| term | happiness | life_exp | log_gdp_pc | corrupt |
|---|---|---|---|---|
| happiness | 1.00 | 0.78 | 0.82 | −0.47 |
| life_exp | 0.78 | 1.00 | 0.86 | −0.34 |
| log_gdp_pc | 0.82 | 0.86 | 1.00 | −0.34 |
| corrupt | −0.47 | −0.34 | −0.34 | 1.00 |
6 Model Estimation and Optimization
In our initial linear model, the coefficients for each feature are the key parameters. But how do we know what the coefficients are, and how did we come to those values? When we explore a linear model using some package function, they appear magically, but it’s worth knowing a little bit about how they come to be, so let’s try and dive a little deeper. As we do so, we’ll end up going a long way into ‘demystifying’ the modeling process.
Model estimation is the process of finding the parameters associated with a model that allow us to reach a particular modeling goal. Different types of models will have different parameters to estimate, and there are different ways to estimate them. In general though, the goal is the same, find the set of parameters that will lead to the best predictions under the current data modeling context.
With model estimation, we can break things down into the following steps:
- Start with an initial guess for the parameters.
- Calculate the prediction error based on those parameters, or some function of it, or some other value that represents our model’s objective.
- Update the guess.
- Repeat steps 2 and 3 until we find a ‘best’ guess.
Pretty straightforward, right? Well, it’s not always so simple, but this is the general idea in most applications, so keep it in mind! In this chapter, we’ll show how to do this ourselves to take away the mystery a bit from when you run standard model functions in typical contexts. Hopefully, then you’ll gain more confidence when you do use them!
6.1 Key Ideas
A few concepts we’ll keep using here are fundamental to understanding estimation and optimization. We should note that we’re qualifying our present discussion of these topics to typical linear models, machine learning, and similar settings, but they are much more broad and general than presented here. We’ve seen some of this before, but we’ll be getting a bit cozier with the concepts now.
- Parameters are the values associated with a model that we have to estimate.
- Estimation is the process of finding the parameters associated with a model.
- The objective (loss) function takes input and produces a value that we want to maximize or minimize.
- Prediction error is the difference between the observed value of the target and the predicted value, and is often used to calculate the objective function.
- Optimization is the specific process of finding the parameters that maximize or minimize some objective function.
- Model selection is the process of choosing the best model from a set of models.
6.1.1 Why this matters
When it comes to modeling, even knowing just a little bit about what goes on behind the scenes is a great demystifier. And if models are less of a mystery, you’ll feel more confident using them. Much of what you see here is part of almost every common model used for statistics and machine learning, and adding this knowledge provides you a more solid foundation for expanding your modeling skills.
6.1.2 Helpful context
This chapter is more involved and technical than most of the others, so it might be more suited for those who like to get their hands dirty. It’s all about DIY, and so we’ll be doing a lot of the work ourselves. If you’re not one of those types of people who gets much out of that, that’s okay, you can skip this chapter and still get a lot out of the rest of the book. But if you’re curious about how models work, or you want to be able to do more than just run a canned function, then we think you’ll find the following useful. You’d want to at least have your linear model basics down (Chapter 3).
6.2 Data Setup
For the examples here, we’ll use the world happiness dataset for the year 2018. We’ll use the happiness score as our target. Let’s take an initial look at the data here, but for more information see the Appendix Section D.2.
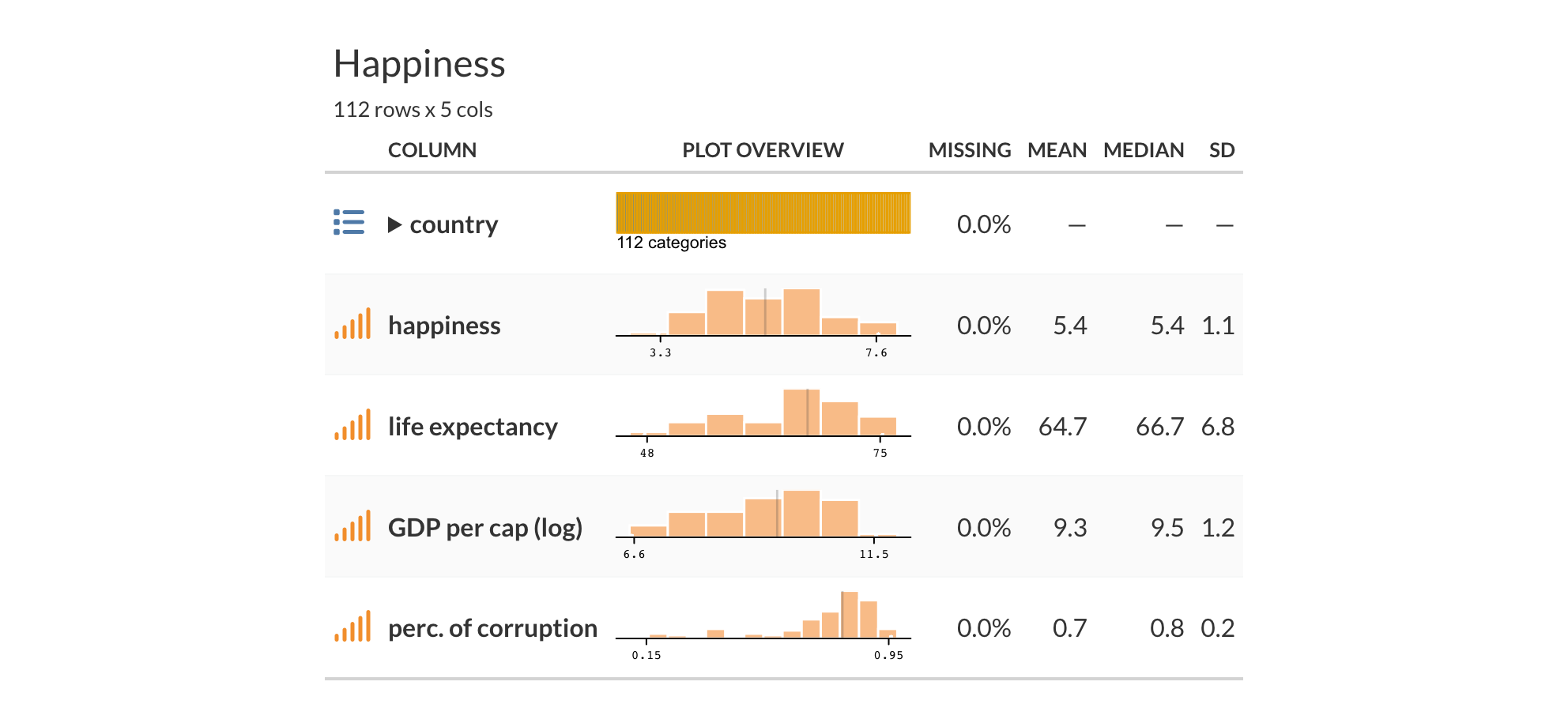
Our happiness score has values from around 3-7, life expectancy and GDP appear to have some notable variability, and corruption perception is skewed toward lower values. We can also see that the features and target are correlated, which is not surprising.
For our purposes here, we’ll drop any rows with missing values, and we’ll use scaled features so that they have the same variance, which, as noted in the data chapter (Chapter 14), can help make estimation easier.
df_happiness = read_csv('https://tinyurl.com/worldhappiness2018') |>
drop_na() |>
rename(happiness = happiness_score) |>
select(
country,
happiness,
contains('_sc')
)import pandas as pd
df_happiness = (
pd.read_csv('https://tinyurl.com/worldhappiness2018')
.dropna()
.rename(columns = {'happiness_score': 'happiness'})
.filter(regex = '_sc|country|happ')
)6.2.1 Other Setup
For the R examples, after the above, nothing beyond base R is needed. For Python examples, the following should be enough to get you through the examples.
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.optimize import minimize
from scipy.stats import norm6.3 Starting out by Guessing
So, we’ll start with a model in which we predict a country’s level of happiness by their life expectancy. If you can expect to live longer, you’re probably in a country with better health care, higher incomes, and other important factors. As such, we can probably expect higher happiness scores with higher life expectancy. We’ll stick with a linear regression model as well to start out.
As a starting point, we can just guess what the parameter should be. But how would we know what to guess? How would we know which guesses are better than others? Let’s try a couple guesses and see what happens. Let’s say that we think all countries start at the bottom on the happiness scale (around 3), but life expectancy makes a big impact– for every standard deviation of life expectancy, we go up a whole point on happiness1. We can plug this into the model and see what we get:
\[ \text{prediction} = 3.3 + 1\cdot\text{life\_exp} \]
For a different model, we’ll say countries start with a mean of happiness score, and moving up a standard deviation of life expectancy would move us up a half point of happiness. \[ \text{prediction} = \overline{\text{happiness}} + .5\cdot\text{life\_exp} \]
How do we know which is better? Let’s find out!
6.4 Prediction Error
We’ve seen that a key component to model assessment involves comparing the predictions from the model to the actual values of the target. This difference is known as the prediction error, or residuals in more statistical contexts. We can express this as:
\[ \epsilon = y - \hat{y} \] \[ \text{error} = \text{target} - \text{model-based guess} \]
This prediction error tells us how far off our model prediction is from the observed target values, but it also gives us a way to compare models. How? With our measure of prediction error, we can calculate a total error for all observations/predictions (Section 4.2), or similarly, the average error. If one model or parameter set has less total or average error, we can say it’s a better model than one that has more (Section 4.3). Ideally we’d like to choose a model with the least possible error, but we’ll see that this is not always possible2.
However, if we just take the average of our errors from a linear regression model, you’ll see that it is roughly zero! This is by design for many common models and is even made explicit in their mathematical depiction. So, to get a meaningful error metric, we need to use the squared error value or the absolute value. These also allow errors of similar value above and below the observed value to cost the same3. As we’ve done elsewhere, we’ll use squared error here, and we’ll calculate the mean of the squared errors for all our predictions, i.e., the Mean Squared Error(MSE).
y = df_happiness$happiness
# Calculate the error for the guess of 4
prediction = min(df_happiness$happiness) + 1*df_happiness$life_exp_sc
mse_model_A = mean((y - prediction)^2)
# Calculate the error for our other guess
prediction = mean(y) + .5 * df_happiness$life_exp_sc
mse_model_B = mean((y - prediction)^2)
tibble(
Model = c('A', 'B'),
MSE = c(mse_model_A, mse_model_B)
)y = df_happiness['happiness']
# Calculate the error for the guess of four
prediction = np.min(df_happiness['happiness']) + \
1 * df_happiness['life_exp_sc']
mse_model_A = np.mean((y - prediction)**2)
# Calculate the error for our other guess
prediction = y.mean() + .5 * df_happiness['life_exp_sc']
mse_model_B = np.mean((y - prediction)**2)
pd.DataFrame({
'Model': ['A', 'B'],
'MSE': [mse_model_A, mse_model_B]
})Now let’s look at our MSE, and we’ll also inspect the square root of it, or the Root Mean Squared Error (), as that puts things back on the original target scale and tells us the standard deviation of our prediction errors. We also add the Mean Absolute Error (MAE) as another metric with straightforward interpretation.
| Model | MSE | RMSE | MAE | RMSE % drop | MAE % drop |
|---|---|---|---|---|---|
| A | 5.09 | 2.26 | 1.52 | ||
| B | 0.64 | 0.80 | 0.58 | 65% | 62% |
Inspecting the metrics, we can see that we are off on average by over a point for model A (MAE), and a little over half a point on average for model B. So we can see that model B is not only better, but it results in a 65% drop in RMSE, and similar for MAE. We’d definitely prefer it over model A. This approach is also how we can compare models in a general fashion.
Now all of this is useful, and at least we can say one model is better than another. But you’re probably hoping there is an easier way to get a good guess for our model parameters, especially when we have possibly dozens of features and/or parameters to keep track of, and there is!
6.5 Ordinary Least Squares
In a simple linear model, we often use the Ordinary Least Squares (OLS) method to estimate parameters. This method finds the coefficients that minimize the sum of the squared differences between the predicted and actual values4. In other words, it finds the coefficients that minimize the sum of the squared differences between the predicted values and the actual values, which is what we just did in our previous example. The sum of the squared errors is also called the Residual Sum of Squares (RSS), as opposed to the ‘total’ sums of squares (i.e., the variance of the target), and the part explained by the model (‘model’ or ‘explained’ sums of squares). We can express this as follows, where \(y_i\) is the observed value of the target for observation \(i\), and \(\hat{y_i}\) is the predicted value from the model.
\[ \text{Value} = \sum_{i=1}^{n} (y_i - \hat{y_i})^2 \tag{6.1}\]
It’s called ordinary least squares because there are other least squares methods, generalized least squares, weighted least squares, and others, but we don’t need to worry about that for now. The sum or mean of the squared errors is our objective value. The objective function takes the predictions and observed target values as inputs and returns the objective value as an output. We can use this value to find the best parameters for a specific model, as well as compare models with different parameters.
Now let’s calculate the OLS estimate for our model. We need our own function to do this, but it doesn’t take much to create one. We need to map our inputs to our output, which are the model predictions. We then calculate the error, square it, and then average the squared errors to provide the mean squared error.
# for later comparison
model_lr_happy = lm(happiness ~ life_exp_sc, data = df_happiness)
ols = function(X, y, par) {
# add a column of 1s for the intercept
X = cbind(1, X)
# Calculate the predicted values
y_hat = X %*% par # %*% is matrix multiplication
# Calculate the error
error = y - y_hat
# Calculate the value as mean squared error
value = sum(error^2) / nrow(X)
# Return the objective value
return(value)
}# for later comparison
model_lr_happy = smf.ols('happiness ~ life_exp_sc', data = df_happiness).fit()
def ols(par, X, y):
# add a column of 1s for the intercept
X = np.c_[np.ones(X.shape[0]), X]
# Calculate the predicted values
y_hat = X @ par # @ is matrix multiplication
# Calculate the mean of the squared errors
value = np.mean((y - y_hat)**2)
# Return the objective value
return valueWe’ll want to make a bunch of guesses for the parameters, so let’s create data for those guesses. We’ll then choose the guess that gives us the lowest objective value. But before getting carried away, try it out for just one guess to see how it works!
# create a grid of guesses
guesses = crossing(
b0 = seq(1, 7, 0.1),
b1 = seq(-1, 1, 0.1)
)
# Example for one guess
ols(
X = df_happiness$life_exp_sc,
y = df_happiness$happiness,
par = unlist(guesses[1, ])
)[1] 23.78# create a grid of guesses
from itertools import product
guesses = pd.DataFrame(
product(
np.arange(1, 7, 0.1),
np.arange(-1, 1, 0.1)
),
columns = ['b0', 'b1']
)
# Example for one guess
ols(
par = guesses.iloc[0,:],
X = df_happiness['life_exp_sc'],
y = df_happiness['happiness']
)23.77700449624871Now we’ll calculate the loss for each guess and find which one gives us the smallest function value.
# Calculate the function value for each guess, mapping over
# each combination of b0 and b1
guesses = guesses |>
mutate(
objective = map2_dbl(
guesses$b0,
guesses$b1,
\(b0, b1) ols(
par = c(b0, b1),
X = df_happiness$life_exp_sc,
y = df_happiness$happiness
)
)
)
min_loss = guesses |> filter(objective == min(objective))
min_loss# A tibble: 1 × 3
b0 b1 objective
<dbl> <dbl> <dbl>
1 5.4 0.9 0.491# Calculate the function value for each guess, mapping over
# each combination of b0 and b1
guesses['objective'] = guesses.apply(
lambda x: ols(
par = x,
X = df_happiness['life_exp_sc'],
y = df_happiness['happiness']
),
axis = 1
)
min_loss = guesses[guesses['objective'] == guesses['objective'].min()]
min_loss b0 b1 objective
899 5.400 0.900 0.491The following plot shows the objective value for each guess in a smooth fashion as if we had a more continuous space. Darker values indicate we’re getting closer to our smallest objective value. The star notes our best guess.

Now let’s run the model using standard functions.
model_lr_happy_life = lm(happiness ~ life_exp_sc, data = df_happiness)
# not shown
c(
coef(model_lr_happy_life),
performance::performance_mse(model_lr_happy_life)
)model_lr_happy_life = sm.OLS(
df_happiness['happiness'],
sm.add_constant(df_happiness['life_exp_sc'])
).fit()
# not shown
model_lr_happy_life.params, model_lr_happy_life.scaleIf we inspect our results from the standard functions, we had estimates of 5.44 and 0.89 for our coefficients versus the best guess from our approach of 5.4 and 0.9. These are very similar but not exactly the same, but this is mostly due to the granularity of our guesses. Even so, in the end we can see that we get pretty dang close to what our basic lm or statsmodels functions would get us. Pretty neat!
6.6 Optimization
Before we get into other objective functions, let’s think about a better way to find good parameters for our model. Rather than just guessing, we can use a more systematic approach, and thankfully, there are tools out there to help us. We just use a function like our OLS function, give it a starting point, and let the algorithms do the rest! These tools eventually arrive at a pretty good set of parameters and are optimized for speed.
Previously we created a set of guesses and tried each one. This approach is often called a grid search, as we search over a grid of possible parameters as in Figure 6.2, and it is a bit of a brute-force approach to finding the best fitting model. You can maybe imagine a couple of unfortunate scenarios for this approach. One is just having a very large number of parameters to search, a common issue in deep learning. Or it may be that our range of guesses doesn’t allow us to find the right set of parameters. Or perhaps we specify a very large range, but the best fitting model is within a very narrow part of that, so that it takes a long time to find them. In any of these cases, we waste a lot of time or may not find an optimal solution.
In general, we can think of optimization as employing a smarter, more efficient way to find what you’re looking for. Here’s how it works:
- Start with an initial guess for the parameters.
- Calculate the objective function given the parameters.
- Update the parameters to a new guess (that hopefully improves the objective function).
- Repeat, until the improvement is small enough to not be worth continuing, or an arbitrary maximum number of iterations is reached.
With optimization, the key aspect is how we update the old parameters with a new guess at each iteration. Different optimization algorithms use different approaches to find those new guesses. The process stops when the improvement is smaller than a set tolerance level, or the maximum number of iterations is reached. If the objective is met, we say that our model has converged. Sometimes, the number of iterations is not enough for us to reach convergence in terms of tolerance, and we have to try again with a different set of parameters, a different algorithm, maybe use some data transformations, or something else.
So, let’s try it out! We start out with several inputs:
- the objective function,
- the initial guess for the parameters to get things going,
- other related inputs to the objective function, such as the data, and
- options for the optimization process, e.g., algorithm, maximum number of iterations, etc.
With these inputs, we’ll let the chosen optimization function do the rest of the work. We’ll again compare our results to the standard functions to make sure we’re on the right track.
We’ll use the optim function in R.
our_ols_optim = optim(
par = c(1, 0), # initial guess for the parameters
fn = ols,
X = df_happiness$life_exp_sc,
y = df_happiness$happiness,
method = 'BFGS', # optimization algorithm
control = list(
reltol = 1e-6, # tolerance
maxit = 500 # max iterations
)
)
our_ols_optimWe’ll use the minimize function in Python.
from scipy.optimize import minimize
our_ols_optim = minimize(
fun = ols,
x0 = np.array([1., 0.]), # initial guess for the parameters
args = (
np.array(df_happiness['life_exp_sc']),
np.array(df_happiness['happiness'])
),
method = 'BFGS', # optimization algorithm
tol = 1e-6, # tolerance
options = {
'maxiter': 500 # max iterations
}
)
our_ols_optimOptimization functions typically return multiple values, including the best parameters found, the value of the objective function at that point, and sometimes other information like the number of iterations it took to reach the returned value and whether or not the process converged. This can be quite a bit of stuff, so we don’t show the raw output, but we definitely encourage you to inspect it closely. The following table shows the estimated parameters and the objective value for our model, and we can compare it to the standard functions to see how we did.
| Parameter | Standard | Our Result |
|---|---|---|
| Intercept | 5.4450 | 5.4450 |
| Life Exp. Coef. | 0.8880 | 0.8880 |
| Objective/MSE | 0.4890 | 0.4890 |
So, our little function and the right tool allow us to come up with the same thing as base R and statsmodels! I hope you’re feeling pretty good at this point because you should! You just proved you could do what seemed before to be like magic, but really all it took is just a little knowledge about some key concepts to demystify the process. So, let’s keep going!
6.7 Maximum Likelihood
In our example, we’ve been minimizing the mean of the squared errors to find the best parameters for our model. But let’s think about this differently. Now we’d like you to think about the data generating process. Ignoring the model, imagine that each happiness value is generated by some random process, like drawing from a normal distribution. So, something like this would describe it mathematically:
\[ \text{happiness} \sim N(\text{mean}, \text{sd}) \]
where the mean is just the mean of happiness, and sd is its standard deviation. In other words, we can think of happiness as a random variable that is drawn from a normal distribution with mean and standard deviation as the parameters of that distribution.
Let’s apply this idea to our linear model setting. In this case, the mean is a function of life expectancy, and we’re not sure what the standard deviation is, but we can go ahead and write our model as follows.
\[ \text{mean} = \beta_0 + \beta_1 * \text{life\_exp} \] \[ \text{happiness} \sim N(\text{mean}, \text{sd}) \]
Now, our model is estimating the parameters of the normal distribution. We have an extra parameter to estimate: the standard deviation, which is similar to our RMSE.
In our analysis, instead of merely comparing the predicted happiness score to the actual score by looking at their difference, we do something a little different to get a sense of their correspondence. We consider how likely it is to observe the actual happiness score based on our prediction. The value known as the likelihood depends on our model’s parameters. The likelihood is determined by the statistical distribution we’ve selected for our analysis. We can write this as:
\[ \text{Pr}(\text{happiness} \mid \text{life\_exp}, \beta_0, \beta_1, \text{sd}) \]
\[ \text{Pr}(\text{happiness} \mid \text{mean}, \text{sd}) \]
Thinking more generally, the likelihood gives us the probability of the observed data given the parameter estimates.
\[ \text{Pr}(\text{Data} \mid \text{Parameters}) \]
The following shows how to calculate a likelihood for our model. The values you see are called probability density values. They’re not exactly probabilities, but they show the relative likelihood of each observation6. You can think of them like you do for probabilities, but remember that likelihoods are slightly different.
# two example life expectancy scores, at the mean (0) and 1 sd above
life_expectancy = c(0, 1)
# observed happiness scores
happiness = c(4, 5.2)
# predicted happiness with rounded coefs
mu = 5 + 1 * life_expectancy
# just a guess for sigma
sigma = .5
# likelihood for each observation
L = dnorm(happiness, mean = mu, sd = sigma)
L[1] 0.1080 0.2218from scipy.stats import norm
# two example life expectancy scores, at the mean (0) and 1 sd above
life_expectancy = np.array([0, 1])
# observed happiness scores
happiness = np.array([4, 5.2])
# predicted happiness with rounded coefs
mu = 5 + 1 * life_expectancy
# just a guess for sigma
sigma = .5
# likelihood for each observation
L = norm.pdf(happiness, loc = mu, scale = sigma)
Larray([0.1080, 0.2218])With a guess for the parameters and an assumption about the data’s distribution, we can calculate the likelihood of each data point, which is what our final result L shows. We eventually get a total likelihood for all observations, similar to how we added squared errors previously. But unlike errors, we want more likelihood, not less. In theory, we’d multiply each likelihood, but in practice we sum the log of the likelihood, otherwise values would get too small for our computers to handle. We can also turn our problem into a minimization problem by calculating the negative log-likelihood, and then minimizing that value, which many optimization algorithms are designed to do7.
The following is a function we can use to calculate the likelihood of the data given our parameters. This value, just like MSE, can also be used to compare models with different parameter guesses8. For the estimate of sigma, note that we are estimating its log value by exponentiating the parameter guess. This will keep it positive, as the standard deviation must be positive. We’ll hold off with our result until Table 6.4, which is shown next.
max_likelihood = function(par, X, y) {
# setup
X = cbind(1, X) # add a column of 1s for the intercept
beta = par[-1] # coefficients
sigma = exp(par[1]) # error sd, exp keeps positive
N = nrow(X)
LP = X %*% beta # linear predictor
mu = LP # identity link in the glm sense
# calculate (log) likelihood
ll = dnorm(y, mean = mu, sd = sigma, log = TRUE)
value = -sum(ll) # negative for minimization
return(value)
}
our_max_like = optim(
par = c(1, 0, 0), # first param is sigma
fn = max_likelihood,
X = df_happiness$life_exp_sc,
y = df_happiness$happiness
)
our_max_like
# logLik(model_lr_happy_life) # one way to extract the LL from a modeldef max_likelihood(par, X, y):
# setup
X = np.c_[np.ones(X.shape[0]), X] # add a column of 1s for the intercept
beta = par[1:] # coefficients
sigma = np.exp(par[0]) # error sd, exp keeps positive
N = X.shape[0]
LP = X @ beta # linear predictor
mu = LP # identity link in the glm sense
# calculate (log) likelihood
ll = norm.logpdf(y, loc = mu, scale = sigma)
value = -np.sum(ll) # negative for minimization
return value
our_max_like = minimize(
fun = max_likelihood,
x0 = np.array([1, 0, 0]), # first param is sigma
args = (
np.array(df_happiness['life_exp_sc']),
np.array(df_happiness['happiness'])
)
)
our_max_like# model_lr_happy_life.llf # one way to extract the log likelihood from a modelWe can compare our result to a built-in function that has capabilities beyond OLS, and the table shows we’re duplicating the basic result. We show more decimal places on the log-likelihood estimate to prove we aren’t getting exactly the same result.
| Parameter | Standard | Our Result |
|---|---|---|
| Intercept | 5.445 | 5.445 |
| Life Exp. Coef. | 0.888 | 0.888 |
| Sigma1 | 0.705 | 0.699 |
| LogLik (neg) | 118.804 | 118.804 |
| 1 Parameter estimate is exponentiated for the by-hand approach. | ||
To use a maximum likelihood approach for linear models, you can use functions like glm in R or GLM in Python, which is the reference used in the table above. We can also use different likelihoods corresponding to the binomial, Poisson and other distributions. Still other packages would allow even more distributions for consideration. In general, we choose a distribution that we feel best reflects the data generating process. For binary targets for example, we typically would feel a Bernoulli or binomial distribution is appropriate. For count data, we might choose a Poisson or negative binomial distribution. For targets that fall between 0 and 1, we might go for a beta distribution. You can see some of these demonstrated in Chapter 8.
There are many distributions to choose from, and the best one depends on your data. Sometimes, even if one distribution seems like a better fit, we might choose another one because it’s easier to use. Some distributions are special cases of others, or they might become more like a normal distribution under certain conditions. For example, the exponential distribution is a special case of the gamma distribution, and a t-distribution with many degrees of freedom looks like a normal distribution. Here is a visualization of the relationships among some of the more common distributions (Wikipedia (2023)).
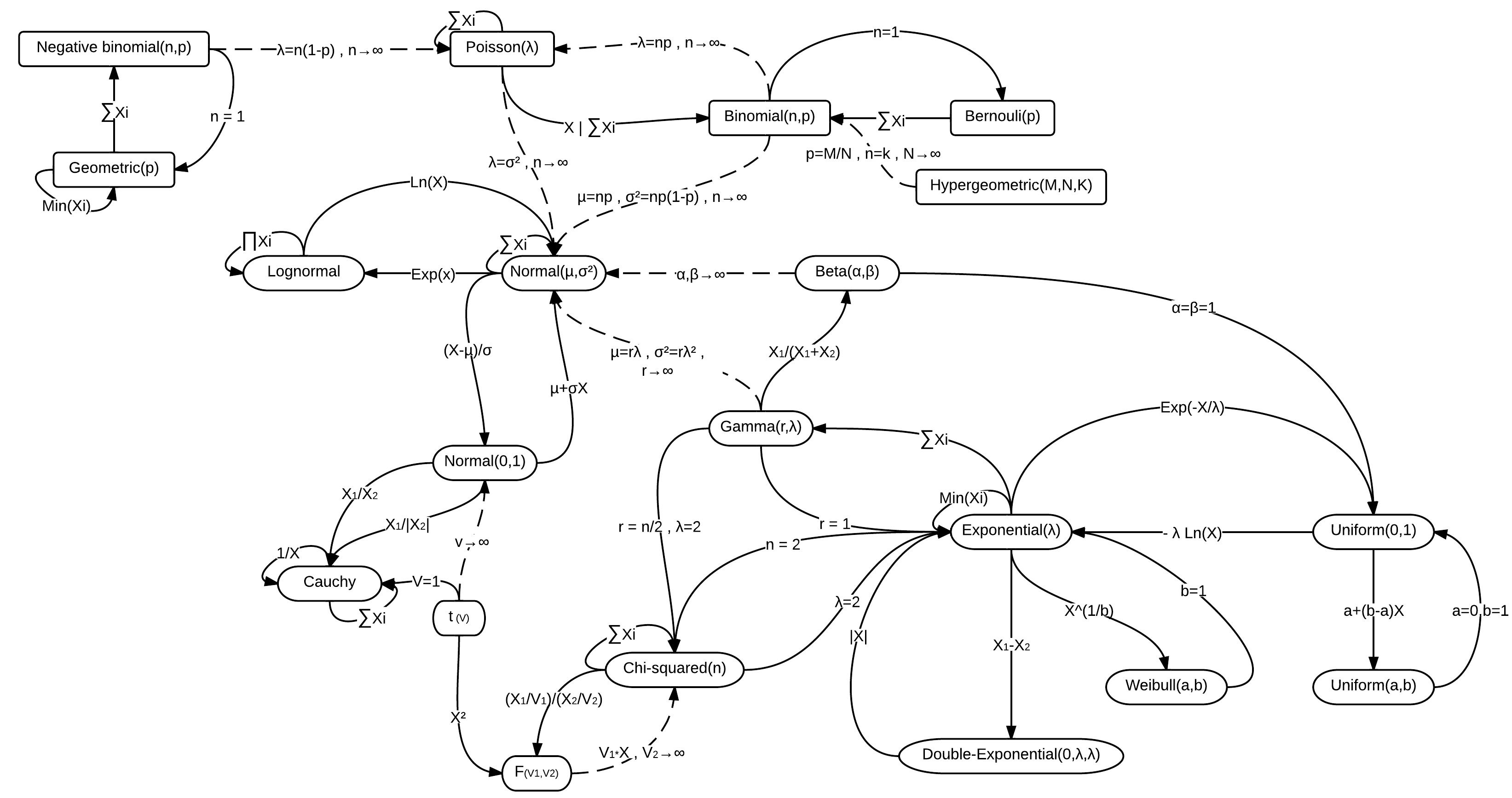
When you realize that many distributions are closely related, it’s easier to understand why we might choose one over another. But also, you can see why we might use a simpler option even if it’s not the best fit – you likely won’t come to a different practical conclusion about your model. Ultimately, you’ll get a better feel for this as you work with different types of data and models.
Here are examples of standard GLM functions, which just require an extra argument for the family of the distribution.
glm(happiness ~ life_exp_sc, data = df_happiness, family = gaussian)
glm(binary_target ~ x1 + x2, data = some_data, family = binomial)
glm(count ~ x1 + x2, data = some_data, family = poisson)import statsmodels.formula.api as smf
smf.glm(
'happiness ~ life_exp_sc',
data = df_happiness,
family = sm.families.Gaussian()
)
smf.glm(
'binary_target ~ x1 + x2',
data = some_data,
family = sm.families.Binomial()
)
smf.glm(
'count ~ x1 + x2',
data = some_data,
family = sm.families.Poisson()
)6.7.1 Diving deeper
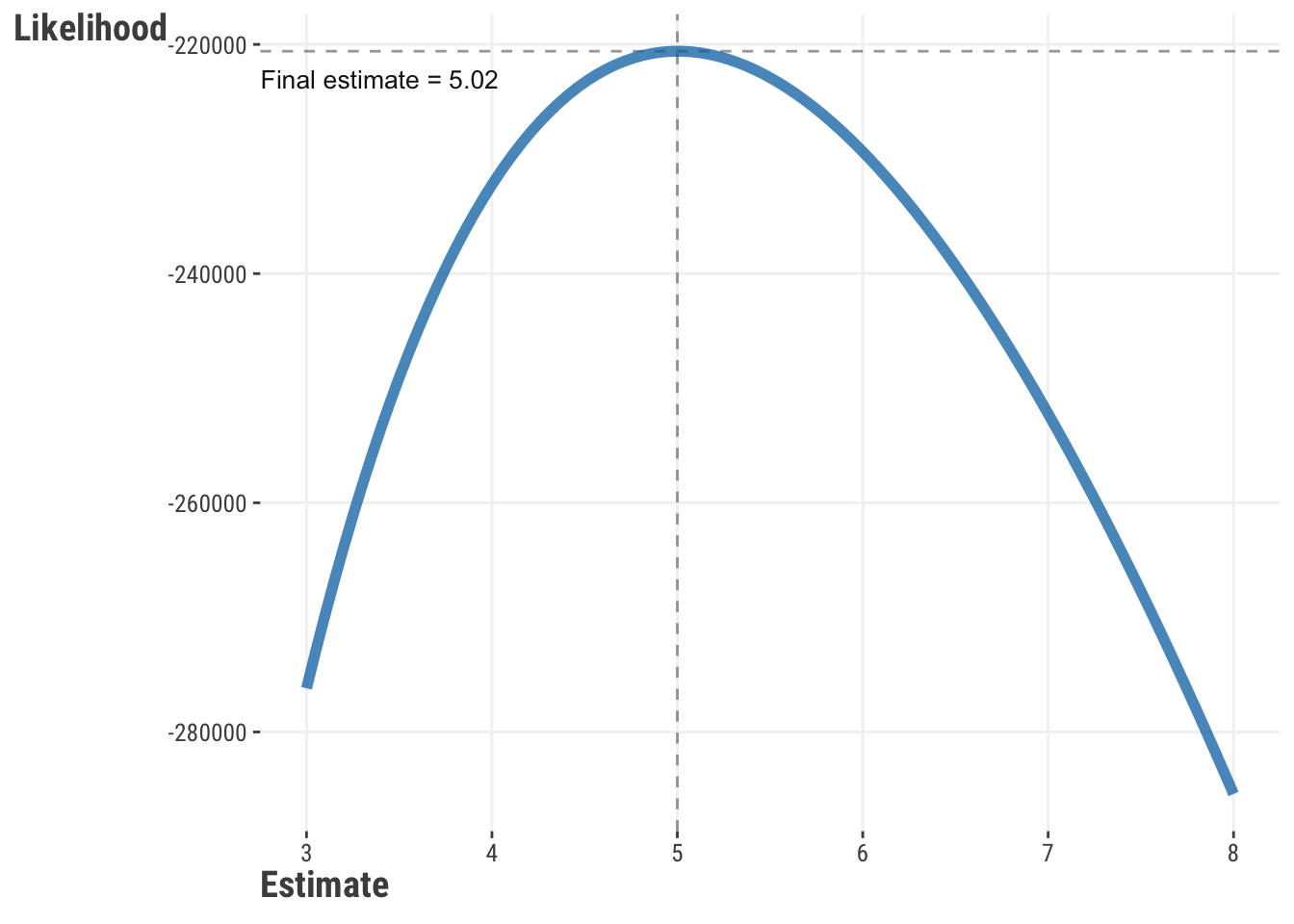
Let’s think more about what’s going on here, as it applies to estimation and optimization in general. It turns out that our objective function defines a ‘space’ or ‘surface’. You can imagine the process as searching for the lowest point on a landscape, with each guess a point on this landscape. Let’s start to get a sense of this with the following visualization, based on a single parameter. The following visualization shows this for a single parameter. The data comes from a variable with a true average of 5. As our guesses get closer to 5, the likelihood increases. However, with more and more data, the final guess converges on the true value. Model estimation finds that maximum on the curve, and optimization algorithms are the means to find it.
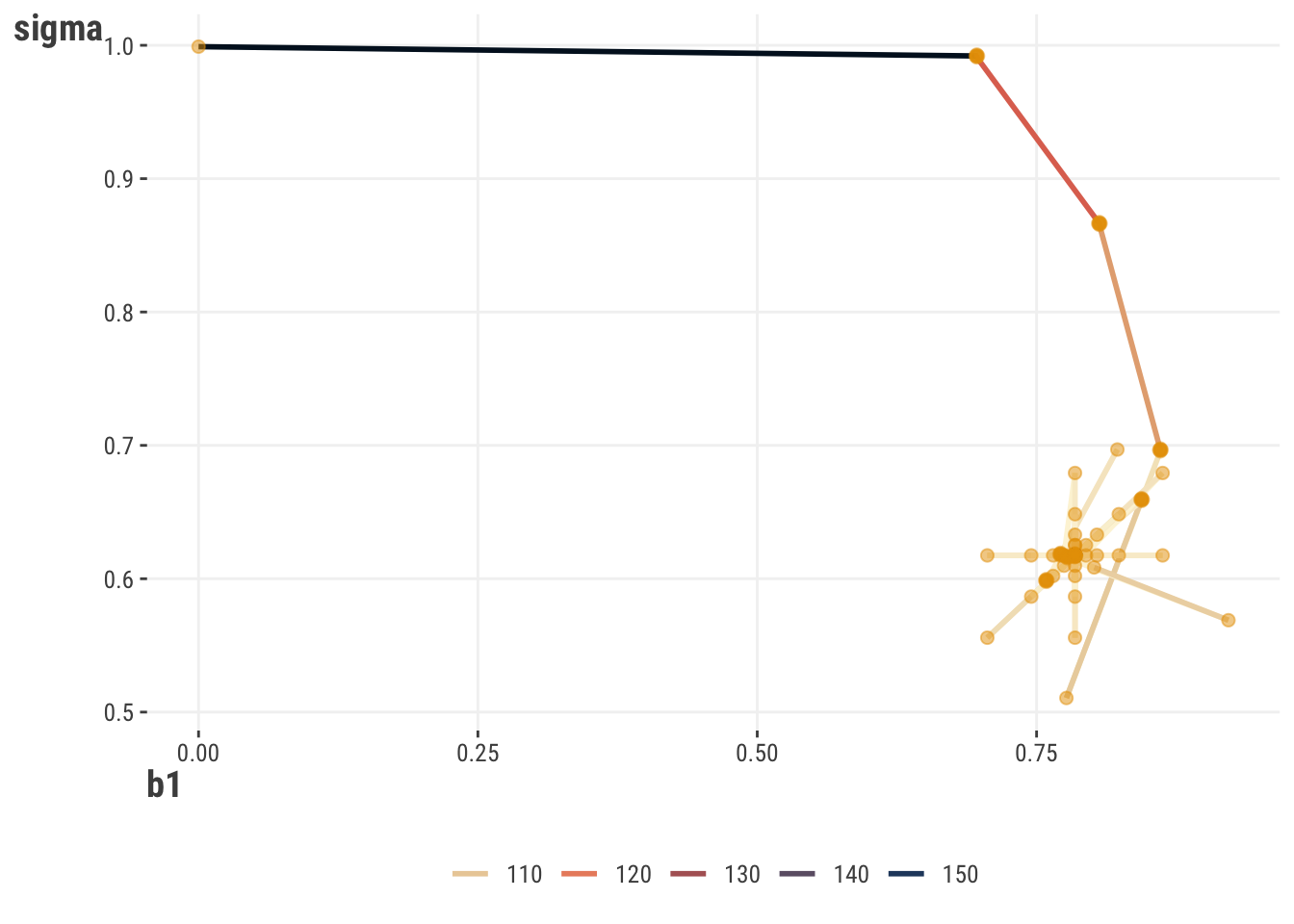
Now let’s add a parameter. If we have more than one parameter, we now have an objective surface to deal with. Given a starting point, an optimization procedure then travels along the surface looking for a minimum/maximum point. For simpler settings such as this, we can visualize the likelihood surface and its minimum point. However, even our simple model has three parameters plus the likelihood, so it would be difficult to visualize without additional complexity. Instead, we show the results for an alternate model where happiness is standardized also, which means the intercept is zero9, and so it is not shown.
We can also see the path our estimates take. Starting at a fairly bad estimate, the optimization algorithm quickly updates to estimates that result in a better likelihood value. We also see little exploratory jumps creating a star-like pattern, before things ultimately settle to the best values. In general, these updates and paths are dependent on the optimization algorithm one uses.
What we’ve shown here with maximum likelihood applies in general to searching for the best solution along an objective function surface. In most modeling circumstances, the surface is very complex with lots of points that might represent ‘local’ minimums, even though we’d ideally find the ‘global’ minimum. This is why we need optimization algorithms to help us find the best solution10. The optimization algorithms we’ll use are general purpose, and can be used for many different types of problems. The key is to define an appropriate objective function, and then let the algorithm do the work.
6.8 Penalized Objectives
One thing we may want to take into account with our models is their complexity, especially in the context of overfitting. We talk about this with machine learning also (Chapter 10), but the basic idea is that we can get too familiar with the data we have, and when we try to predict on new data the model hasn’t seen before, model performance suffers. In other words, we are not generalizing well (Section 10.4).
One way to deal with this is to penalize the objective function value for complexity, or at least favor simpler models that might do as well. In some contexts this is called regularization, and in other contexts shrinkage, since the parameter estimates are typically shrunk toward some specific value (e.g., zero).
As a starting point, in our basic linear model we can add a penalty that is applied to the size of coefficients. This is called ridge regression, or, more mathily, L2 regularization. We can write this formally as:
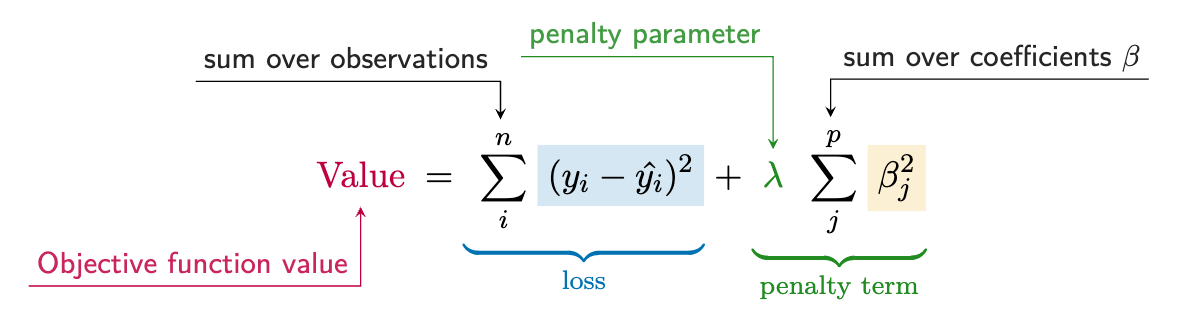
The first part is the same as basic OLS (Equation 6.1), but the second part is the penalty for \(p\) features. The penalty is the sum of the squared coefficients multiplied by some value, which we call \(\lambda\). This is an additional model parameter that we typically want to estimate, for example, through cross-validation. This kind of parameter is often called a hyperparameter, mostly just to distinguish it from those that may be of actual interest. For example, we could probably care less what the actual value for \(\lambda\) is, but we would still be interested in the coefficients.
In the end this is just a small change to OLS regression (Equation 6.1), but it can make a big difference. It introduces some bias in the coefficients – recall that OLS is unbiased if assumptions are met – but it can help to reduce variance, which can help the model perform better on new data (Section 10.4.2). In other words, we are willing to accept some bias in order to get a model that generalizes better.
But let’s get to an example to demystify this a bit! Here is an example of a function that calculates the ridge objective. To make things interesting, let’s add the other features we talked about regarding GDP per capita and perceptions of corruption.
ridge = function(par, X, y, lambda = 0) {
# add a column of 1s for the intercept
X = cbind(1, X)
mu = X %*% par # linear predictor
# Calculate the value as sum squared error
error = sum((y - mu)^2)
# Add the penalty
value = error + lambda * sum(par^2)
return(value)
}
X = df_happiness |>
select(-happiness, -country) |>
as.matrix()
our_ridge = optim(
par = c(0, 0, 0, 0),
fn = ridge,
X = X,
y = df_happiness$happiness,
lambda = 0.1,
method = 'BFGS'
)
our_ridge$par# we use lambda_ because lambda is a reserved word in Python
def ridge(par, X, y, lambda_ = 0):
# add a column of 1s for the intercept
X = np.c_[np.ones(X.shape[0]), X]
# Calculate the predicted values
mu = X @ par
# Calculate the error
value = np.sum((y - mu)**2)
# Add the penalty
value = value + lambda_ * np.sum(par**2)
return value
our_ridge = minimize(
fun = ridge,
x0 = np.array([0, 0, 0, 0]),
args = (
np.array(df_happiness.drop(columns=['happiness', 'country'])),
np.array(df_happiness['happiness']),
0.1
)
)
our_ridge['x']We can compare this to built-in functions as we have before11, and we can see that the results are very similar, but not exactly the same. We would not worry about such differences in practice, but the main point is again, that we can use simple functions that do just about as well as those from common packages.
| Parameter | Standard1 | Our Result |
|---|---|---|
| Intercept | 5.44 | 5.44 |
| life_exp_sc | 0.49 | 0.52 |
| corrupt_sc | −0.12 | −0.11 |
| gdp_pc_sc | 0.42 | 0.44 |
| 1 Showing results from the R glmnet package with alpha = 0, lambda = .1. | ||
Another very common penalized approach is to use the sum of the absolute value of the coefficients, which is called lasso regression or L1 regularization. An interesting property of the lasso is that in typical implementations, it will potentially produce a value of zero for some coefficients, which is the same as dropping the associated feature from the model altogether. This is a form of feature selection or variable selection. The true values are never zero, but if we want to use a ‘best subset’ of features, this is one way we could do so. We can write the lasso objective as follows. The chapter exercise asks you to implement this yourself.
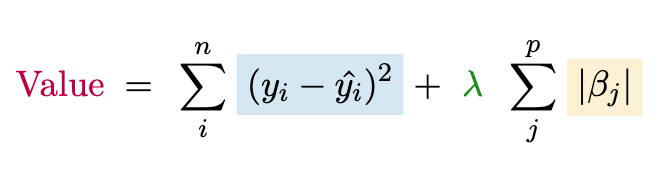
6.9 Classification
So far, we’ve been assuming a continuous target, but what if we have a categorical target? Now we have to learn a bunch of new stuff for that situation, right? Actually, no! When we want to model categorical targets, conceptually, nothing changes with our estimation approach! We still have an objective function that maximizes or minimizes some goal, and we can use the same algorithms to estimate parameters. However, we need to think about how we can do this in a way that makes sense for the binary target, or generalize to the multiclass case.
6.9.1 Misclassification rate
A straightforward correspondence to common loss functions we’ve seen is a function that minimizes classification error, or by the same token, maximizes accuracy. In other words, we can think of the objective function as the proportion of incorrect classifications. This is called the misclassification rate.
\[ \text{Value} = \frac{1}{n} \sum_{i=1}^{n} \mathbb{1}(y_i \neq \hat{y_i}) \tag{6.2}\]
In the equation, \(y_i\) is the actual value of the target for observation \(i\), arbitrarily coded as 1 or 0, and \(\hat{y_i}\) is the predicted class from the model. The \(\mathbb{1}\) is an indicator function that returns 1 if the condition is true, and 0 otherwise. In other words, we are counting the number of times the predicted value is not equal to the actual value, and dividing by the number of observations. Very straightforward, so let’s do this ourselves!
misclassification = function(par, X, y, class_threshold = .5) {
X = cbind(1, X)
# Calculate the 'linear predictor'
mu = X %*% par
# Convert to a probability ('sigmoid' function)
p = 1 / (1 + exp(-mu))
# Convert to a class
predicted_class = as.integer(
ifelse(p > class_threshold, 'good', 'bad')
)
# Calculate the mean error
value = mean(y - predicted_class)
return(value)
}def misclassification_rate(par, X, y, class_threshold = .5):
# add a column of 1s for the intercept
X = np.c_[np.ones(X.shape[0]), X]
# Calculate the 'linear predictor'
mu = X @ par
# Convert to a probability ('sigmoid' function)
p = 1 / (1 + np.exp(-mu))
# Convert to a class
predicted_class = np.where(p > class_threshold, 1, 0)
# Calculate the mean error
value = np.mean(y - predicted_class)
return valueNote that our function first adds a step to convert the linear combination of features, the linear predictor (called mu), to a probability. Once we have a probability, we use some threshold to convert it to a ‘class’. In this case, we use 0.5 as the threshold, but this could be different depending on the context, something we talk more about elsewhere (Section 4.2.2). We’ll leave it as an exercise for you to play around with this function, as the next objective function is far more commonly used. But at least you can see how easy it can be to switch from a numeric target to the classification case.
6.9.2 Log loss
A very common objective function for classification is log loss, sometimes called logistic loss, or cross-entropy12. For a binary target, it is:
\[ \text{Value} = -\sum_{i=1}^{n} y_i \log(\hat{y_i}) + (1 - y_i) \log(1 - \hat{y_i}) \tag{6.3}\]
Where \(y_i\) is the actual value of the target for observation \(i\), and \(\hat{y_i}\) is the predicted value from the model (essentially a probability). It turns out that this is the same as the log-likelihood used in a maximum likelihood approach for logistic regression, made negative so we can minimize it.
We typically prefer this objective function to classification error because it results in a smooth optimization surface, like in the visualization we showed before for maximum likelihood (Section 6.7.1), which means it is differentiable in a mathematical sense. This is important because it allows us to use optimization algorithms that rely on derivatives in updating the parameter estimates. You don’t really need to get into that too much, but just know that a smoother objective function is something we prefer. Here’s some code to try out.
log_loss = function(par, X, y) {
X = cbind(1, X)
# Calculate the predicted values on the raw scale
y_hat = X %*% par
# Convert to a probability ('sigmoid' function)
y_hat = 1 / (1 + exp(-y_hat))
# likelihood
ll = y * log(y_hat) + (1 - y) * log(1 - y_hat)
# alternative
# dbinom(y, size = 1, prob = y_hat, log = TRUE)
value = -sum(ll)
return(value)
}def log_loss(par, X, y):
# add a column of 1s for the intercept
X = np.c_[np.ones(X.shape[0]), X]
# Calculate the predicted values
y_hat = X @ par
# Convert to a probability ('sigmoid' function)
y_hat = 1 / (1 + np.exp(-y_hat))
# likelihood
ll = y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat)
value = -np.sum(ll)
return valueLet’s go ahead and demonstrate this. To create a classification problem, we’ll say that a country is ‘happy’ if the happiness score is greater than 5.5, and ‘unhappy’ otherwise. We’ll use the same features as before.
df_happiness_bin = df_happiness |>
mutate(happiness = ifelse(happiness > 5.5, 1, 0))
model_logloss = optim(
par = c(0, 0, 0, 0),
fn = log_loss,
X = df_happiness_bin |>
select(life_exp_sc:gdp_pc_sc) |>
as.matrix(),
y = df_happiness_bin$happiness
)
model_glm = glm(
happiness ~ life_exp_sc + corrupt_sc + gdp_pc_sc,
data = df_happiness_bin,
family = binomial
)
model_logloss$pardf_happiness_bin = df_happiness.copy()
df_happiness_bin['happiness'] = np.where(df_happiness['happiness'] > 5.5, 1, 0)
model_logloss = minimize(
log_loss,
x0 = np.array([0, 0, 0, 0]),
args = (
df_happiness_bin[['life_exp_sc', 'corrupt_sc', 'gdp_pc_sc']],
df_happiness_bin['happiness']
)
)
model_glm = smf.glm(
'happiness ~ life_exp_sc + corrupt_sc + gdp_pc_sc',
data = df_happiness_bin,
family = sm.families.Binomial()
).fit()
model_logloss['x']Once again, we can see that the results are very similar between our classification result and the built-in function.
| parameter | Standard | Our result |
|---|---|---|
| LogLike | 40.6635 | 40.6635 |
| intercept | −0.1637 | −0.1642 |
| life_exp_sc | 1.8172 | 1.8168 |
| corrupt_sc | −0.4648 | −0.4638 |
| gdp_pc_sc | 1.1311 | 1.1307 |
So, when it comes to classification, you should feel confident in what’s going on under the hood, just like you did with a numeric target. Too much is made of the distinction between ‘regression’ and ‘classification’, and it can be confusing to those starting out. In reality, classification just requires a slightly different way of thinking about the target, not something fundamentally different about the modeling process.
6.10 Optimization Algorithms
When it comes to optimization, there are many algorithms that have been developed over time. The main thing to keep in mind is that these are all just different ways to find the best fitting parameters for a model. Some may be better suited for certain data tasks, or provide computational advantages, but usually the choice of algorithm is not as important as many other modeling choices you’ll have to make.
6.10.1 Common methods
Here are some of the options available in R’s optim or scipy’s minimize function. In addition, they are commonly used behind the scenes in many modeling functions.
- Nelder-Mead
- BFGS
- L-BFGS-B (provides constraints)
- Conjugate gradient
- Simulated annealing
- Newton’s method
Other common optimization methods include:
- Genetic algorithms
- Other popular SGD extensions and variants
- RMSProp
- Adam/momentum
- AdaGrad
The main reason to choose one method over another usually is based on factors like speed, memory use, or how well the method works for certain models. For statistical contexts, many functions for generalized linear models use Newton’s method by default, but more complicated models, for example, mixed models, may implement a different approach for better convergence. In machine learning, stochastic gradient descent is popular because it can be relatively efficient in large data settings and easy to implement.
In general, we can always try different methods to see which works best, but usually the results will be similar if the results reach convergence. We’ll now demonstrate one of more common methods to get a sense of how these work.
6.10.2 Gradient descent
One of the most popular approaches in optimization is called gradient descent. It uses the gradient of the function we’re trying to optimize to find the best parameters. We still use objective functions as before, and gradient descent is just a way to find that path along the objective function surface as we discussed previously in the deep dive (Section 6.7.1).
More formally, the gradient is the vector of partial derivatives of the objective function with respect to each parameter. That may not mean much to you, but the basic idea is that the gradient provides a direction that points in the direction of steepest increase in the function. So if we want to maximize the objective function, we can take a step in the direction of the gradient, and if we want to minimize it, we can take a step in the opposite direction of the gradient (use the negative gradient).
The size of the ‘step’ is called the learning rate. Like the penalty parameter we saw with penalized regression, it is a hyperparameter that we can tune through cross-validation (Section 10.7). If the learning rate is too small, it will take a longer time to converge. If it’s too large, we might overshoot the objective and miss the best parameters. There are a number of variations on gradient descent that have been developed over time. Let’s see this in action with the world happiness model.
gradient_descent = function(
par,
X,
y,
tolerance = 1e-3,
maxit = 1000,
learning_rate = 1e-3
) {
X = cbind(1, X) # add a column of 1s for the intercept
N = nrow(X)
# initialize
beta = par
names(beta) = colnames(X)
mse = crossprod(X %*% beta - y) / N # crossprod provides sum(x^2)
tol = 1
iter = 1
while (tol > tolerance && iter < maxit) {
LP = X %*% beta
grad = t(X) %*% (LP - y)
betaCurrent = beta - learning_rate * grad
tol = max(abs(betaCurrent - beta))
beta = betaCurrent
mse = append(mse, crossprod(LP - y) / N)
iter = iter + 1
}
output = list(
par = beta,
loss = mse,
MSE = crossprod(LP - y) / nrow(X),
iter = iter,
predictions = LP
)
return(output)
}def gradient_descent(
par,
X,
y,
tolerance = 1e-3,
maxit = 1000,
learning_rate = 1e-3
):
# add a column of 1s for the intercept
X = np.c_[np.ones(X.shape[0]), X]
# initialize
beta = par
loss = np.sum((X @ beta - y)**2)
tol = 1
iter = 1
while (tol > tolerance and iter < maxit):
LP = X @ beta
grad = X.T @ (LP - y)
betaCurrent = beta - learning_rate * grad
tol = np.max(np.abs(betaCurrent - beta))
beta = betaCurrent
loss = np.append(loss, np.sum((LP - y)**2))
iter = iter + 1
output = {
'par': beta,
'loss': loss,
'MSE': np.mean((LP - y)**2),
'iter': iter,
'predictions': LP
}
return outputWith our functions in hand, let’s apply them to the world happiness data. We’ll keep the default settings, but feel free to play around with the learning_rate and tolerance parameters.
X = df_happiness |>
select(life_exp_sc:gdp_pc_sc) |>
as.matrix()
our_gd = gradient_descent(
par = c(0, 0, 0, 0),
X = X,
y = df_happiness$happiness
)our_gd = gradient_descent(
par = np.array([0, 0, 0, 0]),
X = df_happiness[['life_exp_sc', 'corrupt_sc', 'gdp_pc_sc']].to_numpy(),
y = df_happiness['happiness'].to_numpy()
)We compare our results in Table 6.7. As usual, we see that the results are very similar to the standard linear regression approach. Once again, we have demystified a step in the modeling process!
| Value | Standard | Our Result |
|---|---|---|
| Intercept | 5.445 | 5.437 |
| life_exp_sc | 0.525 | 0.521 |
| corrupt_sc | −0.105 | −0.107 |
| gdp_pc_sc | 0.438 | 0.439 |
| MSE | 0.367 | 0.367 |
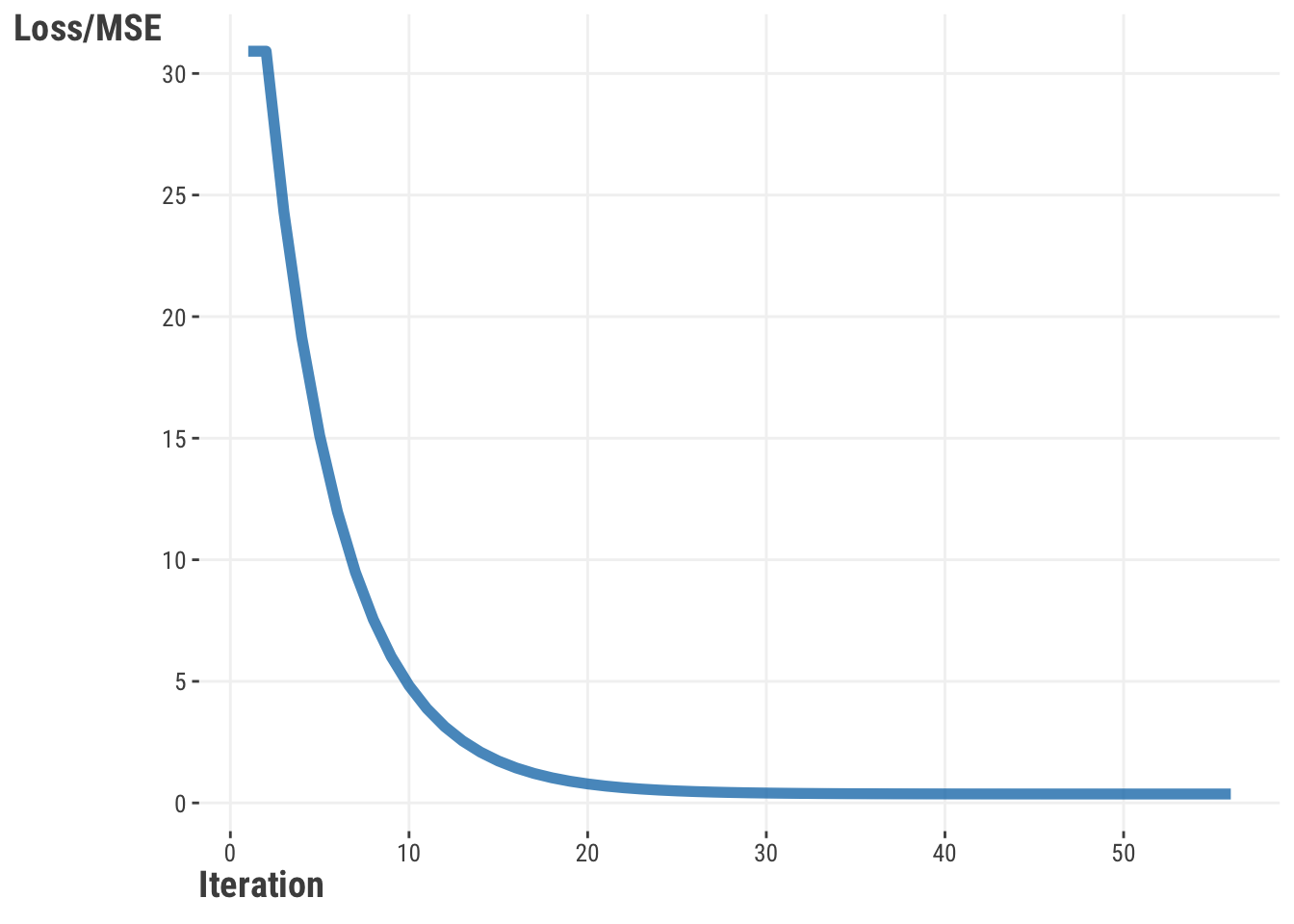
In addition, when we visualize the loss function across iterations, we see a smooth decline in the MSE value as we go along each iteration (Figure 6.7). This is a good sign that we are converging to an optimal solution.
6.10.3 Stochastic gradient descent
Stochastic gradient descent (SGD) is a version of gradient descent that uses a random sample of data to calculate the gradient, instead of using all the data. This makes it less accurate in some ways, but it’s faster and can be parallelized across the CPU/GPU cores of the computing hardware environment. This speed is useful in machine learning when there’s a lot of data, which often makes the discrepancy of results small between standard GD and SGD. As such, you will see variants of it incorporated in many models in deep learning, but know that it can be used with much simpler models as well.
Let’s see this in action with the happiness model. The following is a conceptual version of the AdaGrad approach13, which is a variation of SGD that adjusts the learning rate for each parameter. We will also add a variation that you can explore that averages the parameter estimates across iterations, which is a common approach to improve the performance of SGD.
We are going to use a batch size of one, which is similar to a ‘streaming’ or ‘online’ version where we update the model with each observation. Since our data are alphabetically ordered, we’ll shuffle the data first. We’ll also use a stepsize_tau parameter, which is a way to adjust the learning rate at early iterations. The values for the learning rate and stepsize_tau are arbitrary, selected after some initial playing around, but you can play with them to see how they affect the results.
stochastic_gradient_descent = function(
par, # parameter estimates
X, # model matrix
y, # target variable
learning_rate = 1, # the learning rate
stepsize_tau = 0, # if > 0, a check on the LR at early iterations
seed = 123
) {
# initialize
set.seed(seed)
# shuffle the data
idx = sample(1:nrow(X), nrow(X))
X = X[idx, ]
y = y[idx]
X = cbind(1, X)
beta = par
# Collect all estimates
betamat = matrix(0, nrow(X), ncol = length(beta))
# Collect fitted values at each point))
fits = NA
# Collect loss at each point
loss = NA
# adagrad per parameter learning rate adjustment
s = 0
# a smoothing term to avoid division by zero
eps = 1e-8
for (i in 1:nrow(X)) {
Xi = X[i, , drop = FALSE]
yi = y[i]
# matrix operations not necessary here,
# but makes consistent with previous gd func
LP = Xi %*% beta
grad = t(Xi) %*% (LP - yi)
s = s + grad^2 # adagrad approach
# update
beta = beta - learning_rate /
(stepsize_tau + sqrt(s + eps)) * grad
betamat[i, ] = beta
fits[i] = LP
loss[i] = crossprod(LP - yi)
}
LP = X %*% beta
lastloss = crossprod(LP - y)
output = list(
par = beta, # final estimates
par_chain = betamat, # estimates at each iteration
MSE = sum(lastloss) / nrow(X),
predictions = LP
)
return(output)
}def stochastic_gradient_descent(
par, # parameter estimates
X, # model matrix
y, # target variable
learning_rate = 1, # the learning rate
stepsize_tau = 0, # if > 0, a check on the LR at early iterations
average = False # a variation of the approach
):
# initialize
np.random.seed(1234)
# shuffle the data
idx = np.random.choice(
df_happiness.shape[0],
df_happiness.shape[0],
replace = False
)
X = X[idx, :]
y = y[idx]
X = np.c_[np.ones(X.shape[0]), X]
beta = par
# Collect all estimates
betamat = np.zeros((X.shape[0], beta.shape[0]))
# Collect fitted values at each point))
fits = np.zeros(X.shape[0])
# Collect loss at each point
loss = np.zeros(X.shape[0])
# adagrad per parameter learning rate adjustment
s = 0
# a smoothing term to avoid division by zero
eps = 1e-8
for i in range(X.shape[0]):
Xi = X[None, i, :]
yi = y[i]
# matrix operations not necessary here,
# but makes consistent with previous gd func
LP = Xi @ beta
grad = Xi.T @ (LP - yi)
s = s + grad**2 # adagrad approach
# update
beta = beta - learning_rate / \
(stepsize_tau + np.sqrt(s + eps)) * grad
betamat[i, :] = beta
fits[i] = LP
loss[i] = np.sum((LP - yi)**2)
LP = X @ beta
lastloss = np.sum((LP - y)**2)
output = {
'par': beta, # final estimates
'par_chain': betamat, # estimates at each iteration
'MSE': lastloss / X.shape[0],
'predictions': LP
}
return outputLet’s now use the functions as we did before. We’ll show the results in Table 6.8.
X = df_happiness |>
select(life_exp_sc, corrupt_sc, gdp_pc_sc) |>
as.matrix()
y = df_happiness$happiness
our_sgd = stochastic_gradient_descent(
par = c(mean(df_happiness$happiness), 0, 0, 0),
X = X,
y = y,
learning_rate = .15,
stepsize_tau = .1
)
c(our_sgd$par, our_sgd$MSE)X = df_happiness[['life_exp_sc', 'corrupt_sc', 'gdp_pc_sc']].to_numpy()
y = df_happiness['happiness'].to_numpy()
our_sgd = stochastic_gradient_descent(
par = np.array([np.mean(df_happiness['happiness']), 0, 0, 0]),
X = X,
y = y,
learning_rate = .15,
stepsize_tau = .1
)
our_sgd['par'], our_sgd['MSE']Now we’ll compare it to OLS estimates and our previous ‘batch’ gradient descent results. Even though SGD normally would not be used for such a small dataset, we at least get close14!
| Value | Standard | Our Result | Batch SGD |
|---|---|---|---|
| Intercept | 5.445 | 5.469 | 5.437 |
| life_exp_sc | 0.525 | 0.514 | 0.521 |
| corrupt_sc | −0.105 | −0.111 | −0.107 |
| gdp_pc_sc | 0.438 | 0.390 | 0.439 |
| MSE | 0.367 | 0.370 | 0.367 |
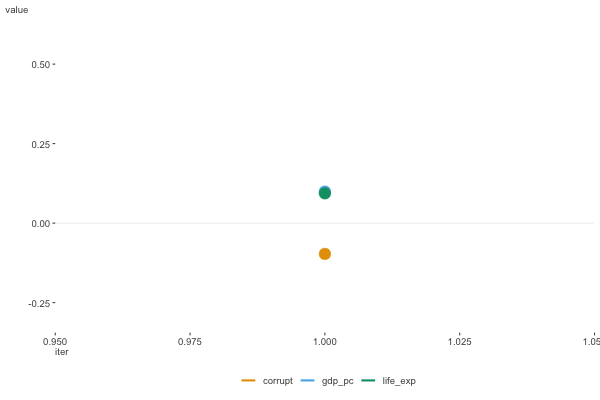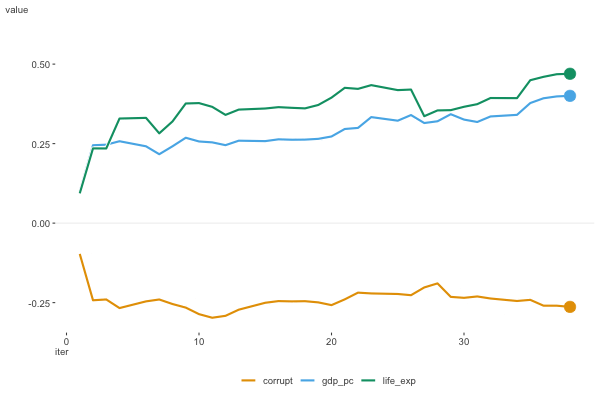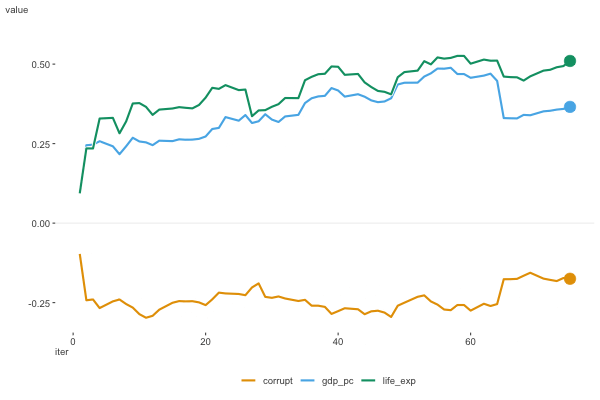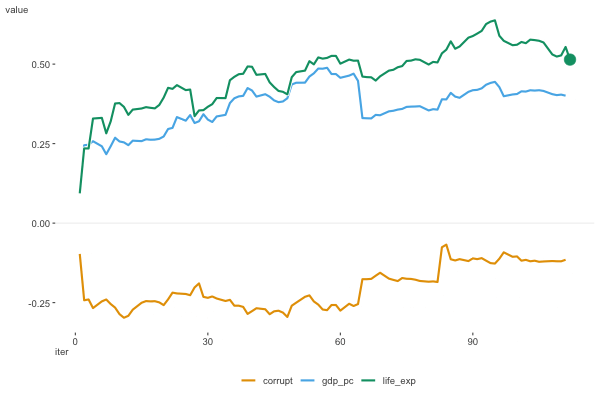
Figure 6.8 shows the estimates as they moved along the data. For this plot we don’t include the intercept, as it’s on a notably different scale. We can see that the estimates are moving around a bit, but they appear to be converging to a solution.
To wrap things up, here are the results for the happiness model using different optimization algorithms, with a comparison to the standard linear regression model function. We can see that the results are very similar, and for simpler modeling endeavors they should converge on the same result.
| parameter | NM1 | BFGS2 | CG3 | GD4 | Standard5 |
|---|---|---|---|---|---|
| Intercept | 5.445 | 5.445 | 5.445 | 5.437 | 5.445 |
| life_exp_sc | 0.525 | 0.525 | 0.525 | 0.521 | 0.525 |
| gdp_pc_sc | −0.105 | −0.105 | −0.105 | −0.107 | −0.105 |
| corrupt_sc | 0.437 | 0.438 | 0.438 | 0.439 | 0.438 |
| MSE | 0.367 | 0.367 | 0.367 | 0.367 | 0.367 |
| 1 NM = Nelder-Mead | |||||
| 2 BFGS = Broyden–Fletcher–Goldfarb–Shanno | |||||
| 3 CG = Conjugate gradient | |||||
| 4 GD = Our gradient descent function | |||||
| 5 Standard = Standard package function | |||||
Before leaving our estimation discussion, we should mention there are other approaches one could use to estimate model parameters, including variations on least squares, the method of moments, generalized estimating equations, robust estimation, and more. We’ve focused on the most common ones generally, but it’s good to be aware of others that might be more popular in some domains.
6.11 Wrapping Up
Wow, we covered a lot here! But this is the sort of stuff that can take you from just having some fun with data, to doing that and also understanding how things are actually happening. Just having the basics of how modeling actually is done ‘under the hood’ makes so many other things make sense, and it can give you a lot of confidence, even in less familiar modeling domains.
6.11.1 The common thread
Simply put, the content in this chapter ties together any and every model you will ever undertake, from linear regression to reinforcement learning, computer vision, and large language models. Estimation and optimization are the core of any modeling process, and understanding the basics is key to understanding how models work in general.
6.11.2 Choose your own adventure
Seriously, after this chapter, you should feel fine with any of the others in this book, so dive in!
6.11.3 Additional resources
OLS and Maximum Likelihood Estimation:
For OLS and maximum likelihood estimation, there are so many resources out there, so we recommend just taking a look and seeing which one suits you best. Practically any more technically-oriented statistical book will cover these topics in detail.
Gradient Descent:
- Gradient Descent, Step-by-Step StatQuest with Josh Starmer (2019a)
- Stochastic Gradient Descent, Clearly Explained StatQuest with Josh Starmer (2019b)
- A Visual Explanation of Gradient Descent Methods Jiang (2020)
More demonstration of the simple AdaGrad algorithm used above:
6.12 Guided Exploration
For this exercise, you’ll have two tasks:
Try creating an objective function for a continuous target that uses the mean absolute error, and compare your estimated parameters to the previous results for ordinary least squares. Use the OLS function from the chapter as a basis (Section 6.5), but modify it for the new objective.
Use the estimation function we demonstrated for ridge regression (Section 6.8) and change it to use the lasso approach.
Both of these can be done by changing one line in the previous functions used.
Since life expectancy is scaled, a standard deviation is 1, and in this case represents about 7 years.↩︎
It turns out that our error metric is itself an estimate of the true error. We’ll get more into this later, but for now this means that we can’t ever know the true error, and so we can’t ever really know the best or true model. However, we can still choose a good or better model relative to others based on our error estimate.↩︎
We don’t have to do it this way, but it’s the default in most scenarios. As an example, maybe for your situation, overshooting is worse than undershooting, and so you might want to use an approach that would weight those errors more heavily.↩︎
Some disciplines seem to confuse models with estimation methods and link functions. It doesn’t really make sense, nor is it informative, to call something an OLS model or a logit model. Many models are estimated using a least squares objective function, even deep learning, and different types of models use a logit link, from logistic regression, to beta regression, to activation functions used in deep learning.↩︎
You may find that some packages will only minimize (or maximize) a function, even to the point of reporting nonsensical things like negative squared values, so you’ll need to take care when implementing your own metrics.↩︎
The actual probability of a specific value in this setting is 0, but the probability of a range of values is greater than 0. You can find out more about likelihoods and probabilities at the StackExchange discussion on the difference between likelihood and probability, but many traditional statistical texts will cover this also.↩︎
The negative log-likelihood is often what is reported in the model output as well.↩︎
Those who have experience here will notice we aren’t putting a lower bound on sigma. You typically want to do this, otherwise you may get nonsensical results by not keeping sigma positive. You can do this by setting a specific argument for an algorithm that uses boundaries, or more simply by exponentiating the parameter so that it can only be positive. In the latter case, you’ll have to exponentiate the final parameter estimate to get back to the correct scale. We leave this detail out of the code for now to keep things simple.↩︎
Linear regression will settle on a line that cuts through the means, and when standardizing all variables, the mean of the features and target are both zero, so the line goes through the origin.↩︎
There is no way to know if we have found a global minimum, and truthfully, we probably rarely do with complex models. But optimization algorithms are designed to find the best solution they can under the data circumstances, and some minimums may be practically indistinguishable from the global minimum anyway (we hope!).↩︎
For R, one can use the glmnet, while for Python, the Ridge class in scikit-learn is a good choice.↩︎
A nice demo from the pytorch perspective can be found at Raschka (2022).↩︎
MC wrote this function a long time ago but does not recall exactly what the origin is, except that Murphy’s PML book was something he was poring through at the time (Murphy (2012)).↩︎
You’d get better results in a couple of ways. The easiest is just to repeat the process a couple of times and average the results. This is a common approach in SGD. The initial shuffling that we did can help with convergence as well, and it would be done each repetition. With larger data and repeated runs/epochs, shuffling allows the samples/batches to be more representative of the entire dataset. Also, we ‘hand-tune’ our learning rate and step size here, but normally we’d use cross-validation to find the best values.↩︎