| Target | Feature | Change in X | Change in Y | Benefits |
|---|---|---|---|---|
| y | x | 1 unit | B unit | Interpretation |
| log(y) | x | 1 unit | 100 * (exp(B) -1)% | Heteroscedasticity in y |
| log(y) | log(x) | 1% change | B% | Interpretation, help with feature extremes |
| y | scale(x) | 1 standard deviation | B unit | Interpretation, estimation |
| scale(y) | scale(x) | 1 standard deviation | B standard deviation | Interpretation, estimation |
14 Dealing with Data
It’s an inescapable fact that models need data to work. One of the dirty secrets in data science is that getting the data right will do more for your model than any fancy algorithm or hyperparameter tuning. Data is messy, and there are a lot of ways it can be messy. In addition, dealing with a target variable on its terms can lead to more interesting results. In this chapter we’ll discuss some of the most common data issues and things to consider. There’s a lot to know about data before you ever get into modeling it, so we’ll give you some things to think about in this chapter.
14.1 Key Ideas
- Data transformations can provide many modeling benefits.
- Label and text-based data still needs a numeric representation, and this can be accomplished in a variety of ways.
- The data type for the target may suggest a particular model but does not necessitate one.
- The data structure, for example, temporal, spatial, censored, etc., may suggest a particular modeling domain to use.
- Missing data can be handled in a variety of ways, and the simpler approaches are typically not great.
- Class imbalance is a very common issue in classification problems, and there are a number of ways to deal with it.
- Latent variables are everywhere!
14.1.1 Why this matters
Knowing your data is one of the most important aspects of any application of data science. It’s not just about knowing what you have, but also what you can do with it. The data you have will influence the models you can potentially use, the features you can create and manipulate, and have a say on the results you can expect.
14.1.2 Helpful context
We’re talking very generally about data here, so not much background is needed. The models mentioned here are covered in other chapters, or build upon those, but we’re not doing any actual modeling here.
14.2 Feature and Target Transformations
Transforming variables from one form to another provides several benefits in modeling, whether applied to the target, features, or both. Transformation should be used in most model situations. Just some of these benefits include:
- More comparable feature effects and related parameters
- Faster estimation
- Easier convergence
- Helping with heteroscedasticity
For example, just centering features, i.e., subtracting their respective means, provides a more interpretable intercept that will fall within the actual range of the target variable in a standard linear regression. After centering, the intercept tells us what the value of the target variable is when the features are at their means (or reference value if categorical). Centering also puts the intercept within the expected range of the target, which often makes for easier parameter estimation. So even if easier interpretation isn’t a major concern, variable transformations can help with convergence and speed up estimation, so can always be of benefit.
14.2.1 Numeric variables
The following table shows the interpretation of some very common transformations applied to numeric variables: logging, and standardizing to mean zero, standard deviation of one1. Note that for logging, these are approximate interpretations.
For example, it is very common to use standardized or scaled variables. Some also call this normalizing, as with batch or layer normalization in deep learning, but this term can mean a lot of things, so one should be clear in their communication. If \(y\) and \(x\) are both standardized, a one-unit (i.e., one standard deviation) change in \(x\) leads to a \(\beta\) standard deviation change in \(y\). So, if \(\beta\) was .5, a standard deviation change in \(x\) leads to a half standard deviation change in \(y\). In general, there is nothing to lose by standardizing, so you should employ it often.
Another common transformation, particularly in machine learning, is min-max scaling. This involves changing variables to range from a chosen minimum value to a chosen maximum value, and usually this means zero and one respectively. This transformation can make numeric and categorical indicators more comparable, or at least put them on the same scale for estimation purposes, and so can help with convergence and speed up estimation. The following demonstrates how we can employ such approaches.
When using sklearn, it’s a bit of a verbose process to do such a simple transformation. However, it is beneficial when you want to do more complicated things, especially when using data pipelines.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import numpy as np
# Create a random sample of integers
data = np.random.randint(low=0, high=100, size=(5, 3))
# Apply StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
# Apply MinMaxScaler
minmax_scaler = MinMaxScaler()
minmax_scaled_data = minmax_scaler.fit_transform(data)R makes it easy to do simple transformations like standardization and logs without external packages, but you can also use tools like recipes and mlr3 pipeline operations when needed to make sure your preprocessing is applied appropriately.
# Create a sample dataset
data = matrix(sample(1:100, 15), nrow = 5)
# Standardization
scaled_data = scale(data)
# Min-Max Scaling
minmax_scaled_data = apply(data, 2, function(x) {
(x - min(x)) / (max(x) - min(x))
})Using a log transformation for numeric targets and features is straightforward and comes with several benefits. For example, it can help with heteroscedasticity, which is when the variance of the target is not constant across the range of the predictions2. It can also help to keep predictions positive after transformation, allows for interpretability gains, and more.
One issue with logging is that it is not a linear transformation. While this can help capture nonlinear feature-target relationships, it can also make some post-modeling transformations less straightforward. Also if you have a lot of zeros, ‘log plus one’ transformations are not going to be enough to help you overcome that hurdle3. Logging also won’t help much when the variables in question have few distinct values, like ordinal variables, which we’ll discuss later in Section 14.2.3.
14.2.2 Categorical variables
Despite their ubiquity in data, we can’t analyze raw text information as it is. Character strings, and labeled features like factors, must be converted to a numeric representation before we can analyze them. For categorical features, we can use something called effects coding to test for specific types of group differences. Far and away the most common type is called dummy coding or one-hot encoding4, which we visited previously in Section 3.5.2. In these situations we create columns for each category, and the value of the column is 1 if the observation is in that category, and 0 otherwise. Here is a one-hot encoded version of the season feature that was demonstrated previously.
| seasonFall | seasonSpring | seasonSummer | seasonWinter | season |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | Fall |
| 1 | 0 | 0 | 0 | Fall |
| 1 | 0 | 0 | 0 | Fall |
| 1 | 0 | 0 | 0 | Fall |
| 0 | 0 | 1 | 0 | Summer |
| 0 | 0 | 1 | 0 | Summer |
| 1 | 0 | 0 | 0 | Fall |
| 0 | 0 | 1 | 0 | Summer |
| 0 | 0 | 0 | 1 | Winter |
When we encode categories for statistical analysis, we can summarize their impact on the target variable in a single result for all categories. For a model with only categorical features, we can use an ANOVA (Section 3.5.2.1) for this. But a similar approach can also be used for mixed models, splines, and other models to summarize categorical, spline, and other effects. Techniques like SHAP also provide a way to summarize the total effect of a categorical feature (Section 5.7).
14.2.2.1 Text embeddings
When it comes to other string representations like sentences and paragraphs, we can use other methods to represent them numerically. One important way to encode text is through an embedding. This is a way of representing the text as a vector of numbers, at which point the numeric embedding feature is used in the model like any other. The way to do this usually involves a model or a specific part of the model’s architecture, one that learns the best way to represent the text or categories numerically. This is commonly used in deep learning, and natural language processing in particular. However, embeddings can also be used as a preprocessing step in any modeling situation.
To understand how embeddings work, consider a one-hot encoded matrix for a categorical variable. This matrix then connects to a hidden layer of a neural network. The weights learned for that layer are the embeddings for the categorical variable. While this isn’t the exact method used (there are more efficient methods that don’t require the actual matrix), the concept is the same. In addition, we normally don’t even use whole words. Instead, we break the text into smaller units called tokens, like characters or subwords, and then use embeddings for those units. Tokenization is used in many of the most successful models for natural language processing, including those such as ChatGPT.

14.2.2.2 Multiclass targets
We’ve talked about and demonstrated models with binary targets, but what about when there are more than two classes? In statistical settings, we can use a multinomial regression, which is a generalization of (binomial) logistic regression to more than two classes via the multinomial distribution. Depending on the tool, you may have to use a multivariate target of the counts, though most commonly they would be zeros and ones for a classification model, which then is just a one-hot encoded target. The following table demonstrates how this might look.
| x1 | x2 | target | Class A | Class B | Class C |
|---|---|---|---|---|---|
| −1.41 | 6 | A | 1 | 0 | 0 |
| −1.13 | 3 | C | 0 | 0 | 1 |
| 0.70 | 6 | C | 0 | 0 | 1 |
| 0.32 | 8 | B | 0 | 1 | 0 |
| −0.84 | 5 | A | 1 | 0 | 0 |
With Bayesian tools, it’s common to use the categorical distribution, which is a different generalization of the Bernoulli distribution to more than two classes. Unlike the bi/multinomial distribution, it is not a count distribution, but an actual distribution over discrete values.
In the machine learning context, we can use a variety of models we’d use for binary classification. How the model is actually implemented will depend on the tool, but one of the more popular methods is to use one-vs.-all or one-vs.-one strategies, where you treat each class as the target in a binary classification problem. In the first case of one vs. all, you would have a model for each class that predicts whether an observation is in that class versus the other classes. In the second case, you would have a model for each pair of classes. You should generally be careful with either approach if interpretation is important, as it can make the feature effects very difficult to understand. As an example, we can’t expect feature X to have the same effect on the target in a model for class A vs. B, as it does in a model for class A vs. (B & C) or A & C. As such, it can be misleading when the models are conducted as if the categories are independent.
Regardless of the context, interpretation is now spread across multiple target outputs, and so it can be difficult to understand the overall effect of a feature on the target. Even in the statistical model setting (e.g., a multinomial regression), you now have coefficients that regard relative effects for one class versus a reference group, and so they cannot tell you a general effect of a feature on the target. This is where tools like marginal effects and SHAP can be useful (Chapter 5).
14.2.2.3 Multilabel targets
Multilabel targets are a bit more complicated and are not as common as multiclass targets. In this case, each observation can have multiple labels. For example, if we wanted to predict genre based on the movie review data, we could choose to allow a movie to be both a comedy and action film, a sci-fi horror, or a romantic comedy. In this setting, labels are not mutually exclusive. If there are not too many unique label settings, we can treat the target as we would other multiclass targets. But if there are many, we might need to use a different model to go about things more efficiently.
14.2.3 Ordinal variables
So far in our discussion of categorical data, the categories are assumed to have no order. But it’s quite common to have labels like “low”, “medium”, and “high”, or “very bad”, “bad”, “neutral”, “good”, “very good”, or are a few numbers, like ratings from 1 to 5. Ordinal data is categorical data that has a known ordering, but which still has arbitrary labels. Let us repeat that, ordinal data is categorical data.
14.2.3.1 Ordinal features
The simplest way to treat ordinal features is as if they were numeric. If you do this, then you’re just pretending that it’s not categorical. In practice this is usually fine for features. Most of the transformations we mentioned previously aren’t going to be as useful, but you can still use them if you want. For example, logging ratings 1-5 isn’t going to do anything for you model-wise, but it technically doesn’t hurt anything. You should know that typical statistics like means and standard deviations don’t really make sense for ordinal data, so the main reason for treating them as numeric is for modeling convenience.
If you choose to treat an ordinal feature as categorical, you can ignore the ordering and do the same as you would with categorical data. This would allow for some nonlinearity since the category means will be whatever they need to be. There are some specific techniques to coding ordinal data for use in linear models, but they are not commonly used, and they generally aren’t going to help the model performance or interpreting the feature, so we do not recommend them. You could, however, use old-school effects coding that you would incorporate traditional ANOVA models, but again, you’d need a good reason to do so5.
The take-home message for ordinal features is generally simple. Treat them as you would numeric features or non-ordered categorical features. Either is fine.
14.2.3.2 Ordinal targets
Ordinal targets, on the other hand, can be trickier to deal with. If you treat them as numeric, you’re assuming that the difference between 1 and 2 is the same as the difference between 2 and 3, and so on. This is probably not true. You are also ignoring how predictions are bounded by the observed values. If you treat them as categorical and use standard models for that setting, you’re assuming that there is no connection between categories. So what should you do?
There are a number of ways to model ordinal targets, but probably the most common is the proportional odds model. This model can be seen as a generalization of the logistic regression model, and is very similar to it, and actually identical if you only had two categories. It basically is a model of category (2 or higher) vs. category 1, (3 or higher) vs. (2 or 1), etc. Basically you can think of it as subsequent binary model settings, but which you assume the feature effects are constant across settings. But other models beyond proportional odds that relax the assumptions are also possible. As an example, one approach would concern subsequent categories, the 1-2 category change, the 2-3 category change, and so on.
As an example, here are predictions from an ordinal model. In this case, we categorize6 rounded movie ratings as 2 or less (Low), 3 (Average), or 4 or more (High), and predict the probability of each category based on the release year of the movie. So we get three sets of predicted probabilities, one for each category. In this example, we see that the probability of a movie being rated 4 or more has increased over time, while the probability of a movie being rated 2 or less has decreased. The probability of a movie being rated 3 has remained relatively constant, and is most likely.

Ordinality of a categorical outcome is largely ignored in machine learning applications. The outcome is either treated as numeric or multiclass classification. This is not necessarily a bad thing, especially if prediction is the primary goal. But if you need a categorical prediction, treating the target as numeric means you have to make an arbitrary choice to classify the predictions. And if you treat it as multiclass, you’re ignoring the ordinality of the target, which may not work as well in terms of performance.
14.2.3.3 Rank data
Though ranks are ordered, with rank data we are referring to cases where the observations are uniquely ordered. An ordinal vector of 1-6 with numeric labels could be something like [2, 1, 1, 3, 4, 2], where no specific value is required and any value could be repeated. In contrast, rank data would be [2, 1, 3, 4, 5, 6], each being unique (unless you allow for ties). For example, in sports, a ranking problem would regard predicting the actual finish of the runners. Assuming you have a modeling tool that actually handles this situation, the objective will be different from other scenarios. Statistical modeling methods include using the Plackett-Luce distribution (or the simpler variant Bradley-Terry model). In machine learning, you might use so-called learning to rank methods, like the RankNet and LambdaRank algorithms, and other variants for deep learning models.
14.3 Missing Data
| x1 | x2 | x3 |
|---|---|---|
| 4 | 0 | ? |
| 7 | 3 | B |
| ? | 5 | A |
| 8 | ? | B |
| ? | 3 | C |
Missing data is a common challenge in data science, and there are a number of ways to deal with it, usually by substituting, or imputing, the substituted value for the missing one. Here we’ll provide an overview of common techniques to deal with missing data.
14.3.1 Complete case analysis
The first way to deal with missing data is the simplest – complete case analysis. Here we only use observations that have no missing data and drop the rest. Unfortunately, this can lead to a lot of lost data, and it can lead to biased statistical results if the data is not missing completely at random (missingness is not related to the observed or unobserved data). There are special cases of some models that by their nature can ignore the missingness under an assumption of missing at random (missingness is not related to the unobserved data), but even those models would likely benefit from some sort of imputation. If you don’t have much missing data though, dropping the missing data is fine for practical purposes7. How much is too much? Unfortunately that depends on the context, but if you have more than 10% missing, you should probably be looking at alternatives.
14.3.2 Single value imputation
Single value imputation involves replacing missing values with a single value, such as the mean, median, mode or some other typical value of the feature. As common an approach as this is, it will rarely help your model for a variety of reasons. Consider a numeric feature that is 50% missing, and for which you replace the missing with the mean. How good do you think that feature will be when at least half the values are identical? Whatever variance it normally would have and share with the target is probably reduced, and possibly dramatically. Furthermore, you’ve also attenuated correlations it has with the other features, which may mute other modeling issues that you would otherwise deal with in some way (e.g., collinearity), or cause you to miss out on interactions.
Single value imputation makes perfect sense if you know that the missingness should be a specific value, like a count feature where missing means a count of zero. If you don’t have much missing data, it’s unlikely this would have any real benefit over complete case analysis. One exception is the case where imputing the feature then allows you to use all the other complete feature samples that would otherwise be dropped. But then, you could just drop this less informative feature while keeping the others, as it will often not be very useful in the model.
14.3.3 Model-based imputation
Model-based imputation is more complicated but can be very effective. In essence, you run a model for complete cases in which the feature with missing values is now the target, and all the other features and primary target are used to predict it. You then use that model to predict the missing values, using the predictions as the imputed values. After these predictions are made, you move on to the next feature and do the same. There are no restrictions on which model you use for which feature. If the other features in the imputation model also have missing data, you can use something like mean imputation to get more complete data if necessary as a first step, and then when their turn comes, impute those values.
Although the implication is that you would have one model per feature and then be done, you can do this iteratively for several rounds, such that the initial imputed values are then used in subsequent model rounds to reimpute other features’ missing values. You can do this as many times as you want, but the returns will diminish. In this setting, we are assuming you’ll ultimately end with a single imputed value for each missing one, which reflects the last round of imputation.
14.3.4 Multiple imputation
Multiple imputation (MI) is a more complicated technique, but it can be very useful in some situations, depending on what you’re willing to sacrifice for having better uncertainty estimates. The idea is that you create multiple imputed datasets, each of which is based on the predictive distribution of the model used in model-based imputation (see Section 4.4). Say we use a linear regression assuming a normal distribution to impute feature A. We would then draw repeatedly from the predictive distribution of that model to create multiple datasets with (randomly) imputed values for feature A.
Let’s say we do this 10 times, and we now have 10 imputed datasets, each with a now complete feature A, but each with somewhat different imputed values. We now run our desired model on each of these datasets. Final model results are averaged in some way to get final parameter estimates. Doing so acknowledges that your single imputation methods have uncertainty in those imputed values, and that uncertainty is incorporated into the final model estimates, including the uncertainty in those estimates.
MI can in theory handle any source of missingness and can be a very powerful technique. But it has some drawbacks that are often not mentioned, but which everyone that’s used it has experienced. One is that you need a specified target distribution for all imputation models used, in order to generate random draws with appropriate uncertainty. Your final model presumably is also a probabilistic model with coefficients and variances you are trying to estimate and understand. MI probably isn’t going to help boosting or deep learning models that have native methods for dealing with missing values, or at least, offers little over single value imputation for those approaches. In addition, if you have very large data and a complicated model, you could be spending a long time both waiting for the models and debugging them, because you still would need to assess the imputation models much like any other for the most part. Finally, few data or post-model processing tools that you commonly use will work with MI results, especially those regarding visualization. So you will have to hope that whatever package you use for MI will do what you need. As an example, you’d have to figure out how you’re going to impute interaction or spline terms if you have them.
Practically speaking, MI takes a lot of effort to often come to the same conclusions you would have with a single imputation method, or possibly fewer conclusions for anything beyond GLM coefficients and their standard errors. But if you want the best uncertainty estimates for those models, MI can be the way to go.
14.3.5 Bayesian imputation
One final option is to run a Bayesian model where the missing values are treated as parameters to be estimated, and they would have priors just like other parameters as well. MI is basically a variant of Bayesian imputation that can be applied to the non-Bayesian model setting, so why not just use the actual Bayesian approach? Some modeling packages can allow you to try this very easily, and it can be very effective. But it is also very computationally intensive and can be very slow as you may be increasing the number of parameters to estimate dramatically. At least it would be more fun than standard MI, so we recommend exploring it if you were going to do MI anyway.
14.4 Class Imbalance
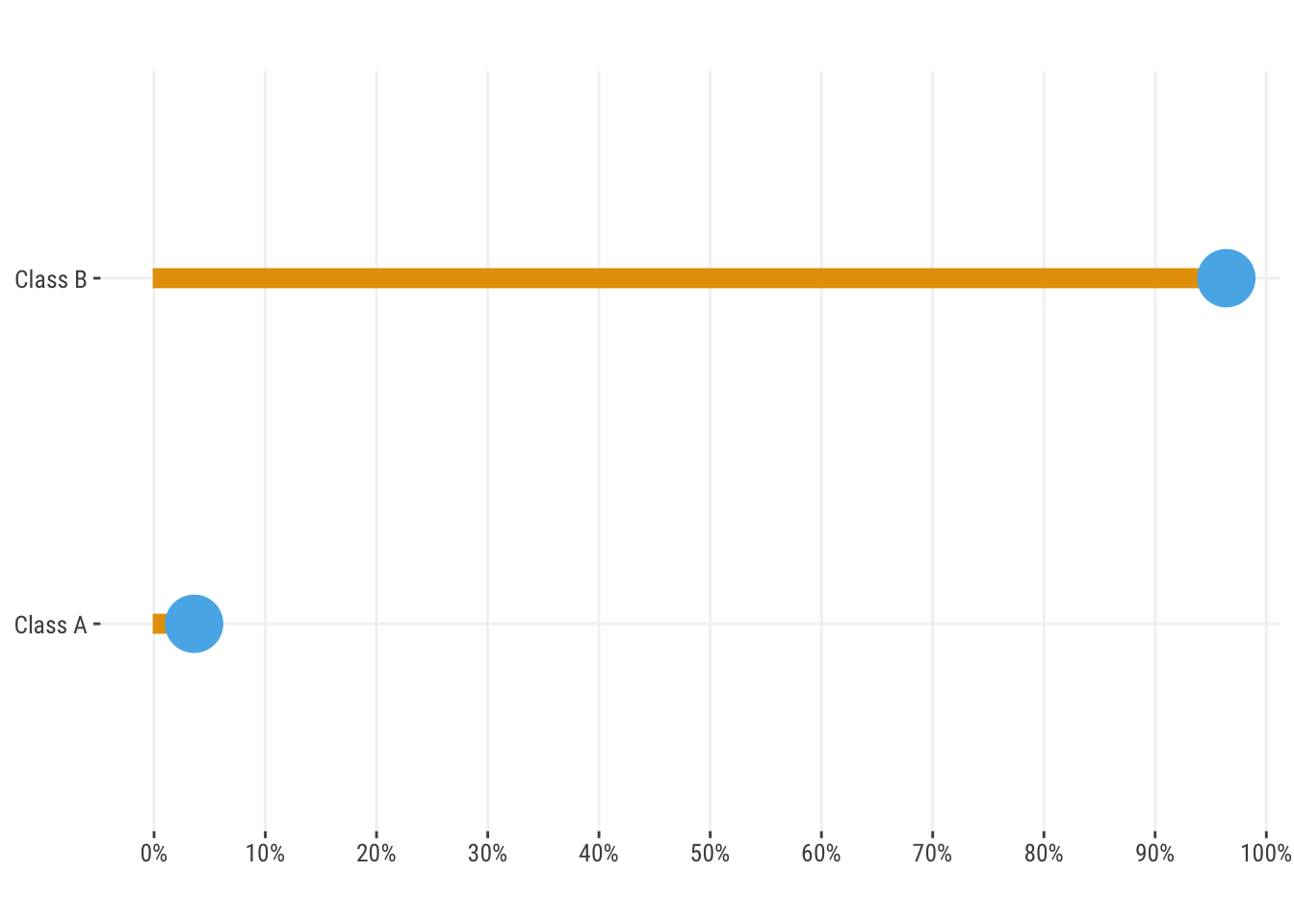
Class imbalance refers to the situation where the target variable has a large difference in the number of observations in each class. For example, if you have a binary target, and 90% of the observations are in one class, and 10% in the other, you would have class imbalance. You’ll almost never see a 50/50 split in the real world, but the issue is that as we move further away from that point, we can start to see problems in model estimation, prediction, and interpretation. In this example, if we just predict the majority class in a binary classification problem, our accuracy would be 90%! Under other circumstances that might be a great result for accuracy, but in this case it’s not. So right off the bat one of our favorite metrics to use for classification models isn’t going to help us much.
For classification problems, class imbalance is the rule, not the exception. This is because nature just doesn’t sort itself into nice and even bins. The majority of people in a random sample do not have cancer, the vast majority of people have not had a heart attack in the past year, most people do not default on their loans, and so on.
There are a number of ways to help deal with class imbalance, and the method that works best will depend on the situation. Some of the most common are:
- Use different metrics: Use metrics that are less affected by class imbalance, such as area under a receiver operating characteristic curve (AUC), or those that balance the tradeoff between precision and recall, like the F1 score, or something like the balanced accuracy score, which balances recall and true negative rate.
- Oversampling/Undersampling: Randomly sample from the minority (majority) class to increase (decrease) the number of observations in that class. For example, we can randomly sample with replacement from the minority class to increase the number of observations in that class. Or we can take a sample from the majority class to balance the resulting dataset.
- Weighted objectives: Weight the loss function to give more weight to the minority class. Although commonly employed, and simple to implement with tools like lightgbm and xgboost, it often fails to help and can cause other issues.
- Thresholding: Change the threshold for classification to be more sensitive to the minority class. Nothing says you have to use 0.5 as the threshold for classification, and you can change it to be more sensitive to the minority class. This is a very simple approach and may be all you need.
These are not necessarily mutually exclusive. For example, it’s probably a good idea to switch your focus to a metric besides accuracy even as you employ other techniques to handle imbalance. See (Clark 2025).
14.4.1 Calibration issues in classification
Probability calibration is often a concern in classification problems. It is a bit more complex of an issue than just having class imbalance but is often discussed in the same setting. Having calibrated probabilities refers to the situation where the predicted probabilities of the target match up well to the actual proportion of observed classes. For example, if a model predicts an average 0.5 probability of loan default for a certain segment of the samples, the actual proportion of defaults should be around 0.5.
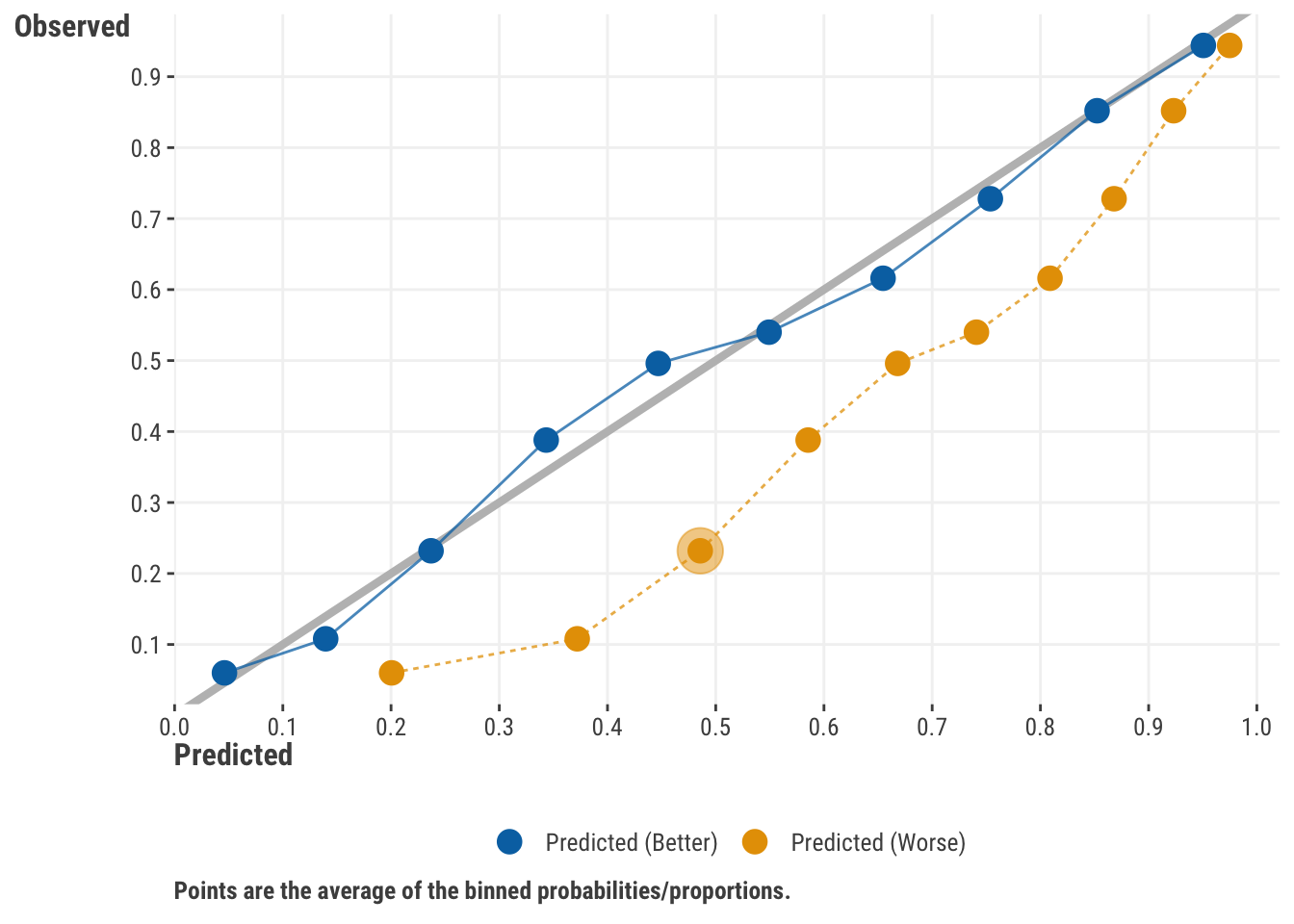
One way to assess calibration is to use a calibration curve, which is a plot of the predicted probabilities vs. the observed proportions. We bin our predicted probabilities, say, into 5 or 10 equal bins. We then calculate the average predicted probability and the average observed proportion of the target in each bin. If the model is well calibrated, the points should fall along the 45-degree line. If not, the points will fall above or below the line.
In Figure 14.5, one model seems to align well with the observed proportions based on the chosen bins. The other model (dashed line) is not so well calibrated and is overshooting with its predictions. For example, that model’s average prediction for the third bin predicts a ~0.5 probability of the outcome, while the actual proportion is around 0.2.
While the issue is an important one, it’s good to keep the issue of calibration and imbalance separate. As miscalibration implies bias, bias can happen irrespective of the class proportions, and it can be due to a variety of factors related to the model, target, or features. Furthermore, miscalibration is not inherent to any particular model.
The assessment of calibration in this manner also has a few issues that we haven’t seen reported in the documentation for it. For one, the observed ‘probabilities’ are proportions based on arbitrarily chosen bins, and there are multiple ways to choose the bins. The observed values also have some measurement error and have a natural variability that will partly reflect sample size8. In addition, these plots are often presented such that observed proportions are labeled as the ‘true’ probabilities. However, you do not have the true probabilities, just the observed class labels, so whether your model’s predicted probabilities match observed proportions is actually a bit of a different question. The predictions have uncertainty as well, and this will depend on the model, sample size, and other factors. And finally, the number of bins chosen can also affect the appearance of the plot in a notable way if the sample size is small, which is a perceptual issue that can be misleading regardless of the models in question.
All this is to say that each point in a calibration plot, ‘true’ or predicted, has some uncertainty with it, and the difference in those values is not formally tested in any way by a calibration curve plot. Their uncertainty, if it was actually measured, could even overlap while still being statistically different! So, if we’re interested in a more rigorous statistical assessment, the differences between models and the ‘best case scenario’ would need additional steps to suss out.
Some methods are available to calibrate probabilities if they are deemed miscalibrated, but they are not commonly implemented in practice and often involve another model-based technique, with all of its own assumptions and limitations. It’s also not exactly clear that forcing your probabilities to be on the line is helping solve the actual modeling goal in any way9. But if you are interested, you can read more at the sklearn documentation on calibration.
14.5 Censoring and Truncation
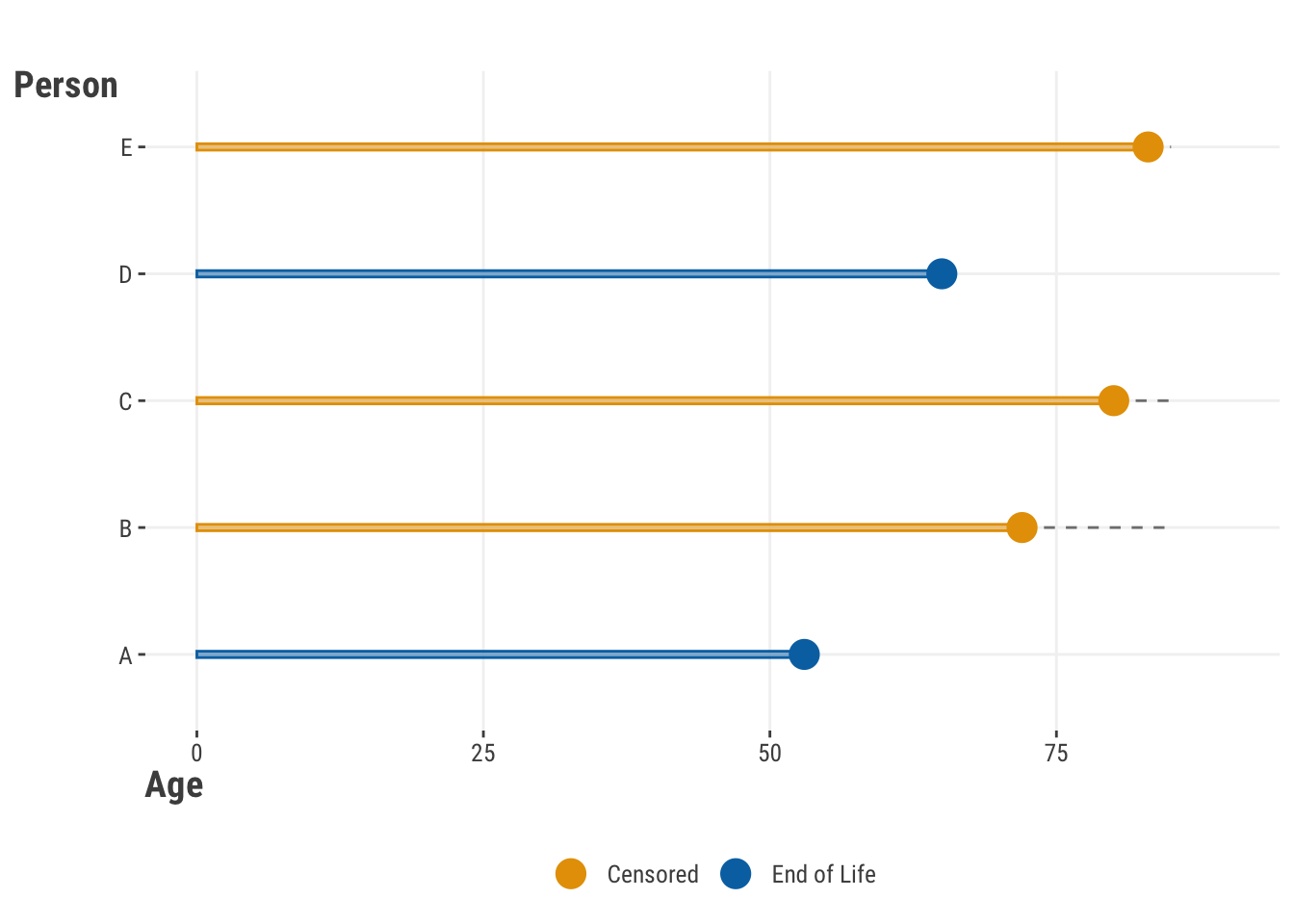
Sometimes, we just don’t see all the data there is to see. Censoring is one situation where the target variable is not fully observed. This is common in techniques where the target is the ‘time to an event’, like death from a disease, but the event has not yet occurred for some observations in the data (thankfully!). Specifically this is called right censoring, and is the most common type of censoring, and depicted in Figure 14.6, where several individuals are only observed to a certain age and were still alive at that time. There is also left censoring, where the censoring happens from the other direction, and data before a certain point is unknown. Finally, there is interval censoring, where the event of interest occurs within some interval, but the exact value is unknown.
Survival analysis10 is a common modeling technique in this situation, especially in fields informed by biostatistics, but you may also be able to keep things even more simple via something like tobit regression. In the tobit model, you assume that the target is fully observed, but that the values are censored, and you model the probability of censoring. This is a common technique in econometrics, and it allows you to keep a traditional linear model context.
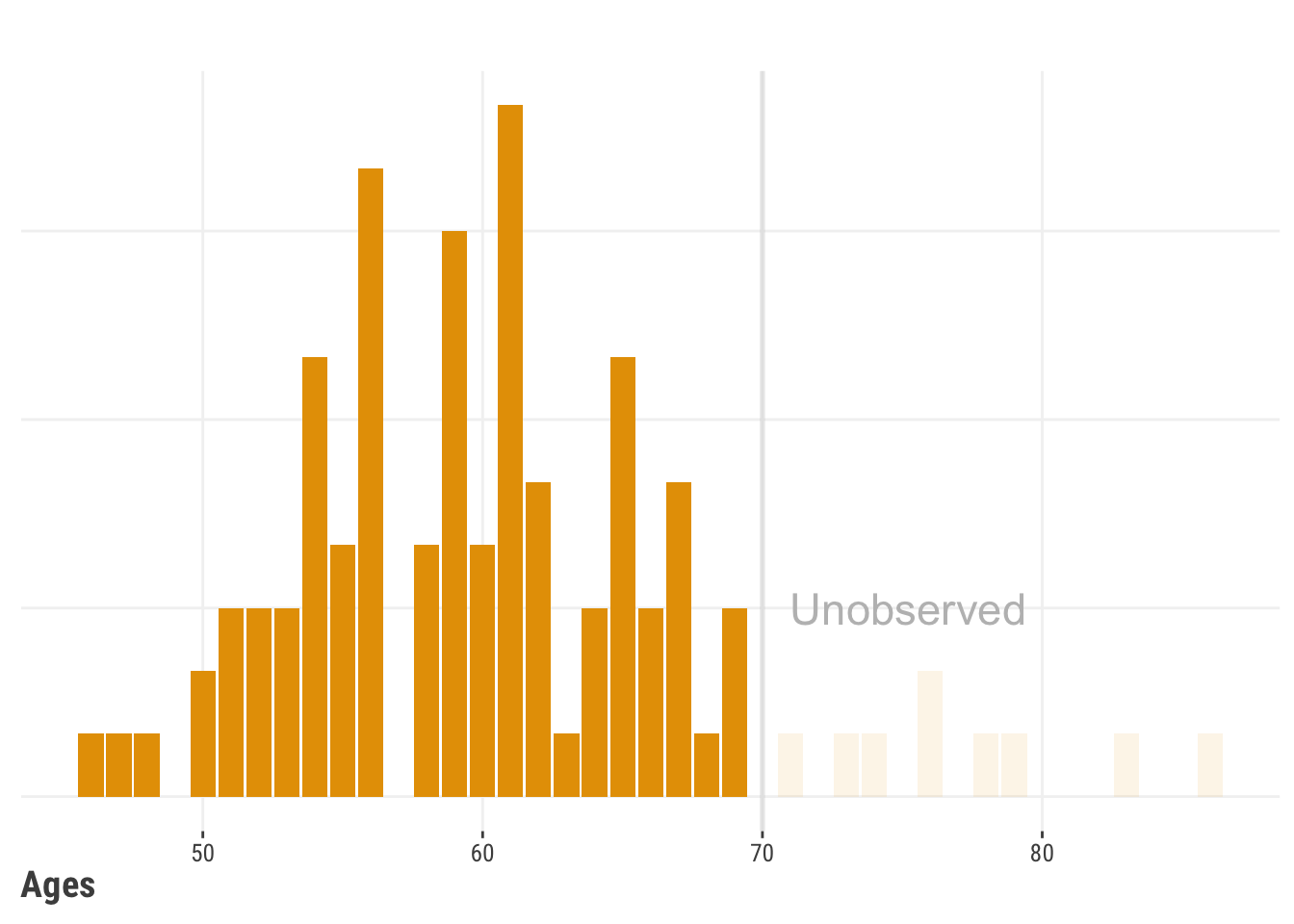
Truncation is a situation where the target variable is only observed if it is above or below some value, even though we know other possibilities exist. One of the issues is that default distributional methods assume a distribution that is not bounded in the way that the data exhibits. In Figure 14.7, we restrict our data to 70 and below for practical or other reasons, but typical modeling methods predicting age would not respect that.
You could truncate predictions after the fact, but this is a bit of a hack, and often results in lumpiness in the predictions at the boundary that is rarely realistic. Alternatively, Bayesian methods allow you to model the target as a distribution with truncated distributions, and so you can model the probability of the target being above or below some value. There are also models such as hurdle models that might prove useful where the truncation is theoretically motivated, for example, a zero-inflated Poisson model for count data where the zero counts are due to a separate process than the non-zero counts.
Censoring vs. Truncation
One way to distinguish censored and truncated data is that censored data is usually due to some external process such that the target is not observed, but could be possible (capping reported income at $1 million). Truncated data, on the other hand, is due to some internal process that prevents the target from being observed and is often derived from sample selection (we only want to model non-millionaires). We would not want predictions past the censored point to be unlikely, but we would want predictions past the truncated point to be impossible. Trickier still is that for bounded or truncated distributions that might be applied to the truncated scenario, such as folded vs. truncated distributions, they would not result in the same probability distributions even if they can be applied to the same data situation.

14.6 Time Series

Time series data is any data that incorporates values over a period of time. This could be something like a state’s population over years, or the max temperature of an area over days. Time series data is very common in data science, and there are a number of ways to model such data.
14.6.1 Time-based targets
As in other settings, when the target is a value that varies over time, the most common approach is to use a linear model of some kind. Note that while the target varies over time, the features may be time-varying or not, and it is very common to have both types of features (e.g., a person’s age vs. the person’s race/ethnicity).
There are traditional autoregressive models that use the target’s past values (lags) as features, for example, autoregressive moving average (ARIMA) models. In this case, the target is a function of its past values, and possibly the past values of other features. In these models, forecasting, or making predictions about future values, is the primary goal. Care will have to be taken to avoid data leakage in the training process, and to use proper standardization of the data if applicable. In some settings, common transformations such as logging can be used. In other cases, you may want to use a differencing approach to make the data stationary, which can be useful for some models. Differencing is the process of subtracting the previous value from the current value, and it can be done multiple times to remove trends and seasonality. Often this is done automatically as part of a hyperparameter search, but it can be done manually as well. Boosting models using lagged features can also be used for time series data and can be very effective in many situations.
Longitudinal data11 is a special case of time series data, where the target is a function of time (e.g., date), but the data is typically grouped in some fashion and is often of a shorter sequence. An example would be a model for school performance for students over several semesters, where values are clustered within students over time. In this case, you can use some sort of time series regression, though many do not do well with shorter series. Instead, you can use a mixed model (Section 9.3), where you model the target as a function of time, but also include a random effect for the grouping variable, in this case, students. This could, and typically does, include both random intercepts and slopes for time. This is a very common approach in many domains and can be very effective in terms of performance as well. Mixed models can also be used for longer series, where the random effects are based on autoregressive covariance matrices. In this case, an ARIMA component is added to the linear model as a random effect to account for the time series nature of the data. This is fairly common in Bayesian contexts. Generalized additive models also work well in this setting.
Other models provide additional options for incorporating historical information, such as Bayesian methods for marketing data (Section 7.6) or reinforcement learning approaches (Section 12.3). Some models get more complex, like recurrent neural networks and their generalizations, and were specifically developed for sequential data. More recently, transformer-based models have shown promise for time series analysis beyond text. In this area, ‘foundational’ models like TimeGPT, Moirai, Chronos, or TinyTimeMixers have been proposed, though they often require more data than is typically available in many common settings. In addition, they have not proven to be as effective as simpler models in many cases12.
So, many models can be found specific to time series targets, and the choice of model will depend on the data, the questions we want to ask, and the goals we have. Most traditional models are still linear models, but traditional machine learning models, like boosting, and many neural network models have been developed that can handle time series data as well. It may be the case that you will switch to using different loss functions or metrics with time series data, such as (symmetric) mean absolute percentage error and scaled errors (Hyndman and Athanasopoulos (2021)).
14.6.2 Time-based features
When it comes to time-series features, we can apply time-specific transformations. One technique is the fourier transform, which can be used to decompose a time series into its component frequencies, much like how we use PCA (Section 12.2). This can be useful for identifying periodicity in the data, which can be used as a feature in a model.
In marketing contexts, some perform adstocking with features. This approach models the delayed effect of features over time, such that they may have their most important impact immediately, but still can impact the present target value from past values. For example, a marketing campaign might have the most significant impact immediately after it’s launched, but it can still influence the target variable at later time points, albeit more weakly as the distance in time is extended. Adstocking helps capture this delayed effect without having to include multiple lagged features in the model. That said, including lagged features is also an option in this setting. In this case, you would have a feature for the current time point (t), the same feature for the previous time point (t-1), the feature for the time point before that (t-2), and so on.
14.6.2.1 Scaling time features
If you have the year as a feature, you can use it as a numeric feature or as a categorical feature. If you treat it as numeric, you need to consider what a zero means. In a linear model, the intercept usually represents the outcome when all features are zero. But with a feature like year, a zero year isn’t meaningful in most contexts. To solve this, you can shift the values so that the earliest time point, like the first year in your data, becomes zero. This way, the intercept in your model will represent the outcome for this first time point, which is more meaningful. The same goes if you are using months or days as a numeric feature. It doesn’t really matter which year/month/day is zero, just that zero refers to one of the actual time points observed. Shifting your time feature in this manner can also help with convergence for some types of models. In addition, you may want to convert the feature to represent decades, or quarters, or some other time period, to help with interpretation.
Dates and/or times can be a bit trickier. Often you can just split dates out into year, month, day, etc., and proceed with those as features. In other cases you’d want to track the time period to assess possible seasonal effects. You can use something like a cyclic approach (e.g., cyclic spline or sine/cosine transformation) to get at yearly or within-day seasonal effects. As mentioned, a fourier transform can also be used to decompose the time series into its component frequencies for use as model features. Time components like hours, minutes, and seconds can often be dealt with in similar ways, but you will more often deal with the periodicity in the data. For example, if you are looking at hourly data, you may want to consider the 24-hour cycle.
14.6.2.2 Covariance structures
In many cases you’ll have features that vary over time but are not a time-oriented feature like year or month. For example, you might have a feature that is the number of people who visited a website over days. This is a time-varying feature, but it’s not a time metric in and of itself.
In general, we’d like to account for the time-dependent correlations in our data, and a common way to do so is to posit a covariance structure that accounts for this in some fashion. This helps us understand how data points are related to each other over time, and requires us to estimate the correlations between observations. As a starting point, consider linear regression. In a standard linear regression model, we assume that the samples are independent of one another, with a constant variance and no covariance.
Instead, we can also use something like a mixed model, where we include a random effect for each group and estimate the variance attributable to the grouping effect. By default, this ultimately assumes a constant correlation from time point to time point, but many tools allow you to specify a more complex covariance structure. A common method is to use autoregressive covariance structure that allows for correlations further apart in time to lessen. In this sense the covariance comes in as an added random effect, rather than being a model in and of itself as with ARIMA. Many such approaches to covariance structures are special cases of Gaussian processes, which are a very general technique to model time series, spatial, and other types of data.

14.7 Spatial Data

We visited spatial data in a discussion on non-tabular data (Section 12.4.1), but here we want to talk about it from a modeling perspective, especially within the tabular domain. Say you have a target that is a function of location, such as the proportion of people voting a certain way in a county, or the number of crimes in a city. You can use a spatial regression model, where the target is a function of location, among other features that may or may not be spatially oriented. Two approaches already discussed may be applied in the case of having continuous spatial features, such as latitude and longitude, or discrete features like county. For the continuous case, we could use a GAM (Section 9.4) that employs a smooth interaction of latitude and longitude. For the discrete setting, we can use a mixed model (Section 9.3.2), where we include a random effect for county.
There are other traditional techniques to spatial regression, especially in the continuous spatial domain, such as using a spatial lag. In this case, we incorporate information about the neighborhood of an observation’s location into the model. An example is shown in the previous visualization that depicts a weighted mean of neighboring values for different tracts (based on code from Walker (2023))13. Techniques include CAR (conditional autoregressive), SAR (spatial autoregressive), BYM, kriging, and more, and these models can be very effective. They can also be seen as a different form of random effects models very similar to those used for time-based settings via covariance structures. They can also be seen as special cases of Gaussian process regression more generally. So don’t let the names fool you, you often will incorporate similar modeling techniques for both the time and spatial domains.
14.8 Multivariate Targets
Often you will encounter settings where the target is not a single value, but a vector of values. This is often called a multivariate target in statistical settings, or just the norm for deep learning. For example, you might be interested in predicting the number of people who will buy a product, the number of people who will click on an ad, and the number of people who will sign up for a newsletter. The main idea is that there is a correlation among the targets, and you want to take this into account when analyzing them simultaneously.
One model example we’ve already seen is the case where we have more than two categories for the target (Section 14.2.2.2). Some default approaches may take that input and just do a one-vs.-all, for each category, but this kind of misses the point. Others will simultaneously model the multiple targets in some way. On the other hand, it can be difficult to interpret results with multiple targets. Because of this, you’ll often see results presented in terms of the respective targets anyway, and often even ignoring parameters specifically associated with such a model14.
It is also common to have multiple targets in a regression setting, where you might want to predict multiple outcomes simultaneously. This is sometimes called multivariate regression and is a common technique in many fields. In this case, you can use a linear model, but you’ll have to account for the correlation between the targets. This can be done with a multivariate normal distribution, where the targets are assumed to be normally distributed, and the covariance matrix for the targets is estimated rather than just a single variance value. This is a very common approach and is often used in mixed models as well, which offer a different way to go about the same model.
In deep learning contexts, the multivariate setting is ubiquitous. For example, if you want to classify the content of an image, you might have to predict something like different species of animals, or different types of car models. In natural language processing, you might want to predict the probability of different words in a sentence. In some cases, there are even multiple kinds of targets considered simultaneously! It can get very complex, but often in these settings prediction performance far outweighs the need to interpret specific parameters, and so it’s a good fit.
14.9 Latent Variables

Latent variables are a fundamental aspect of modeling, and simply put, they are variables that are not directly observed, but instead are inferred from other variables. Here are some examples of what might be called latent variables:
- The linear combination of features in a linear regression model is a latent variable, but usually we only think of it as such before the link transformation in GLMs (Chapter 8).
- The error term in any model is a latent variable representing all the unknown/unobserved/unmodeled factors that influence the target (Equation 3.3).
- The principal components in PCA (Chapter 12).
- The measurement error in any feature or target.
- The factor scores in a factor analysis model or structural equation (visualization above).
- The true target underlying the censored values (Section 14.5).
- The clusters in cluster analysis/mixture models (Section 12.2.1.1).
- The random effects in a mixed model (Section 9.3).
- The hidden states in a hidden Markov model.
- The hidden layers in a deep learning model (Section 11.7).
Though they may be used in different ways, it’s easy to see that latent variables are very common in modeling, so it’s good to get comfortable with the concept. Whether they’re appropriate to your specific situation will depend on a variety of factors, but they can be very useful in many settings, if not a required part of the modeling approach.
14.10 Data Augmentation
Data augmentation is a technique where you artificially increase the size of your dataset by creating new data points based on the existing data. This is a common technique in deep learning for computer vision, where you might rotate, flip, or crop images to create new training data. This can help improve the performance of your model, especially when you have a small dataset. Conceptually similar techniques are also available for text.
In the tabular domain, data augmentation is less common but still possible. For example, you can see it applied in class-imbalance settings (Section 14.4), where you might create new data points for the minority class to balance the dataset. This can be done by randomly sampling from the existing data points, or by creating new data points based on the existing data points. For the latter, SMOTE and many variants of it are quite common (for better or worse; see Elor and Averbuch-Elor (2022)).
Unfortunately for tabular data, these techniques are not nearly as successful as augmentation for computer vision or natural language processing, nor consistently so. Part of the issue is that tabular data is very noisy and fraught with measurement error, so in a sense, such techniques are just adding noise to the modeling process without any additional means to amplify the signal15. Downsampling the majority class can potentially throw away useful information. Simple random upsampling of the minority class can potentially lead to an overconfident model that doesn’t generalize well. In the end, the best approach is to get more and/or better data, but as that often is not possible, hopefully more successful methods will be developed in the future for the tabular domain.
14.11 Wrapping Up
There’s a lot going on with data before you ever get to modeling, and which will affect every aspect of your modeling approach. This chapter outlined common data types, issues, and associated modeling aspects, but in the end, you’ll always have to make decisions based on your specific situation, and they will often not be easy ones. These are only some of the things to consider, so be ready for surprises, and be ready to learn from them!
14.11.1 The common thread
Many of the transformations and missing data techniques can be applied in diverse modeling settings. Likewise, you may find yourself dealing with different target variable issues like imbalance or censoring, and dealing with temporal, spatial or other structures, in a variety of models. The key is to understand the data well, and to make the best decisions you can based on that knowledge.
14.11.2 Choose your own adventure
Consider revisiting a model covered elsewhere in this book in light of the data issues discussed here. For example, how might you deal with class imbalance for a boosted tree model? How would you deal with spatial structure in a neural network? How would you deal with a multivariate target in a time series model?
14.11.3 Additional resources
Here are some additional resources to help you learn more about the topics covered in this chapter.
Transformations
- About Feature Scaling and Normalization (Raschka (2014))
- What are Embeddings (Boykis (2023))
Class Imbalance
Brief Overview (Google)
Handling imbalanced datasets in machine learning (Rocca (2019))
Imbalanced Outcomes: Challenges & Solutions (Clark (2025))
A Gentle Introduction to Imbalanced Classification (Brownlee (2019))
Calibration
- Why some algorithms produce calibrated probabilities (StackExchange)
- Predicting good probabilities with supervised learning (Niculescu-Mizil and Caruana (2005))
Survival, Ordinal and Other Models
- Regression Modeling Strategies is a great resource for statistical modeling in general (Harrell (2015))
- Ordinal Regression Models in Psychology: A Tutorial is a great resource by the author of the best Bayesian modeling package brms16 (Bürkner and Vuorre (2019))
Time Series
- Forecasting: Principles and Practice (Hyndman and Athanasopoulos (2021))
Latent Variables
There’s a ton of stuff, but one of your humble authors has an applied treatment that is not far from the conceptual approach of this text, along with a bit more general exploration. However, we’d recommend more of an ‘awareness’ of latent variable modeling, as you will likely be more interested in the specific application for your data and model, which can be very different from these contexts.
Thinking about Latent Variables (Clark (2018b))
Graphical and Latent Variable Modeling (Clark (2018a))
Data Augmentation
- What is Data Augmentation? (Amazon (2024))
Other
We always need to inspect the data closely and see if it matches our expectations. This is a critical part of the modeling process and can often be the most time-consuming part. There are tools that can help with the validation process, and to that end, you might look at pointblank in R or y_data_profiling in Python as options to get started.
Scaling to a mean of zero and standard deviation of one is not the only way to scale variables. You can technically scale to any mean and standard deviation you want, but in tabular data settings you will have different and possibly less interpretability, and you may lose something in model estimation performance (convergence). For deep learning, the actual normalization may be adaptive applied across iterations.↩︎
For the bazillionth time, logging does not make data ‘normal’ so that you can meet your normality assumption in linear regression.↩︎
That doesn’t mean you won’t see many people try (and fail).↩︎
Note that one-hot encoding can refer to just the 1/0 coding for all categories, or to the specific case of dummy coding where one category is dropped. Make sure the context is clear.↩︎
Try Helmert coding for instance! No, don’t do that.↩︎
This is just for demonstration purposes. You should not categorize a continuous variable unless you have a very good reason to do so.↩︎
While many statisticians will possibly huff and puff at the idea of dropping data, there are two things to consider. With minimal missingness you’ll likely never come to a different conclusion unless you have very little data to come to a conclusion about, which is already the bigger problem. Secondly, it’s impossible to prove one way or another if the data is missing at random, because doing so would require knowing the missing values.↩︎
Note that each bin will reflect the portion of the test set size in this situation. If you have a small test set, the observed proportions will be more variable, and the calibration plot will be more variable as well.↩︎
Oftentimes we are only interested in the ordering of the predictions, and not the actual probabilities. For example, if we are trying to identify the top 10% of people most likely to default on their loans, we’ll just take the top 10% of predictions, and the actual probabilities are irrelevant for that goal.↩︎
Survival analysis is also called event history analysis, and is widely used in biostatistics, sociology, demography, and other disciplines where the target is the time to an event, such as death, marriage, divorce, etc.↩︎
You may also hear the term panel data in econometrics-oriented disciplines.↩︎
For example, see Nixtla’s experiments with Amazon’s Chronos vs. a simple combination of univariate models. NB: Amazon said that the default settings were not very good, and it would perform much better with different settings, but possibly still would not beat the simpler model.↩︎
In the book’s print version, darker colors indicate higher values, but in the web version, red represents larger relative values. ↩︎
It was common in social sciences back in the day to run a Multivariate ANOVA, and then if the result was statistically significant, and mostly because few practitioners knew what to do with the result, they would run separate ANOVAs for each target.↩︎
Compare to the image settings where there is relatively little measurement error, by just rotating an image, you are still preserving the underlying structure of the data.↩︎
No, we’re not qualifying that statement.↩︎