Part of Speech Tagging
As an initial review of parts of speech, if you need a refresher, the following Schoolhouse Rocks videos should get you squared away:
- A noun is a person, place, or thing.
- Interjections
- Pronouns
- Verbs
- Unpack your adjectives
- Lolly Lolly Lolly Get Your Adverbs Here
- Conjunction Junction (personal fave)
Aside from those, you can also learn how bills get passed, about being a victim of gravity, a comparison of the decimal to other numeric systems used by alien species (I recommend the Chavez remix), and a host of other useful things.
Basic idea
With part-of-speech tagging, we classify a word with its corresponding part of speech. The following provides an example.
| JJ | JJ | NNS | VBP | RB |
| Colorless | green | ideas | sleep | furiously. |
We have two adjectives (JJ), a plural noun (NNS), a verb (VBP), and an adverb (RB).
Common analysis may then be used to predict POS given the current state of the text, comparing the grammar of different texts, human-computer interaction, or translation from one language to another. In addition, using POS information would make for richer sentiment analysis as well.
POS Examples
The following approach to POS-tagging is very similar to what we did for sentiment analysis as depicted previously. We have a POS dictionary, and can use an inner join to attach the words to their POS. Unfortunately, this approach is unrealistically simplistic, as additional steps would need to be taken to ensure words are correctly classified. For example, without more information, we are unable to tell if some words are being used as nouns or verbs (human being vs. being a problematic part of speech). However, this example can serve as a starting point.
Barthelme & Carver
In the following we’ll compare three texts from Donald Barthelme:
- The Balloon
- The First Thing The Baby Did Wrong
- Some Of Us Had Been Threatening Our Friend Colby
As another comparison, I’ve included Raymond Carver’s What we talk about when we talk about love, the unedited version. First we’ll load an unnested object from the sentiment analysis, the barth object. Then for each work we create a sentence id, unnest the data to words, join the POS data, then create counts/proportions for each POS.
load('data/barth_sentences.RData')
barthelme_pos = barth %>%
mutate(work = str_replace(work, '.txt', '')) %>% # remove file extension
group_by(work) %>%
mutate(sentence_id = 1:n()) %>% # create a sentence id
unnest_tokens(word, sentence, drop=F) %>% # get words
inner_join(parts_of_speech) %>% # join POS
count(pos) %>% # count
mutate(prop=n/sum(n))Next we read in and process the Carver text in the same manner.
carver_pos =
data_frame(file = dir('data/texts_raw/carver/', full.names = TRUE)) %>%
mutate(text = map(file, read_lines)) %>%
transmute(work = basename(file), text) %>%
unnest(text) %>%
unnest_tokens(word, text, token='words') %>%
inner_join(parts_of_speech) %>%
count(pos) %>%
mutate(work='love',
prop=n/sum(n))This visualization depicts the proportion of occurrence for each part of speech across the works. It would appear Barthelme is fairly consistent, and also that relative to the Barthelme texts, Carver preferred nouns and pronouns.
More taggin’
More sophisticated POS tagging would require the context of the sentence structure. Luckily there are tools to help with that here, in particular via the openNLP package. In addition, it will require a certain language model to be installed (English is only one of many available). I don’t recommend doing so unless you are really interested in this (the openNLPmodels.en package is fairly large).
We’ll reexamine the Barthelme texts above with this more involved approach. Initially we’ll need to get the English-based tagger we need and load the libraries.
# install.packages("openNLPmodels.en", repos = "http://datacube.wu.ac.at/", type = "source")
library(NLP)
library(tm) # make sure to load this prior to openNLP
library(openNLP)
library(openNLPmodels.en)Next comes the processing. This more or less follows the help file example for ?Maxent_POS_Tag_Annotator. Given the several steps involved I show only the processing for one text for clarity. Ideally you’d write a function, and use a group_by approach, to process each of the texts of interest.
load('data/barthelme_start.RData')
baby_string0 = barth0 %>%
filter(id=='baby.txt')
baby_string = unlist(baby_string0$text) %>%
paste(collapse=' ') %>%
as.String
init_s_w = annotate(baby_string, list(Maxent_Sent_Token_Annotator(),
Maxent_Word_Token_Annotator()))
pos_res = annotate(baby_string, Maxent_POS_Tag_Annotator(), init_s_w)
word_subset = subset(pos_res, type=='word')
tags = sapply(word_subset$features , '[[', "POS")
baby_pos = data_frame(word=baby_string[word_subset], pos=tags) %>%
filter(!str_detect(pos, pattern='[[:punct:]]'))Let’s take a look. I’ve also done the other Barthelme texts as well for comparison.
| word | pos | text |
|---|---|---|
| The | DT | baby |
| first | JJ | baby |
| thing | NN | baby |
| the | DT | baby |
| baby | NN | baby |
| did | VBD | baby |
| wrong | JJ | baby |
| was | VBD | baby |
| to | TO | baby |
| tear | VB | baby |
| pages | NNS | baby |
| out | IN | baby |
| of | IN | baby |
| her | PRP$ | baby |
| books | NNS | baby |
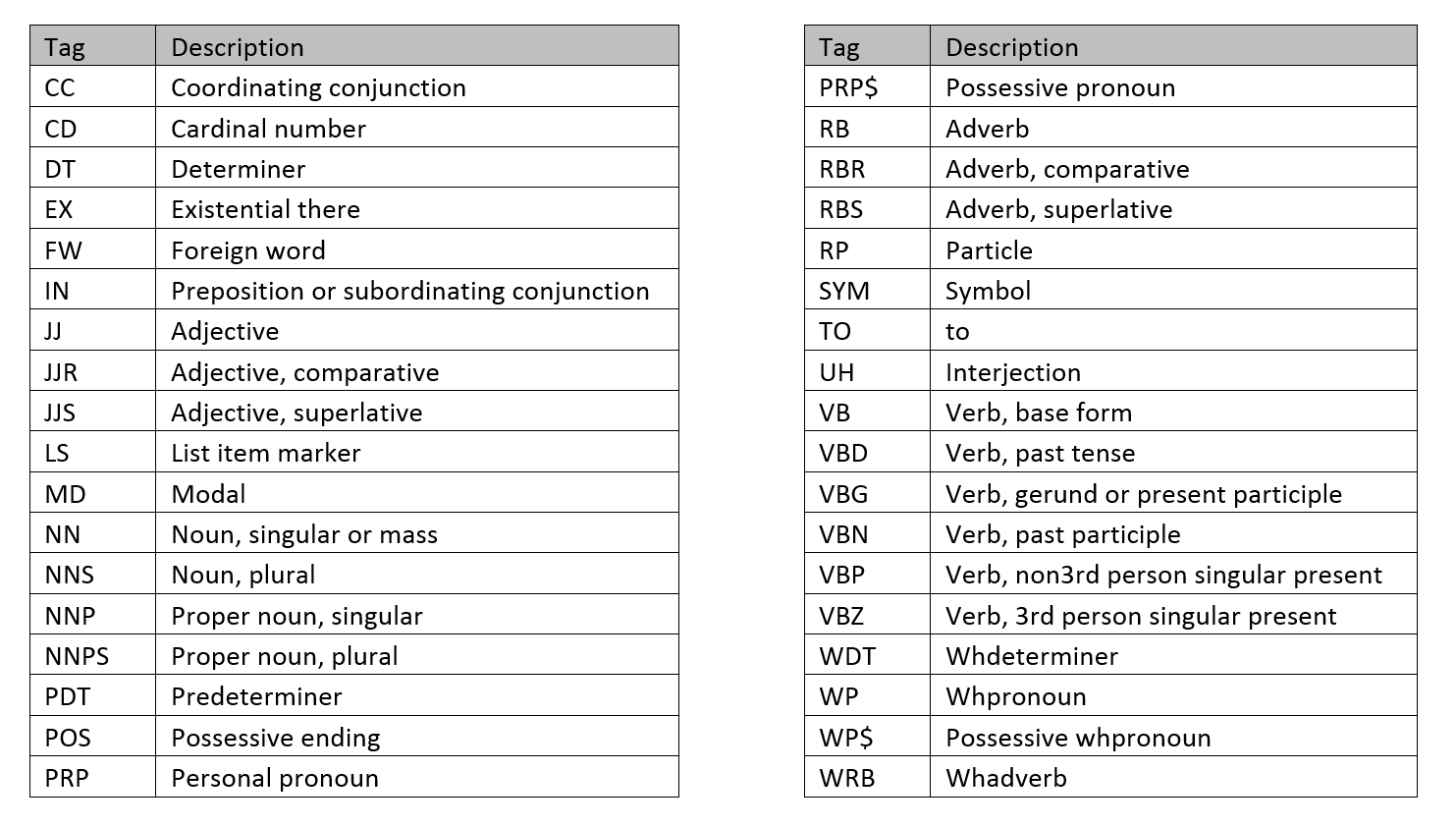
As we can see, we have quite a few more POS to deal with here. They come from the Penn Treebank. The following table notes what the acronyms stand for. I don’t pretend to know all the facets to this.
Plotting the differences, we now see a little more distinction between The Balloon and the other two texts. It is more likely to use the determiners, adjectives, singular nouns, and less likely to use personal pronouns and verbs (including past tense).
Tagging summary
For more information, consult the following:
As with the sentiment analysis demos, the above should be seen only starting point for getting a sense of what you’re dealing with. The ‘maximum entropy’ approach is just one way to go about things. Other models include hidden Markov models, conditional random fields, and more recently, deep learning techniques. Goals might include text prediction (i.e. the thing your phone always gets wrong), translation, and more.
POS Exercise
As this is a more involved sort of analysis, if nothing else in terms of the tools required, as an exercise I would suggest starting with a cleaned text, and seeing if the above code in the last example can get you to the result of having parsed text. Otherwise, assuming you’ve downloaded the appropriate packages, feel free to play around with some strings of your choosing as follows.