ACME meanwhile is:
The expected difference (δ) in the potential outcome when the mediator took the value that would realize under the treatment condition as opposed to the control condition, while the treatment status itself is held constant.
\[δ(t) = E[Y(t, M(t_1)) - Y(t, M(t_0))]\]
where \(t\), \(t_1\), \(t_0\) are particular values of the treatment T such that \(t_1 \neq t_0\), M(t) is the potential mediator, and Y(t,m) is the potential outcome variable.
Adding these two gives us the total effect. In the case of continuous variables, the values for ‘control’ and ‘treatment’ are fixed to specific values of interest, but by default represent a unit difference in the values of the variable. The results of the mediate function are based on a simulation approach, and averaged over those simulations. You’ll note there is also a ‘proportion of effect mediated’. This is the size of the ACME to the the total effect. It too is averaged over the simulations (and thus is not simply the ACME/Total Effect reported values). It’s not clear to me how useful of a notion this is, and as noted by the boundaries, it’s actually a ratio as opposed to a true proportion (as calculated), such that under some simulations the value can be negative or greater than 1.
You may compare the result with the previous lavaan results. I’ve rerun it with bootstrap estimates (set se='boot') to be more in keeping with the simulation approach of Imai12. You could also use the blavaan package to get true Bayesian estimates.
lhs op rhs label est se z pvalue ci.lower ci.upper
1 att4_read21 := ar*rr att4_read21 0.145 0.081 1.790 0.074 -0.009 0.304
2 read21 ~ attention4 0.134 0.136 0.981 0.327 -0.121 0.426As expected, the results of lavaan and mediation packages largely agree with one another. However, the potential outcomes framework has the product-of-paths approach as a special case, and thus generalizes to different models and types of variables for the mediator and outcome.
Explicit Example
While we have shown how to use the tool and compared the outputs, let’s make things more simple and explicit to be sure that we understand what’s going on. The following closely follows Pearl (section 4.4)13. Consider the following three variable setup with estimated parameters. We have a treatment variable that is dummy coded with 0 = ‘Control group’ and 1 = ‘Treatment group’, a continuous Mediator and Target variable.
In addition, we’ll consider just a single individual, whose observed values are ‘control’, i.e. 0, 3 for the mediator, and 2 for the target. We define the unique values \(\epsilon_*\) that represent invariant characteristics that exist regardless of changes to interventions or counterfactual hypotheses and set them to the following:
\(\epsilon_1 = 0\)
\(\epsilon_2 = 3 - 0*.3 = 3\)
\(\epsilon_3 = 2 - 0*.5 - 3*.2 = 1.4\)
If a person is in the control group, this setup suggests the predicted value for the Target would be 3*.2 + 1.4 = 2. Let’s now figure out what the value would be if this person was in the treatment. The Mediator value would now be 3 + 1*.3 = 3.3. This would in turn result in a predicted Target value as follows: 1.4 + 3.3*.2 + 1*.5 = 2.56. And we could take this approach for other situations. We could, for example, ask what the expected value be if the Treatment level is 0, but the Mediator was at whatever value it would have been, had the person received the treatment? The value is 3.3*.2 + 1.4 = 2.06, which if we subtract from when they are are fully in the control group gives us the mediated effect 2.06 - 2 = .06. In this linear model it is equivalent to indirect effect via the product-of-paths approach, .3*.2 = .06. But now with the estimate based on the target variable rather than coefficients, we don’t have to be restricted to linear models.
One thing to note about the above, despite not having a data set or statistical result, we engaged in attempting to understand causal relations among the variables under theoretical consideration. Even though we may use the tools of statistical analysis, the key things that separates SEM and common regression approaches is the explicit assumption of causal relations and the ability to test some causal claims14.
Cavets about indirect effects
One should think very hard about positing an indirect effect, especially if there is no time component or obvious pseudo-causal path. If the effect isn’t immediately obvious, or you are dealing with cross-sectional data, then you should probably just examine the direct effects. Unlike other standard explorations one might do with models (e.g. look for nonlinear relationships), the underlying causal connection and associated assumptions are more explicit in this context. Many models I’ve seen in consulting struck me as arbitrary as far as which covariate served as the mediator, required a fairly convoluted explanation for its justification, or ignored other relevant variables because the reasoning would have to include a plethora of indirect effects if it were to be logically consistent. Furthermore, I can often ask one or two questions and will discover that researchers are actually interested in interactions (i.e. moderation), rather than indirect effects.
This document will not get into models that have moderated mediation and mediated moderation. In my experience these are often associated with models that are difficult to interpret at best, or are otherwise not grounded very strongly in substantive concerns15. However, there are times, e.g. in experimental settings, which surprisingly few SEM are applied to for reasons unknown, where perhaps it would be very much appropriate. It is left to the reader to investigate those particular complexities when the time comes.
Too often investigators will merely throw in these indirect effects and simply report whether the effect is significant or not. If you hide their results and ask if the indirect effect is positive or negative, I suspect they might not even know. Even if not used, I think the perspective of the potential outcomes framework can help one think appropriately about the situation, and avoid unnecessary complications. If one wants to explore possible indirect paths, there are better approaches which are still rooted within the structural causal model framework, which we’ll see shortly. In addition, a mediation model should always be compared to a simpler model with no mediation (e.g. via AIC).
Terminology issues
Some refer to models with indirect effects as mediation models16, and that terminology appears commonly in the SEM (and esp. psychology) literature17. Many applied researchers just starting out with SEM often confuse the term with moderation, which is called an interaction in every other statistical modeling context. As you begin your SEM journey, referring to indirect effects and interactions will likely keep you clear on what you’re modeling, and perhaps be clearer to those who may not be as familiar with SEM when you present your work.
In models with moderation, one will often see a specific variable denoted as the moderator. However, this is completely arbitrary in the vast majority of situations in which it is used. In a typical model that includes an interaction, it makes just as much sense to say that the \(\mathcal{A} \rightarrow \mathcal{Y}\) relationship varies as a function of \(\mathcal{B}\) as it does the \(\mathcal{B} \rightarrow \mathcal{Y}\) relationship varies as a function of \(\mathcal{A}\). Some suggest using the term moderation when only when there is a potential causal relation, almost always temporal in nature, such that the moderator variable precedes the variable in question. In addition, the moderator and the variable moderated must be uncorrelated18. While such restrictions would render almost every model I’ve ever seen that uses the term moderation as an ordinary interaction instead, the idea is that the moderator has a causal effect on the path between the variable in question and its target. This is why you see graphs like the one to the left below, which has no tie to any statistical model and generally confuses people more often than it illuminates (the correct graph is to the right). Again though, the actual model is statistically indistinguishable from a standard model including an interaction, so if you want to understand moderation, you simply need to understand what an interaction is.
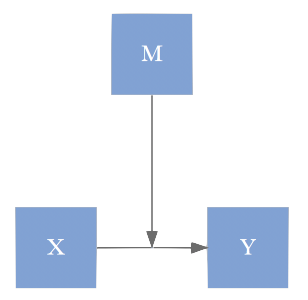
Like SEM relative to standard modeling techniques, so too is mediation and moderation to indirect effects and interactions. Statistically they are indistinguishable models. Theoretically however, there is an underlying causal framework, and in some cases specific causal claims can be tested (e.g. via simulation).
Recently I have also heard the phrase ‘spotlight analysis’ to refer to a categorical by continuous variable interaction. Please don’t apply new terms to very old techniques in an attempt to make a model sound more interesting19. The work should speak for itself and be as clearly expressed as possible.
The gist is that if you want to talk about your relations using the terms ‘mediation’ and ‘moderation’ you’ll want to have specific and explicit causal relations among the variables. If you are unsure, then the answer is clearly that you don’t have that situation. However, you can still incorporate interactions as usual, and explore potential indirect effects by modeling the correlations, e.g. leaving the indirect path undirected.
Aside: Instrumental variables
Path analysis of a different sort has a long history in econometrics. A very common approach one may see utilized is instrumental variable analysis. The model can be depicted graphically as follows:
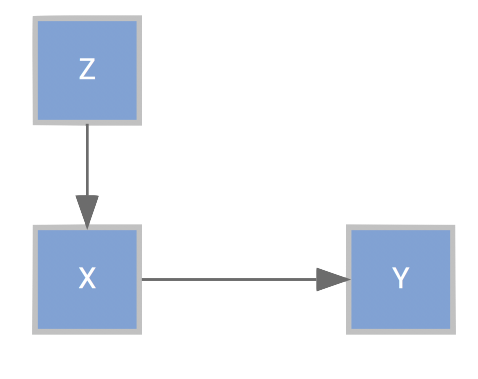
In the graph, \(\mathcal{Y}\) is our target variable, \(\mathcal{X}\) is the causal variable of interest, and \(\mathcal{Z}\) the instrument. The instrumental variable must not be correlated with disturbance of the target variable (later depicted as \(\mathcal{U}\)), and only has an indirect relation to \(\mathcal{Y}\) through \(\mathcal{X}\). Neither target nor causal variable are allowed to effect the instrument directly or indirectly. In graph theory, this involves the notion of conditional independence we’ve mentioned before, where \(\mathcal{Z}\) is conditionally independent of Y given X, or in other words, if we remove the \(\mathcal{X} \rightarrow \mathcal{Y}\) path, \(\mathcal{Z}\) and \(\mathcal{Y}\) are independent. Furthermore, \(\mathcal{Z}\) is not conditionally independent of \(\mathcal{X}\) with the removal of that path20.
The motivating factor for such a model is that the simple \(\mathcal{X} \rightarrow \mathcal{Y}\) path may not provide a means for determining a causal relationship, particularly if \(\mathcal{X}\) is correlated with the error. As an example21, if we look at the relationship of earnings with education, the unspecified causes of earnings might include things, e.g. some general ‘ability’, that would be correlated with the potential causal variable of education attained. With error \(\mathcal{U}\) we can show the following diagram that depicts the problem.
When \(\mathcal{X}\) is endogenous, that is not the case. Changes in \(\mathcal{X}\) are associated with \(\mathcal{Y}\), but also \(\mathcal{U}\).
There are now multiple effects of \(\mathcal{X}\) on \(\mathcal{Y}\), both directly from \(\mathcal{X}\) and indirectly from \(\mathcal{U}\). We can measure the association between \(\mathcal{X}\) and \(\mathcal{Y}\), but not the causal relationship.
An attempt can be made to remedy the problem by using an instrument, leading the following graph.
The instrument \(\mathcal{Z}\) affects \(\mathcal{X}\) and thus is correlated with \(\mathcal{Y}\) indirectly. However, unlike \(\mathcal{X}\), it is uncorrelated with \(\mathcal{U}\). This assumption excludes \(\mathcal{Z}\) from having a direct effect in the model for \(\mathcal{Y}\). If instead \(\mathcal{Y}\) depended on both \(\mathcal{X}\) and \(\mathcal{Z}\) but only \(\mathcal{X}\) has a direct path to \(\mathcal{Y}\), then \(\mathcal{Z}\) is basically absorbed into the error so would be correlated with it. With the direct path from \(\mathcal{Z}\) to \(\mathcal{Y}\) not allowed, we are left with only its influence on \(\mathcal{X}\) .
Such models were commonly fit with a technique known two-stage least squares, which is demonstrated here. I use a subset of the CigarettesSW data set and ivreg function from the AER package for comparison. The data concerns cigarette consumption for the 48 continental US States from 1985–1995, though only the last year is used for our purposes. Here we examine the effect on packs per capita (packs) of price (rprice), using state level income (rincome) as the instrumental variable. See the help file for the CigarettesSW for more on this data.
state rprice rincome tdiff tax cpi packs year
1 AL 103.9182 12.91535 0.9216975 40.50000 1.524 101.08543 1995
2 AR 115.1854 12.16907 5.4850193 55.50000 1.524 111.04297 1995
3 AZ 130.3199 13.53964 6.2057067 65.33333 1.524 71.95417 1995
4 CA 138.1264 16.07359 9.0363074 61.00000 1.524 56.85931 1995
5 CO 109.8097 16.31556 0.0000000 44.00000 1.524 82.58292 1995
6 CT 143.2287 20.96236 8.1072834 74.00000 1.524 79.47219 1995# explicit 2sls
mod0 = lm(rprice ~ rincome , data = Cigarettes)
lm(packs ~ fitted(mod0), data = Cigarettes)
Call:
lm(formula = packs ~ fitted(mod0), data = Cigarettes)
Coefficients:
(Intercept) fitted(mod0)
7.919 -0.707
Call:
AER::ivreg(formula = packs ~ rprice | rincome, data = Cigarettes)
Residuals:
Min 1Q Median 3Q Max
-0.64455 -0.08910 0.01721 0.11352 0.45742
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.9191 2.0819 3.804 0.000419 ***
rprice -0.7070 0.4354 -1.624 0.111265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2006 on 46 degrees of freedom
Multiple R-Squared: 0.3351, Adjusted R-squared: 0.3207
Wald test: 2.637 on 1 and 46 DF, p-value: 0.1113 We can see that these both produce the same results, though actually doing the piecemeal regression would lead to problematic standard errors. However, by using the fitted values from the regression of \(\mathcal{X}\) on \(\mathcal{Z}\), we are now able to essentially get the effect of \(\mathcal{X}\) untainted by \(\mathcal{U}\). To see more clearly where the effect comes from, the coefficient of regressing packs on income is -0.347, and dividing that by the coefficient of price on income, 0.492, will provide the ultimate effect of price on the pack of cigarettes that we see above.
We can run the path model in lavaan as well. Note the slight difference between what we’d normally code up for a path model. In order to get the same results as instrumental variable regression, we have to explicitly add an estimate of the packs disturbance with price.
mod = '
packs ~ rprice
rprice ~ rincome
packs ~~ rprice
'
modiv = sem(mod, data=Ciglog, meanstructure = T, se = 'robust')
summary(modiv)lavaan 0.6-2 ended normally after 49 iterations
Optimization method NLMINB
Number of free parameters 7
Number of observations 48
Estimator ML
Model Fit Test Statistic 0.000
Degrees of freedom 0
Minimum Function Value 0.0000000000000
Parameter Estimates:
Information Expected
Information saturated (h1) model Structured
Standard Errors Robust.sem
Regressions:
Estimate Std.Err z-value P(>|z|)
packs ~
rprice -0.707 0.427 -1.655 0.098
rprice ~
rincome 0.492 0.083 5.899 0.000
Covariances:
Estimate Std.Err z-value P(>|z|)
.packs ~~
.rprice -0.008 0.006 -1.290 0.197
Intercepts:
Estimate Std.Err z-value P(>|z|)
.packs 7.919 2.053 3.857 0.000
.rprice 3.464 0.221 15.695 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.packs 0.039 0.015 2.541 0.011
.rprice 0.012 0.002 6.028 0.000While instrumental variable regression is common, this is perhaps not a typical path model seen in SEM. With SEM, a model comparison approach might be taken to compare models of competing complexity. One issue not discussed is where instruments come from. Generally data is not collected with acquiring them in mind, so it might be very difficult to use such an analysis. Furthermore, the structured causal framework that includes SEM would generally be a more flexible approach.
Heckman Selection Model
A different kind of instrumental variable model comes into play with sample selection models. Very common in econometrics or those exposed to it, and practically nowhere else, in this situation, our dependent variable is censored in some fashion, such that we only observe some the population. The classic, and evidently only, textbook example you’ll find on this regards the wages of working women. Here is the description from the Stata manual.
In one classic example, the first equation describes the wages of women. Women choose whether to work, and thus, from our point of view as researchers, whether we observe their wages in our data. If women made this decision randomly, we could ignore that not all wages are observed and use ordinary regression to fit a wage model. Such an assumption of random participation, however, is unlikely to be true; women who would have low wages may be unlikely to choose to work, and thus the sample of observed wages is biased upward. In the jargon of economics, women choose not to work when their personal reservation wage is greater than the wage offered by employers. Thus women who choose not to work might have even higher offer wages than those who do work—they may have high offer wages, but they have even higher reservation wages. We could tell a story that competency is related to wages, but competency is rewarded more at home than in the labor force.
So the primary problem here again is bias. Now you may say- but I’m not interested in the generalizing to all women22, or, if I were really worried about exact inference there are a whole host of other things being ignored, but the economists will have none of it23. Conceptually, the model is as follows:
\[ y = X\beta + \epsilon\] \[\mathrm{observed} = Z\gamma + \nu\] \[\begin{pmatrix} \epsilon \\ \nu \end{pmatrix} \sim N\begin{bmatrix} \begin{pmatrix} 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma & \rho\\ \rho & 1 \end{pmatrix}\end{bmatrix}\]
There are actually two models to consider- one that we care about, and one regarding whether we observe the target variable \(y\) or not. As before, we have the correlated errors issue, and, as with instrumental variable regression, we can take a two step approach here, albeit a bit differently. In the one model, we will predict whether the data is observed or not using a probit model. Then we’ll use a variable based on the fits from that model in the next step. Note these are not the fitted values, but the inverse Mills ratio, or in survival model lingo, the nonselection hazard, based on them. I show results using the sampleSelection package, and how to duplicate the process with standard R model functions.
wages = haven::read_dta('data/heckman_women.dta')
library(sampleSelection)
wages$select_outcome = factor(!is.na(wages$wage), labels=c('not', 'observed'))
selection_model = selection(select_outcome ~ married + children + education + age,
wage ~ education + age,
data=wages, method='2step')
summary(selection_model)--------------------------------------------
Tobit 2 model (sample selection model)
2-step Heckman / heckit estimation
2000 observations (657 censored and 1343 observed)
11 free parameters (df = 1990)
Probit selection equation:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.467365 0.192563 -12.813 < 2e-16 ***
married 0.430857 0.074208 5.806 7.43e-09 ***
children 0.447325 0.028742 15.564 < 2e-16 ***
education 0.058365 0.010974 5.318 1.16e-07 ***
age 0.034721 0.004229 8.210 3.94e-16 ***
Outcome equation:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.73404 1.24833 0.588 0.557
education 0.98253 0.05388 18.235 <2e-16 ***
age 0.21187 0.02205 9.608 <2e-16 ***
Multiple R-Squared:0.2793, Adjusted R-Squared:0.2777
Error terms:
Estimate Std. Error t value Pr(>|t|)
invMillsRatio 4.0016 0.6065 6.597 5.35e-11 ***
sigma 5.9474 NA NA NA
rho 0.6728 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
--------------------------------------------# probit model
probit = glm(select_outcome ~ married + children + education + age,
data=wages,
family=binomial(link = 'probit'))
# setup for wage model
probit_lp = predict(probit)
mills0 = dnorm(probit_lp)/pnorm(probit_lp)
imr = mills0[wages$select_outcome=='observed']
lm_select = lm(wage ~ education + age + imr, data=filter(wages, select_outcome=='observed'))
summary(probit)
Call:
glm(formula = select_outcome ~ married + children + education +
age, family = binomial(link = "probit"), data = wages)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.7594 -0.9414 0.4552 0.8459 2.0427
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.467365 0.192291 -12.831 < 2e-16 ***
married 0.430857 0.074310 5.798 6.71e-09 ***
children 0.447325 0.028642 15.618 < 2e-16 ***
education 0.058365 0.011018 5.297 1.18e-07 ***
age 0.034721 0.004232 8.204 2.33e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 2532.4 on 1999 degrees of freedom
Residual deviance: 2054.1 on 1995 degrees of freedom
AIC: 2064.1
Number of Fisher Scoring iterations: 5
Call:
lm(formula = wage ~ education + age + imr, data = filter(wages,
select_outcome == "observed"))
Residuals:
Min 1Q Median 3Q Max
-15.4167 -3.5143 -0.1737 3.5506 20.3762
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.73404 1.16621 0.629 0.529
education 0.98253 0.05050 19.457 < 2e-16 ***
age 0.21187 0.02066 10.253 < 2e-16 ***
imr 4.00162 0.57710 6.934 6.35e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.359 on 1339 degrees of freedom
Multiple R-squared: 0.2793, Adjusted R-squared: 0.2777
F-statistic: 173 on 3 and 1339 DF, p-value: < 2.2e-16Dividing the coefficient for imr by \(\sigma\) will give you a rough estimate of \(\rho\), but the \(\sigma\) from the package results is the lm sigma plus an extra component, so the rough estimate of \(\rho\) from just the lm results will be a bit larger.
Unfortunately there isn’t a real good way to formulate this in SEM. Conceptually it’s still an instrumental variable type of model, but the complete separation of the data, where part of the model only exists for one category means that standard approaches won’t estimate it. Probably a good thing in the end. You could however estimate the IMR, and do the second step only using robust standard errors. It still won’t be exactly the same as the sampleSelection result, but close. If you’d like to see more detail, check this out.
Aside: Nonrecursive Models
Recursive models have all unidirectional causal effects and disturbances are not correlated. A model is considered nonrecursive if there is a reciprocal relationship, feedback loop, or correlated disturbance in the model24. Nonrecursive models are potentially problematic when there is not enough information to estimate the model (unidentified model), which is a common concern with them.
A classic example of a nonrecursive relationship is marital satisfaction: the more satisfied one partner is, the more satisfied the other, and vice versa (at least that’s the theory). This can be represented by a simple model (below).
Such models are notoriously difficult to specify in terms of identification, which we will talk more about later. For now, we can simply say the above model would not even be estimated as there are more parameters to estimate (two paths, two variances) than there is information in the data (two variances and one covariance).
To make this model identified, we use instrumental variables as we did before. In this scenario, instrumental variables directly influence one of the variables in a recursive relationship, but not the other. For example, a wife’s education can influence her satisfaction directly and a husband’s education can influence his satisfaction directly, but a husband’s education cannot directly impact a wife’s satisfaction and vice versa (at least for this demonstration). These instrumental variables can indirectly impact a spouses’ satisfaction. In the following model family income is also included. The dashed line represents an unanalyzed correlation.
Many instances of nonrecursive models might better be represented by a correlation. One must have a very strong theoretical motivation for such models, which is probably why they aren’t seen as often in the SEM literature, though they are actually quite common in some areas such as economics, where theory is assumed to be stronger (by economists).
Aside: Tracing rule
In a recursive model, implied correlations between two variables, X1 and X2, can be found using tracing rules. Implied correlations between variables in a model are equal to the sum of the product of all standardized coefficients for the paths between them. Valid tracings are all routes between X1 and X2 that a) do not enter the same variable twice, and b) do not enter a variable through an arrowhead and leave through an arrowhead. The following examples assume the variables have been standardized (variance values equal to 1), if standardization has not occurred the variance of variables passed through should be included in the product of tracings.
Consider the following variables, A, B, and C (in a data frame called abc) with a model seen in the below diagram. We are interested in identifying the implied correlation between x and z by decomposing the relationship into its different components and using tracing rules.
A B C
A 1.0 0.2 0.3
B 0.2 1.0 0.7
C 0.3 0.7 1.0 C~B C~A B~A C~~C B~~B
0.667 0.167 0.200 0.478 0.950 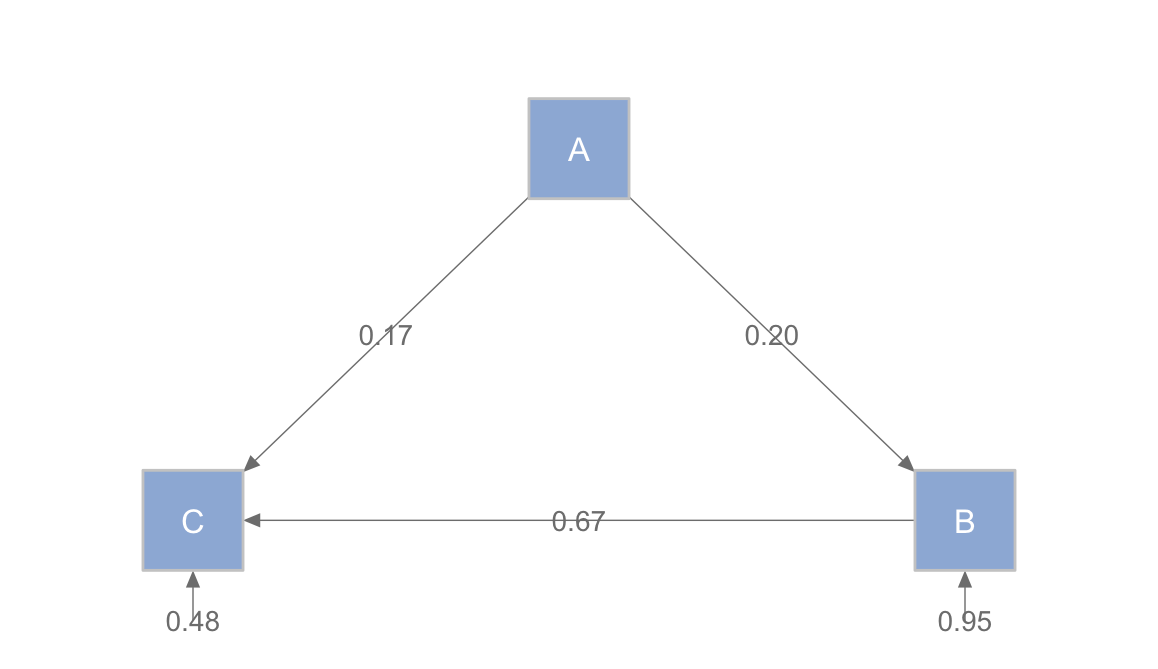
To reproduce the correlation between A and C (sometimes referred to as a ‘total effect’):
- Corr = ac + ab * ac
- Corr = 0.667 + 0.033
- Corr = 0.7
In SEM models, it’s important to consider how well our model-implied correlations correspond to the actual observed correlations. For over-identified models, the correlations will not be reproduced exactly, and thus can serve as a measure of how well our model fits the data. We’ll discuss this more later. In addition, the tracing of paths is important in understanding the structural causal models approach of Judea Pearl, of which SEM and the potential outcomes framework are part of.
Bayesian Networks
In many cases of path analysis, the path model is not strongly supported by prior research or intuition, and in other cases, people are willing to use modification indices after the fact to change the paths in their model. This is unfortunate, as their model is generally overfit to begin with, and more so if altered in such an ad hoc fashion.
A more exploratory approach to graphical models is available however. Bayesian Networks, an approach within Pearl’s structural causal model framework and which led to its development, are an alternative to graphical modeling of the sort we’ve been doing. Though they can be used to produce exactly the same results that we obtain with path analysis via maximum likelihood estimation, they can also be used for constrained or wholly exploratory endeavors as well, potentially with regularization in place to help reduce overfitting.
As an example, I use the McClelland data to explore potential paths via the bnlearn package. I make the constraints that variables later in time do not effect variables earlier in time25, no variables are directed toward background characteristics like sex, and at least for these purposes I keep math and reading at a particular time from having paths to each other. I show some of the so-called blacklist of constraints here. Note that we can also require certain paths be in the model via a whitelist.
from to
1 read21 read7
2 read21 math7
3 read21 attention4
4 read21 vocab4
5 read21 adopted
6 read21 maleNow we can run the model. In this case we’ll use the Grow-Shrink algorithm, which is one of the simpler available in the package, though others came to the same conclusion26.
The plot of the model results shows that attention span at age 4 has no useful relationship to the other variables, something we’d already suspected based on previous models, and even could guess at the outset given its low correlations. As it has no connections, I’ve dropped it from the visualization. Furthermore, the remaining paths make conceptual sense. The parameters, fitted values, and residuals can be extracted with the bn.fit function, and other diagnostic plots, cross-validation and prediction on new data are also available.
We won’t get into the details of these models except to say that one should have them in their tool box. And if one really is in a more exploratory situation, they would typically come with methods far better suited for the situation than the SEM tools, none of which I come across consider predictive ability very strongly. The discovery process with Bayesian networks can also be a lot of fun. Even if one has strong theory, nature is always more clever than we are, and you might find something interesting. See also the bnpa, autoSEM, and regsem packages for more.
Undirected Graphs
So far we have been discussing directed graphs in which the implied causal flow tends toward one direction and there are no feedback loops. However, sometimes the goal is not so much to estimate the paths as it is to find the structure. Undirected graphs simply specify the relations of nodes with edges, but without any directed arrows regarding the relationship. Such graphs are sometimes called Markov Random Fields.
While we could have used the bnlearn package for an undirected graph by adding the argument undirected = T, there are a slew of techniques available for what is often called network analysis. Often the focus is on observations, rather than variables, and what influences whether one sees a tie/edge between nodes, with modeling techniques available for predicting ties (e.g. Exponential Random Graph models). Often these are undirected graphs, and that is our focus here, but they do not have to be.
Network analysis
Networks can be seen everywhere. Personal relationships, machines and devices, various business and academic units… we can analyze the connections among any number of things. A starting point for a very common form of network analysis is an adjacency matrix, which represents connections among items we wish to analyze. Often it contains just binary 0-1 values where 1 represents a connection between nodes. Any similarity matrix could potentially be used (e.g. a correlation matrix). Here is a simple example of an adjacency matrix:
| Bernadette | David | J’Sean | Lagia | Mancel | Nancy | |
|---|---|---|---|---|---|---|
| Bernadette | 1 | 0 | 1 | 1 | 1 | 1 |
| David | 0 | 1 | 1 | 0 | 0 | 1 |
| J’Sean | 1 | 1 | 1 | 0 | 1 | 0 |
| Lagia | 1 | 0 | 0 | 1 | 0 | 1 |
| Mancel | 1 | 0 | 1 | 0 | 1 | 0 |
| Nancy | 1 | 1 | 0 | 1 | 0 | 1 |
Visually, we can see the connections among the nodes.
As an example of a network analysis, let’s look at how states might be more or less similar on a few variables. We’ll use the state.x77 data set in base R. It is readily available, no need for loading. To practice your R skills, use the function str on the state.x77 object to examine its structure, and head to see the first 6 rows, and ? to find out more about it.
Here are the correlations of the variables.
The following depicts a graph of the states based on the variables of Life Expectancy, Median Income, High School Graduation Rate, and Illiteracy. The colors represent the results of a community detection algorithm, and serve to show that the clustering is not merely geographical, though one cluster is clearly geographically oriented (‘the South’).
Understanding Networks
Networks can be investigated in an exploratory fashion or lead to more serious modeling approaches. The following is a brief list of common statistics or modeling techniques.
Centrality
- Degree: how many links a node has (can also be ‘in-degree’ or ‘out-degree’ for directed graphs)
- Closeness: how close a node is to other nodes
- Betweenness: how often a node serves as a bridge between the shortest path between two other nodes
- PageRank: From Google, a measure of node ‘importance’
- Hub: a measure of the value of a node’s links
- Authority: another measure of node importance
Characteristics of the network as a whole may also be examined, e.g. degree distribution, ‘clusteriness’, average path length etc.
Cohesion
One may wish to investigate how network members create communities and cliques. This is similar to standard cluster analysis used in other situations. Some nodes may be isolated.
Modeling
- ERGM: exponential random graph models, regression modeling for network data
- Other ‘link’ analysis
Comparison
A goal might be to compare multiple networks to see if they differ in significant ways.
Dynamics
While many networks are ‘static’, many others change over time. One might be interested in this structural change by itself, or modeling something like link loss. See the ndtv package for some nice visualization of such approaches.
Summary
Graphical models are a general way to formulate and visualize statistical models. All statistical models can be developed within this framework. Structured causal models provide a means to posit causal thinking with graphical models, and structural equation models may be seen as a subset of those. Path analysis within SEM is a form of theoretically motivated graphical model involving only observed variables. These models might include indirect effects and multiple outcomes of interest, and can be seen as an extension of more familiar regression models to such settings. However, path analysis is just one of a broad set of graphical modeling tools widely used in many disciplines, any of which might be useful for a particular data situation.
R packages used
- lavaan
- mediation
- bnlearn
- network
There are other assumptions at work also, e.g. that the model is correct and there are no other confounders.↩
Sewall Wright first used path analysis almost 100 years ago.↩
I use multivariate here to refer to multiple dependent variables, consistent with multivariate analysis generally. Some use it to mean multiple predictors, but since you’re not going to see single predictor regression outside of an introductory statistical text, there is no reason to distinguish it. Same goes for multiple regression.↩
Note this is just a syntax shortcut to running multiple models, not an actual ‘multivariate’ analysis.↩
In the past people would run separate OLS regressions to estimate mediation models, particularly for the most simple, three variable case. One paper that for whatever reason will not stop being cited is Baron & Kenny 1986. It was 1986. Please do not do mediation models like this. You will always have more than three variables to consider, and always have access to R or other software that can estimate the model appropriately. While I think it is very helpful to estimate your models in piecemeal fashion for debugging purposes and to facilitate your understanding, use appropriate tools for the model you wish to estimate. Some packages, such as mediate, may still require separate models, but there is far more going on ‘under the hood’ even then. For more recent work in this area, see the efforts of Pearl and Imai especially.↩
I’ve seen some balk at this sort of description, but the fact remains that SEM does not have any more tie to causality than any other statistical tool, other than what applied researchers ascribe to their results. As mentioned before, SEM does not discover causality or allow one to make causal statements simply by conducting it. It’s just a statistical model.↩
I suspect this is likely the case for the majority of modeling scenarios in social sciences that are often dealing with fairly weak effects, where the additional complexity would typically not result in better predictive value.↩
There is a statement “All results controlled for background covariates of vocabulary at age 4, gender, adoption status, and maternal education level.” and a picture of only the three-variable mediation model. If you are surprised at this lack of information, you may not be familiar with the field of psychological research.↩
The historical reference for this approach is with Rubin and even earlier with Neyman. Some may make the distinction between potential outcomes, which are potentially observable for everyone, and counterfactuals that are inherently unobservable.↩
In general, the recommendation is to use bootstrap estimates for the indirect effect interval estimate anyway.↩
Pearl devised a do operator, e.g. \(p(y|\textrm{do}(\mathcal{X}))\), where given some model, we can assess results as if ‘\(\mathcal{X}\) had been \(x_0\)’, i.e. holding \(\mathcal{X}\) at some value. The gist is that taking the appropriate modeling steps will allow us to investigate questions such as ‘if X had been something else’, i.e. a counterfactual.↩
Bollen & Pearl (2013) list myth #2 about SEM is that SEM and regression are essentially equivalent. While I agree that we can think of them differently, I don’t find their exposition very persuasive. Their explanation of a structural model is no different than what you see for standard regression in econometrics and more rigorous statistics books. It’s not clear to me where they think a ‘residual’ in regression comes from if not from ‘unexplained causes’ not included in the model (I actually prefer stating regression models as \(y \sim \mathcal{N}(X\beta, \sigma^2)\) so as to make the data generating process explicit, a point mostly ignored in SEM depictions). Changing to ‘equals’ (=) to ‘assignment’ (:=) in the equation doesn’t work if you consider that most programming languages use = for assignment. Adding a picture certainly doesn’t change things, and as a consultant, I can say that expressing a model graphically first doesn’t keep people from positing models that are very problematic from a causal perspective (and may actually encourage it).
The gist is that causality is something the researcher, not the data or the model, brings to the scientific table in an explicit fashion, something Bollen & Pearl even state clearly in their discussion of the first myth (that SEM aims to establish causal relations from correlations). Practically speaking, an SEM will produce exactly the same output whether you have strong causal claims or not.↩As an example, see if you can think of a situation in which an interaction between two variables on some outcome, which technically represents a difference in coefficient values, would only exist indirectly. Also realize that simply positing such a situation for two variables would mean you’d have to rule out several competing models of all possible direct and indirect paths between A, B, and their product term. Just for giggles you might also consider that either A or B might have more than two categories, and so must be represented by multiple dummy coded variables and multiple interaction terms. Have fun!↩
Kline distinguishes indirect effects vs. mediation. I don’t, because I don’t believe SEM to have any inherently greater ability to discern causality than any other framework, and it doesn’t. I do like his suggestion that mediation be reserved for effects involving time precedence, and defaulting to ‘indirect effects’ should keep you out of trouble. But even then, and as physics dictates, the arrow of time is inconsequential on a macro level. All else being equal, your model will fit as well with time 2 \(\rightarrow\) time 1 as time 2 \(\leftarrow\) time 1.↩
Along with the notion of buffering, which is a near useless term in my opinion.↩
See for example, Wu & Zumbo (2008) Understanding and using mediators and moderators. (link)↩
Unless you want to signal to people who are statistically knowledgeable that they should stop paying attention to your work. In general, it’s probably best to avoid using the applied literature as a basis for how to conduct or report methods. While excellent examples may be found, many fields have typically ignored their own quantitative methodologists and statisticians for decades. Psychology is rather notorious in this regard, while I might point to political science as a counter example, in the sense that the latter has long had one of its most popular journals a methodological one.↩
In Pearl’s language, Z is d-separated from Y if the X -> Y path is removed, but not d-separated from X. The d stands for directional.↩
Some of this example comes from Cameron and Trivedi’s Microeconometrics, which has a pretty clean (in my opinion) depiction of instrumental variable analysis.↩
I’m curious how common it is that you would have enough fully complete X, but no Y to even model the missingness. The usual situation I see is either complete missingness or, far more commonly, missingness all over the data, which means you’d have to model the missingness in X in order to model they Y. In other words, you’d have a general missingness problem to consider to even be able to do the initial probit model. Stuff like this seems endemic to instrumental variable analysis. In the standard IV model, it’s all well and good, if you have an instrument. But as previously mentioned, no one collects data thinking about getting some instrumental variables just in case, and if you don’t get it right, which is impossible to tell, you’ve likely opened up any number of back doors in a causal sense. And if you think economists have it all figured out, do a search on ‘rainfall’ ‘tv’ and ‘autism’, or perhaps just use common sense and know those three things should not go together in a model.↩
Economists are like Vogons. They do good work, efficient, consistent, and without bias, but in the end no one wants anything to do with their poetry.↩
No, ‘non’-recursive as a name for these models makes no sense to me either.↩
Note that if this approach were able to uncover causal relations via statistical means, a blacklist would not be necessary. If you actually tried it here, you’d find adoption status influenced by early adult scholastic abilities.↩
I have no bone to pick nor know the authors, but after seeing the models thus far, at this point I have to question the major conclusion of the McClelland et al. paper, which focuses on the effects of attention span on these outcomes, and concludes the indirect effects are notable and that there is a noteworthy direct effect on math at age 21. To begin, the attention span variable starts with no strong linear correlation with either outcome. They admit no direct effect on reading, but then suggest there is still an indirect effect even though it is practically zero and the bulk of it clearly is the read7 \(\rightarrow\) read21 path. If demographics only predict read21 (again this isn’t clear from their paper, but such a model does duplicate the few values they actually report), then the R2 for read7 is ~ 1.6%. Thus I can’t think of any way to conclude a direct or indirect effect of attention span at age 4 on reading at 21. The math results are only marginally better, but even there the internal fit indices are poor (e.g. RMSEA etc.). Had a model comparison approach been used, AIC would not have chosen the mediation model in either case.
In general, if the path from a variable to a potential mediator is essentially zero to begin with, save yourself some trouble- there is no reason to test for indirect effects (zero times any value is still zero).↩