Machine Learning
Machine learning (ML) encompasses a wide variety of techniques, from standard regression models to almost impenetrably complex modeling tools. While it may seem like magic to the uninitiated, the main thing that distinguishes it from standard statistical methods discussed thus far is an approach that heavily favors prediction over inference and explanatory power, and which takes the necessary steps to gain any predictive advantage38.
ML could potentially be applied in any setting, but typically works best with data sets much larger than classical statistical methods are usually applied to. However, nowadays even complex regression models can be applied to extremely large data sets, and properly applied ML may even work in simpler data settings, so this distinction is muddier than it used to be. The main distinguishing factor is mostly one of focus.
The following only very briefly provides a demonstration of concepts and approaches. I have more in-depth document available for more details.
Concepts
Loss
We discussed loss functions before, and there was a reason I went more in depth there, mainly because I feel, unlike with ML, loss is not explicitly focused on as much in applied research, leaving the results produced to come across as more magical than it should be. In ML however, we are explicitly concerned with loss functions and, more specifically, evaluating loss on test data. This loss is evaluated over successive iterations of a particular technique, or averaged over several test sets via cross-validation. Typical loss functions are Root Mean Squared Error for numeric targets (essentially the same as for a standard linear model), and cross-entropy for categorical outcomes. There are robust alternatives, such as mean absolute error and hinge loss functions respectively, and many other options besides. You will come across others that might be used for specific scenarios.
The following image, typically called a learning curve, shows an example of loss on a test set as a function of model complexity. In this case, models with more complexity perform better, but only to a point, before test error begins to rise again.

Bias-variance tradeoff
Prediction error, i.e. loss, is composed of several sources. One part is measurement error, which we can’t do anything about, and two components of specific interest: bias, the difference in the observed value and our average predicted value, and variance how much that prediction would change had we trained on different data. More generally we can think of this as a problem of underfitting vs. overfitting. With a model that is too simple, we underfit, and bias is high. If we overfit, the model is too close to the training data, and likely will do poorly with new observations. ML techniques trade some increased bias for even greater reduced variance, which often means less overfitting to the training data, leading to increased performance on new data.
In the following39, the blue line represents models applied to training data, while the red line regards performance on the test set. We can see that for the data we train the model to, error will always go down with increased complexity. However, we can see that at some point, the test error will increase as we have started to overfit to the training data.

Regularization
As we have noted, a model fit to a single data set might do very well with the data at hand, but then suffer when predicting independent data. Also, oftentimes we are interested in a ‘best’ subset of predictors among a great many, and typically the estimated coefficients from standard approaches are overly optimistic unless dealing with sufficiently large sample sizes. This general issue can be improved by shrinking estimates toward zero, such that some of the performance in the initial fit is sacrificed for improvement with regard to prediction. The basic idea in terms of the tradeoff is that we are trading some bias for notably reduced variance. We demonstrate regularized regression below.
Cross-validation
Cross-validation is widely used for validation and/or testing. With validation, we are usually concerned with picking parameter settings for the model, while the testing is used for ultimate assessment of model performance. Conceptually there is nothing new beyond what was discussed previously regarding holding out data for assessing predictive performance, we just do more of it.
As an example, let’s say we split our data into three parts. We use two parts (combined) as our training data, then the third part as test. At this point this is identical to our demonstration before. But then, we switch which part is test and which two are training, and do the whole thing over again. And finally once more, so that each of our three parts has taken a turn as a test set. Our estimated error is the average loss across the three times.

Typically we do it more than three times, usually 10, and there are fancier methods of k-fold cross-validation, though they typically don’t serve to add much value. In any case, let’s try it with our previous example. The following uses the tidymodels approach to be consistent with early chapters use of the tidyverse40. With it we can employ k-fold cross validation to evaluate the loss.
# install.packages(tidymodels) # if needed
library(tidymodels)
load('data/world_happiness.RData')
set.seed(1212)
# specify the model
happy_base_spec = linear_reg() %>%
set_engine(engine = "lm")
# by default 10-folds
happy_folds = vfold_cv(happy)
library(tune)
happy_base_results = fit_resamples(
happy_base_spec,
happiness_score ~ democratic_quality + generosity + log_gdp_per_capita,
happy_folds,
control = control_resamples(save_pred = TRUE)
)
cv_res = happy_base_results %>%
collect_metrics()| .metric | .estimator | mean | n | std_err |
|---|---|---|---|---|
| rmse | standard | 0.629 | 10 | 0.022 |
| rsq | standard | 0.697 | 10 | 0.022 |
We now see that our average test error is 0.629. It also gives the average R2.
Optimization
With ML, much more attention is paid to different optimizers, but the vast majority for deep learning and other many other methods are some flavor of stochastic gradient descent. Often due to the sheer volume of data/parameters, this optimization is done on chunks of the data and in parallel. In general, some optimization approaches may work better in some situations or for some models, where ‘better’ means quicker convergence, or perhaps a smoother ride toward convergence. It is not the case that you would come to incorrect conclusions using one method vs. another per se, just that you might reach those conclusions in a more efficient fashion. The following graphic displays SGD versus several variants41. The x and y axes represent the potential values two parameters might take, with the best selection of those values based on a loss function somewhere toward the bottom right. We can see that they all would get there eventually, but some might do so more quickly. This may or may not be the case for some other data situation.
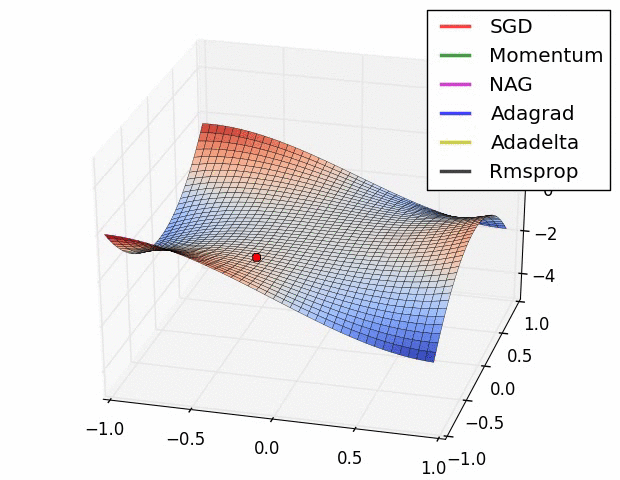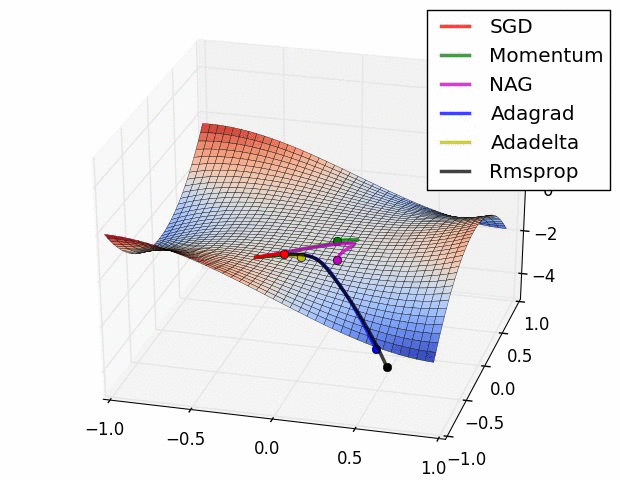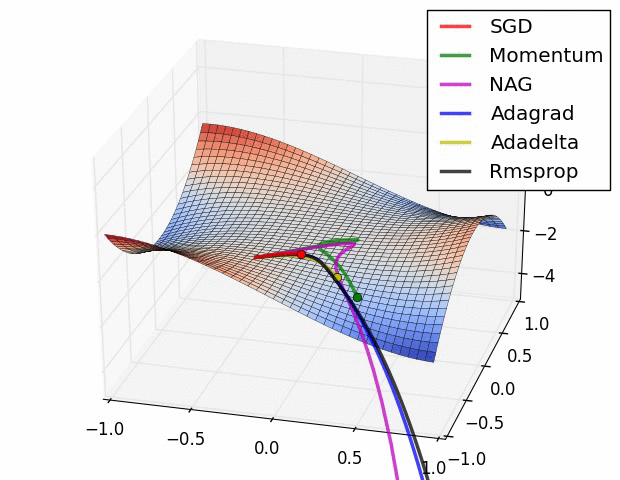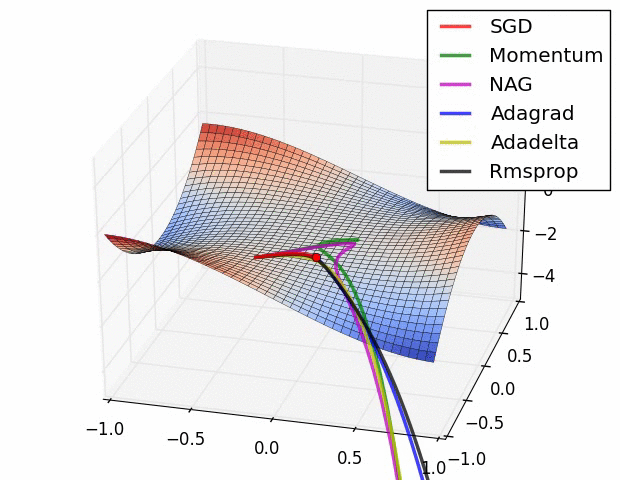
Tuning parameters
In any ML setting there are parameters that need to set in order to even run the model. In regularized regression this may be the penalty parameter, for random forests the tree depth, for neural nets, how many hidden units, and many other things. None of these tuning parameters is known beforehand, and so must be tuned, or learned, just like any other. This is usually done with through validation process like k-fold cross validation. The ‘best’ settings are then used to make final predictions on the test set.
The usual workflow is something like the following:
Tuning: With the training data, use a cross-validation approach to run models with different values for tuning parameters.
Model Selection: Select the ‘best’ model as that which minimizes or maximizes the objective function estimated during cross-validation (e.g. RMSE, accuracy, etc.). The test data in this setting are typically referred to as validation sets.
Prediction: Use the best model to make predictions on the test set.
Techniques
Regularized regression
A starting point for getting into ML from the more inferential methods is to use regularized regression. These are conceptually no different than standard LM/GLM types of approaches, but they add something to the loss function.
\[\mathcal{Loss} = \Sigma(y - \hat{y})^2 + \lambda\cdot\Sigma\beta^2\] In the above, this is the same squared error loss function as before, but we add a penalty that is based on the size of the coefficients. So, while initially our loss goes down with some set of estimates, the penalty based on their size might be such that the estimated loss actually increases. This has the effect of shrinking the estimates toward zero. Well, why would we want that? This introduces bias in the coefficients, but the end result is a model that will do better on test set prediction, which is the goal of the ML approach. The way this works regards the bias-variance tradeoff we discussed previously.
The following demonstrates regularized regression using the glmnet package. It actually uses elastic net, which has a mixture of two penalties, one of which is the squared sum of coefficients (typically called ridge regression) and the other is the sum of their absolute values (the so-called lasso).
library(tidymodels)
happy_prepped = happy %>%
select(-country, -gini_index_world_bank_estimate, -dystopia_residual) %>%
recipe(happiness_score ~ .) %>%
step_scale(everything()) %>%
step_naomit(happiness_score) %>%
prep() %>%
bake(happy)
happy_folds = happy_prepped %>%
drop_na() %>%
vfold_cv()
library(tune)
happy_regLM_spec = linear_reg(penalty = 1e-3, mixture = .5) %>%
set_engine(engine = "glmnet")
happy_regLM_results = fit_resamples(
happy_regLM_spec,
happiness_score ~ .,
happy_folds,
control = control_resamples(save_pred = TRUE)
)
cv_regLM_res = happy_regLM_results %>%
collect_metrics()| .metric | .estimator | mean | n | std_err |
|---|---|---|---|---|
| rmse | standard | 0.335 | 10 | 0.018 |
| rsq | standard | 0.897 | 10 | 0.013 |
Tuning parameters for regularized regression
For the previous model setting, we wouldn’t know what the penalty or the mixing parameter should be. This is where we can use cross validation to choose those. We’ll redo our model spec, create a set of values to search over, and pass that to the tuning function for cross-validation. Our ultimate model will then be applied to the test data.
First we create our training-test split.
# removing some variables with lots of missing values
happy_split = happy %>%
select(-country, -gini_index_world_bank_estimate, -dystopia_residual) %>%
initial_split(prop = 0.75)
happy_train = training(happy_split)
happy_test = testing(happy_split)Next we process the data. This is all specific to the tidymodels approach.
happy_prepped = happy_train %>%
recipe(happiness_score ~ .) %>%
step_knnimpute(everything()) %>% # impute missing values
step_center(everything()) %>% # standardize
step_scale(everything()) %>% # standardize
prep() # prepare for other uses
happy_test_normalized <- bake(happy_prepped, new_data = happy_test, everything())
happy_folds = happy_prepped %>%
bake(happy) %>%
vfold_cv()
# now we are indicating we don't know the value to place
happy_regLM_spec = linear_reg(penalty = tune(), mixture = tune()) %>%
set_engine(engine = "glmnet")Now, we need to create a set of values (grid) to try an test. In this case we set the penalty parameter from near zero to near 1, and the mixture parameter a range of values from 0 (ridge regression) to 1 (lasso).
grid_search = expand_grid(
penalty = exp(seq(-4, -.25, length.out = 10)),
mixture = seq(0, 1, length.out = 10)
)
regLM_tune = tune_grid(
happy_prepped,
model = happy_regLM_spec,
resamples = happy_folds,
grid = grid_search
)
autoplot(regLM_tune, metric = "rmse") + geom_smooth(se = FALSE)
best = show_best(regLM_tune, metric = "rmse", maximize = FALSE, n = 1) # we want to minimize rmse
best# A tibble: 1 x 8
penalty mixture .metric .estimator mean n std_err .config
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0183 0.111 rmse standard 0.288 10 0.00686 Model011The results suggest a more ridge type mixture and smaller penalty tends to work better, and this is more or less in keeping with the ‘best’ model. Here is a plot where size indicates RMSE (smaller better) but only for RMSE < .5 (slight jitter added).
With the ‘best’ model selected, we can refit to the training data with the parameters in hand. We can then do our usual performance assessment with the test set.
# for technical reasons, only mixture is passed to the model; see https://github.com/tidymodels/parsnip/issues/215
tuned_model = linear_reg(penalty = best$penalty, mixture = best$mixture) %>%
set_engine(engine = "glmnet") %>%
fit(happiness_score ~ ., data = juice(happy_prepped))
test_predictions = predict(tuned_model, new_data = happy_test_normalized)
rmse = yardstick::rmse(
data = bind_cols(test_predictions, happy_test_normalized),
truth = happiness_score,
estimate = .pred
)
rsq = yardstick::rsq(
data = bind_cols(test_predictions, happy_test_normalized),
truth = happiness_score,
estimate = .pred
)| .metric | .estimator | .estimate |
|---|---|---|
| rmse | standard | 0.297 |
| rsq | standard | 0.912 |
Not too bad!
Random forests
A limitation of standard linear models, especially with many input variables, is that there’s not a real automatic way to incorporate interactions and nonlinearities. So we often will want to use techniques that do so. To understand random forests and similar techniques (boosted trees, etc.), we can start with a simple decision tree. To begin, for a single input variable (X1) whose range might be 1 to 10, we find that a cut at 5.75 results in the best classification, such that if all observations greater than or equal to 5.75 are classified as positive, and the rest negative. This general approach is fairly straightforward and conceptually easy to grasp, and it is because of this that tree approaches are appealing.
Now let’s add a second input (X2), also on a 1 to 10 range. We now might find that even better classification results if, upon looking at the portion of data regarding those greater than or equal to 5.75, that we only classify positive if they are also less than 3 on the second variable. The following is a hypothetical tree reflecting this.
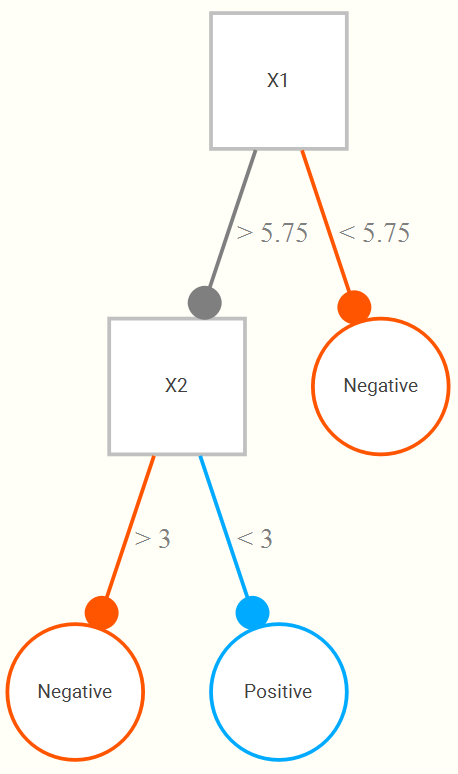
This tree structure allows for both interactions between variables, and nonlinear relationships between some input and the target variable (e.g. the second branch could just be the same X1 but with some cut value greater than 5.75). Random forests randomly select a few from the available input variables, and create a tree that minimizes (maximizes) some loss (objective) function on a validation set. A given tree can potentially be very wide/deep, but instead of just one tree, we now do, say, 1000 trees. A final prediction is made based on the average across all trees.
We demonstrate the random forest using the ranger package. We initially don’t do any tuning here, but do note that the number of variables to randomly select (mtry below), the number of total trees, the tree depth - all of these are potential tuning parameters to investigate in the model building process.
happy_rf_spec = rand_forest(mode = 'regression', mtry = 6) %>%
set_engine(engine = "ranger")
happy_rf_results = fit_resamples(
happy_rf_spec,
happiness_score ~ .,
happy_folds
)
cv_rf_res = happy_rf_results %>%
collect_metrics()| .metric | .estimator | mean | n | std_err |
|---|---|---|---|---|
| rmse | standard | 0.222 | 10 | 0.004 |
| rsq | standard | 0.950 | 10 | 0.003 |
It would appear we’re doing a bit better than the regularized regression.
Tuning parameters for random forests
As mentioned, we’d have a few tuning parameters to play around with. We’ll tune the number of predictors to randomly select per tree, as well as the minimum sample size for each leaf. The following takes the same appraoch as with the regularized regression model. Note that this will take a while (several minutes).
grid_search = expand.grid(
mtry = c(3, 5, ncol(happy_train)-1), # up to total number of predictors
min_n = c(1, 5, 10)
)
happy_rf_spec = rand_forest(mode = 'regression',
mtry = tune(),
min_n = tune()) %>%
set_engine(engine = "ranger")
rf_tune = tune_grid(
happy_prepped,
model = happy_rf_spec,
resamples = happy_folds,
grid = grid_search
)
autoplot(rf_tune, metric = "rmse")
# A tibble: 1 x 8
mtry min_n .metric .estimator mean n std_err .config
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 3 1 rmse standard 0.219 10 0.00422 Model1 Looks like in general using all the variables for selection is the best (this is in keeping with standard approaches for random forest with regression).
Now we are ready to refit the model with the selected tuning parameters and make predictions on the test data.
tuned_model = rand_forest(mode = 'regression', mtry = best$mtry, min_n = best$min_n) %>%
set_engine(engine = "ranger") %>%
fit(happiness_score ~ ., data = juice(happy_prepped))
test_predictions = predict(tuned_model, new_data = happy_test_normalized)
rmse = yardstick::rmse(
data = bind_cols(test_predictions, happy_test_normalized),
truth = happiness_score,
estimate = .pred
)
rsq = yardstick::rsq(
data = bind_cols(test_predictions, happy_test_normalized),
truth = happiness_score,
estimate = .pred
)| .metric | .estimator | .estimate |
|---|---|---|
| rmse | standard | 0.217 |
| rsq | standard | 0.955 |
Neural networks
Neural networks have been around for a long while as a general concept in artificial intelligence and even as a machine learning algorithm, and often work quite well. In some sense, neural networks can simply be thought of as nonlinear regression. Visually however, we can see them as a graphical model with layers of inputs and outputs. Weighted combinations of the inputs are created42 and put through some function (e.g. the sigmoid function) to produce the next layer of inputs. This next layer goes through the same process to produce either another layer, or to predict the output, or even multiple outputs, which serves as the final layer. All the layers between the input and output are usually referred to as hidden layers. If there were a single hidden layer with a single unit and no transformation, then it becomes the standard regression problem.
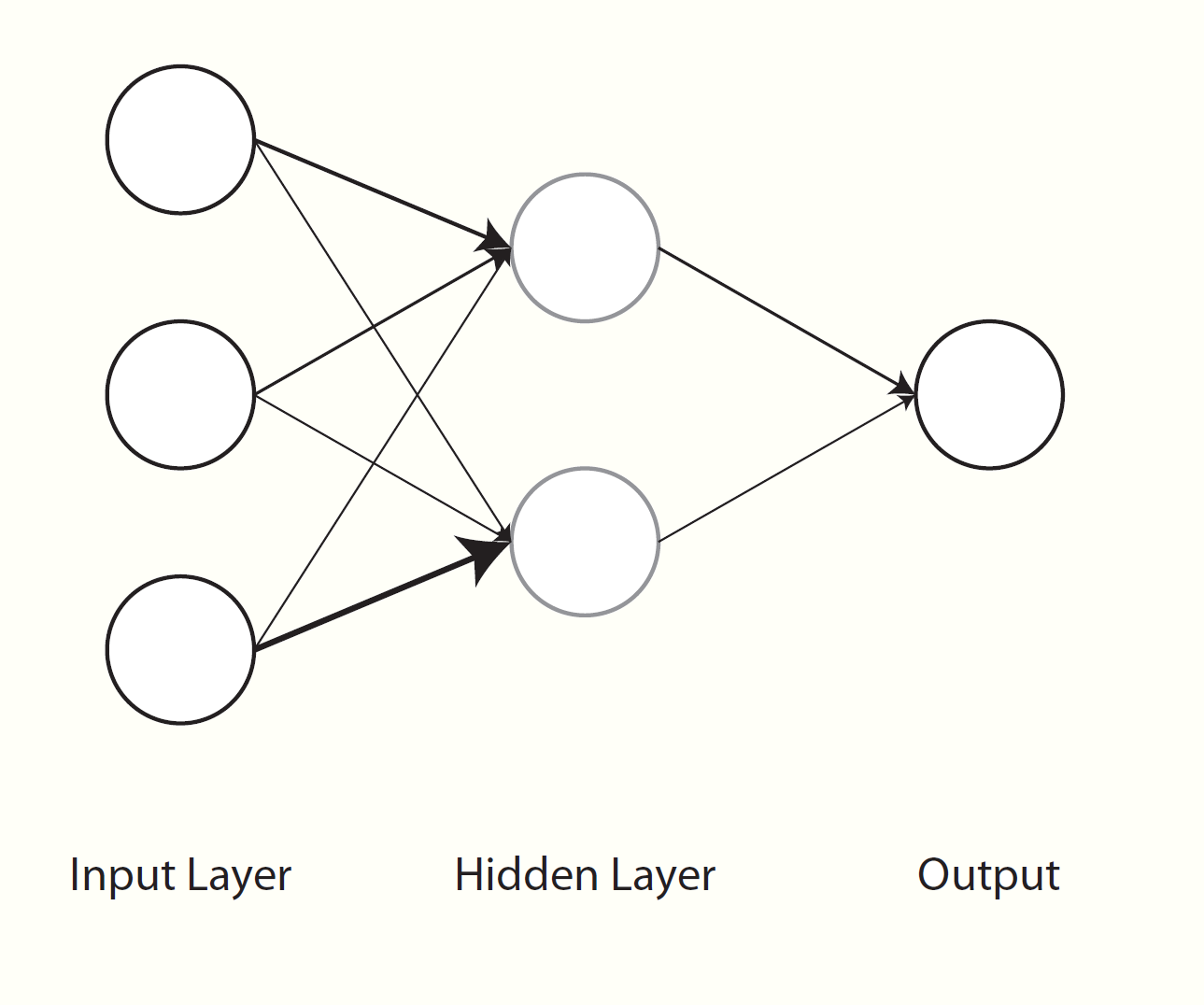
As a simple example, we can run a simple neural network with a single hidden layer of 1000 units43. Since this is a regression problem, no further transformation is required of the end result to map it onto the target variable. I set the number of epochs to 500, which you can think of as the number of iterations from our discussion of optimization. There are many tuning parameters I am not showing that could certainly be fiddled with as well. This is just an example that will run quickly with comparable performance to the previous. If you do not have keras installed, you can change the engine to nnet, which was a part of the base R set of packages well before neural nets became cool again44. This will likely take several minutes for typical machines.
happy_nn_spec = mlp(
mode = 'regression',
hidden_units = 1000,
epochs = 500,
activation = 'linear'
) %>%
set_engine(engine = "keras")
happy_nn_results = fit_resamples(
happy_nn_spec,
happiness_score ~ .,
happy_folds,
control = control_resamples(save_pred = TRUE,
verbose = FALSE,
allow_par = TRUE)
)| .metric | .estimator | mean | n | std_err |
|---|---|---|---|---|
| rmse | standard | 0.818 | 10 | 0.102 |
| rsq | standard | 0.896 | 10 | 0.014 |
You will typically see neural nets applied to image and natural language processing, but as demonstrated above, they can be applied in any scenario. It will take longer to set up and train, but once that’s done, you’re good to go, and may have a much better predictive result.
I leave tuning the model as an exercise, but definitely switch to using nnet if you do so, otherwise you’ll have to install keras (both for R and Python) and be waiting a long time besides. As mentioned, the nnet package is in base R, so you already have it.
Deep learning
Deep learning can be summarized succinctly as ‘very complicated neural nets’. Really, that’s about it. The complexity can be quite tremendous however, and there is a wide variety from which to choose. For example, we just ran a basic neural net above, but for image processing we might use a convolutional neural network, and for natural language processing some LTSM model. Here is a small(!) version of the convolutional neural network known as ‘resnet’ which has many layers in between input and output.
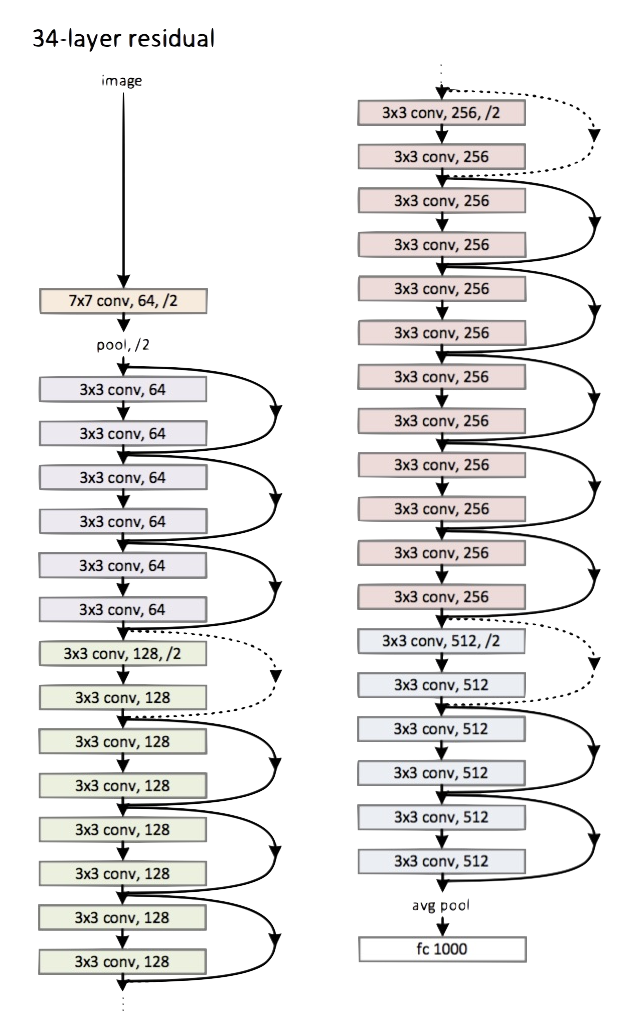
The nice thing is that a lot of the work has already been done for you, and you can use models where most of the layers in the neural net have already been trained by people at Google, Facebook, and others who have much more resources to do do so than you. In such cases, you may only have to worry about the last couple layers for your particular problem. Applying a pre-trained model to a different data scenario is called transfer learning, and regardless of what your intuition is, it will work, and very well.
Artificial intelligence (AI) used to refer to specific applications of deep/machine learning (e.g. areas in computer vision and natural language processing), but thanks to the popular press, the term has pretty much lost all meaning. AI actually has a very old history dating to the cognitive revolution in psychology and the early days of computer science in the late 50s and early 60s. Again though, you can think of it as a subset of the machine learning problems.
Interpreting the Black Box
One of the key issues with ML techniques is interpretability. While a decision tree is immensely interpretable, a thousand of them is not so much. What any particular node or even layer in a complex neural network represents may be difficult to fathom. However, we can still interpret prediction changes based on input changes, which is what we really care about, and really is not necessarily more difficult than our standard inferential setting.
For example, a regularized regression might not have straightforward inference, but the coefficients are interpreted exactly the same as a standard GLM. Random forests can have the interactions visualized, which is what we said was required for interpretation in standard settings. Furthermore, there are many approaches such as Local Interpretable Model-Agnostic Explanations (LIME), variable importance measures, Shapley values, and more to help us in this process. It might take more work, but honestly, in my consulting experience, a great many have trouble interpreting anything beyond a standard linear model any way, and I’m not convinced that it’s fundamentally different problem to extract meaning from the machine learning context these days, though it may take a little work.
Machine Learning Summary
Hopefully this has demystified ML for you somewhat. Nowadays it may take little effort to get to state-of-the-art results from even just a year or two ago, and which, for all intents and purposes, would be good enough both now and for the foreseeable future. Despite what many may think, it is not magic, but for more classically statistically minded, it may require a bit of a different perspective.
Machine Learning Exercises
Exercise 1
Use the ranger package to predict the Google variable rating by several covariates. Feel free to just use the standard function approach rather than all the tidymodels stuff if you want, but do use a training and test approach. You can then try the model again with a different tuning. For the first go around, starter code is provided.
# run these if needed to load data and install the package
# load('data/google_apps.RData')
# install.packages('ranger')
google_for_mod = google_apps %>%
select(avg_sentiment_polarity, rating, type,installs, reviews, size_in_MB, category) %>%
drop_na()
google_split = google_for_mod %>%
initial_split(prop = 0.75)
google_train = training(google_split)
google_test = testing(google_split)
ga_rf_results = rand_forest(mode = 'regression', mtry = 2, trees = 1000) %>%
set_engine(engine = "ranger") %>%
fit(
rating ~ ?,
google_train
)
test_predictions = predict(ga_rf_results, new_data = google_test)
rmse = yardstick::rmse(
data = bind_cols(test_predictions, google_test),
truth = rating,
estimate = .pred
)
rsq = yardstick::rsq(
data = bind_cols(test_predictions, google_test),
truth = rating,
estimate = .pred
)
bind_rows(
rmse,
rsq
)Exercise 2
Respecify the neural net model demonstrated above as follows, and tune over the number of hidden units to have. This will probably take several minutes depending on your machine.
grid_search = expand.grid(
hidden_units = c(25, 50),
penalty = exp(seq(-4, -.25, length.out = 5))
)
happy_nn_spec = mlp(mode = 'regression',
penalty = tune(),
hidden_units = tune()) %>%
set_engine(engine = "nnet")
nn_tune = tune_grid(
happy_prepped, # from previous examples, see tuning for regularized regression
model = happy_nn_spec,
resamples = happy_folds, # from previous examples, see tuning for regularized regression
grid = grid_search
)
show_best(nn_tune, metric = "rmse", maximize = FALSE, n = 1) Python Machine Learning Notebook
The ‘machine’ part of the term has historical context, but otherwise has lost meaning for most modern applications, or, at least I really don’t think we need to be referring to computers doing their usual thing as something notable. ‘Learning’ is a poor term that seems to lead many to believe ML is some ‘algorithm’ automatically/magically learning from data without any human input. Nothing could be further from the truth. ML models ‘learn’ from the data as much as a linear regression does.↩︎
This image comes from Elements of Statistical Learning.↩︎
Unfortunately, unlike the tidyverse, tidymodels doesn’t really help me do things more easily. As an alternative, consider the mlr3 approach, which has its own ‘verse’ of packages. I’m not suggesting it’s easier, and it uses R6 which will take getting used to, but it’s a viable alternative if you want to try an different framework for machine learning.↩︎
This is Alec Radford’s visualization.↩︎
In at least conceptually, and most of the time, literally, in the exact same manner as happens with linear regression.↩︎
For some reason the parsnip package calls this function mlp, which means ‘multilayer’ perceptron, even though only one hidden layer is possible. Something was clearly lost in translation.↩︎
Brian Ripley, one of the early R developers, wrote a seminal text on neural networks in the mid 90s. However, google scholar seems to have forgotten it despite its thousands of citations, I guess because they think it’s written by this guy.↩︎