Thinking Visually
Information
A starting point for data visualization regards the information you want to display, and then how you want to display it in order to tell the data’s story. As in statistical modeling, parsimony is the goal, but not at the cost of the more compelling story. We don’t want to waste the time of the audience or be redundant, but we also want to avoid unnecessary clutter, chart junk, and the like.
We’ll start with a couple examples. Consider the following.

So what’s wrong with this? Plenty. Aside from being boring, the entire story can be said with a couple words- males are taller than females (even in the Star Wars universe). There is no reason to have a visualization. And if a simple group difference is the most exciting thing you have to talk about, not many are going to be interested.
Minor issues can also be noted, including unnecessary border around the bars, unnecessary vertical gridlines, and an unnecessary X axis label.
You might think the following is an improvement, but I would say it’s even worse.

Now the y axis has been changed to distort the difference, perceptually suggesting a height increase of over 34%. Furthermore, color is used but the colors are chosen poorly, and add no information, thus making the legend superfluous. And finally, the above doesn’t even convey the information people think it does, assuming they are even standard error bars, which one typically has to guess about in many journal visualizations of this kind50.
Now we add more information, but more problems!

The above has unnecessary border, gridlines, and emphasis. The labels, while possibly interesting, do not relate anything useful to the graph, and many are illegible. It imposes a straight (and too wide of a) straight line on a nonlinear relationship. And finally, color choice is both terrible and tends to draw one’s eye to the female data points. Here is what it looks like to someone with the most common form of colorblindness. If the points were less clumpy on sex, it would be very difficult to distinguish the groups.
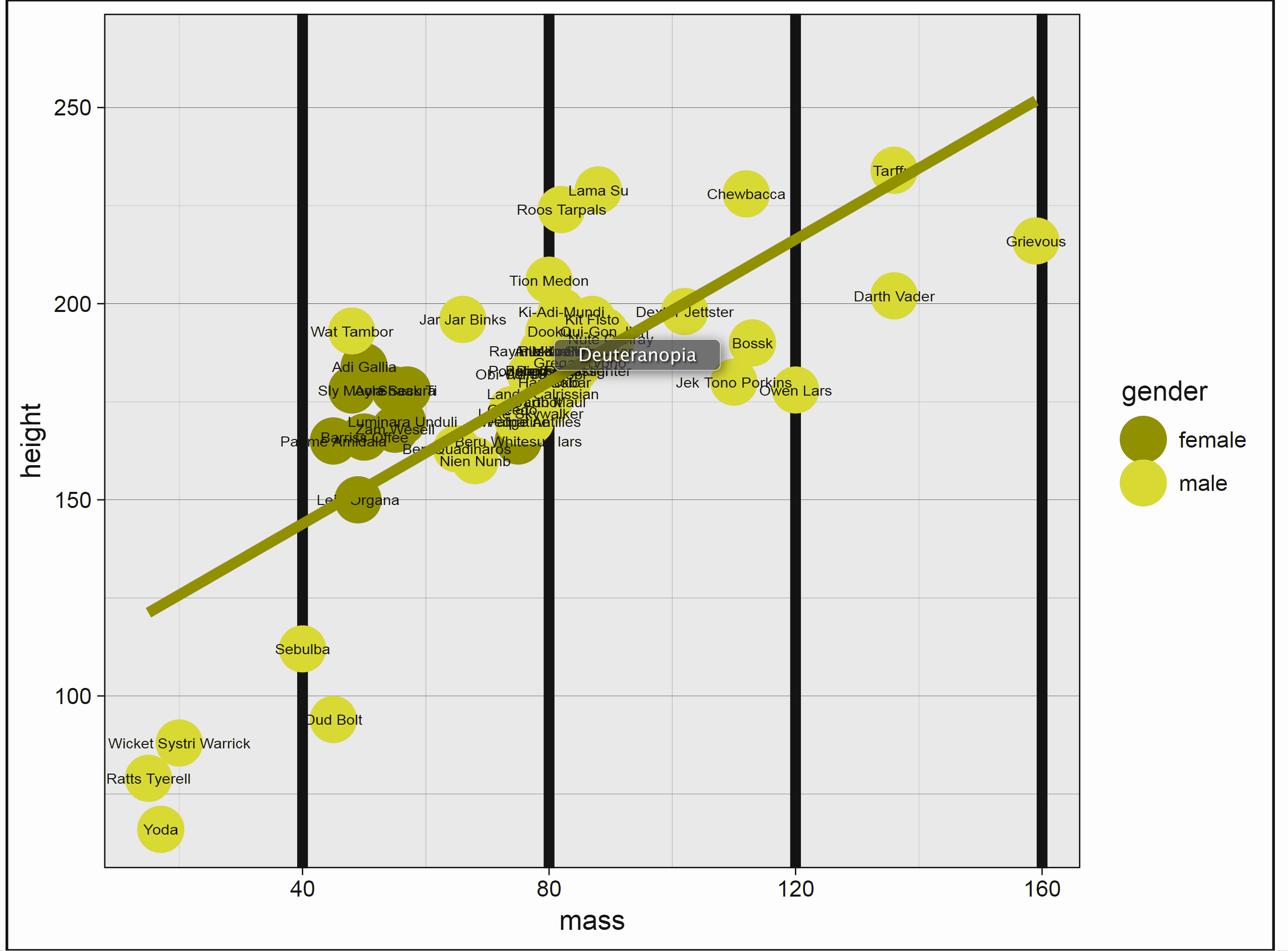
And here is what it might look like when printed.

Now consider the following. We have six pieces of information in one graph- name (on hover), homeworld (shape), age (size), sex (color), mass (x), and height (y). The colors are evenly spaced from one another, and so do not draw one’s attention to one group over another, or even to the line over groups. Opacity allows the line to be added and the points to overlap without loss of information. We technically don’t need a caption, legend or gridlines, because hovering over the data tells us everything we’d want to know about a given data point. The interactivity additionally allows one to select and zoom on specific areas.
Whether this particular scheme is something you’d prefer or not, the point is that we get quite a bit of information without being overwhelming, and the data is allowed to express itself cleanly.
Here are some things to keep in mind when creating visualizations for scientific communication.
Your audience isn’t dumb
Assume your audience, which in academia is full of people with advanced degrees or those aspiring to obtain one, and in other contexts comprises people who are interested in your story, can handle more than a bar graph. If the visualization is good and well-explained51, they’ll be fine.
See the data visualization and maps sections of 2019: The Year in Visual Stories and Graphics at the New York Times. Good data visualization of even complex relationships can be appreciated by more than an academic audience. Assume you can at least provide visualizations on that level of complexity and be okay. It won’t always work, but at least put the same effort you’d appreciate yourself.
Clarity is key
Sometimes the clearest message is a complicated one. That’s okay, science is an inherently fuzzy process. Make sure your visualization tells the story you think is important, and don’t dumb the story down in the visualization. People will remember the graphic before they’ll remember a table of numbers.
By the same token, don’t needlessly complicate something that is straightforward. Perhaps a scatter plot with some groupwise coloring is enough. That’s fine.
All of this is easier said than done, and there is no right way to do data visualizations. Prepare to experiment, and focus on visuals that display patterns that will be more readily perceived.
Avoid clutter
In striving for clarity, there are pitfalls to avoid. Gridlines, 3d, unnecessary patterning, and chartjunk in general will only detract from the message. As an example, gridlines might even seem necessary, but even faint ones can potentially hinder the pattern recognition you hope will take place, perceptually imposing clumps of data that do not exist. In addition, they practically insist on a level of data precision that in many situations you simply don’t have. What’s more, with interactivity they literally convey nothing additional, as a simple hover-over or click on a data point will reveal the precise values. Use sparingly, if at all.
Color isn’t optional
It’s odd for me to have to say this, as it’s been the case for many years, but no modern scientific outlet should be a print-first outfit, and if they are, you shouldn’t care to send your work there. The only thing you should be concerned with is how it will look online, because that’s how people will interact with your work first and foremost. That means that color is essentially a requirement for any visualization, so use it well in yours. Appropriate color choice will still look fine in black and white anyway.
Think interactively
It might be best to start by making the visualization you want to make, with interactivity and anything else you like. You can then reduce as necessary for publication or other outlets, and keep the fancy one as supplemental, or accessible on your own website to show off.
Color
There is a lot to consider regarding color. Until recently, the default color schemes of most visualization packages were poor at best. Thankfully, ggplot2, its imitators and extenders, in both the R world and beyond, have made it much easier to have a decent color scheme by default52.
However, the defaults are still potentially problematic, so you should be prepared to go with something else. In other cases, you may just simply prefer something else. For example, for me, the gray background of ggplot2 defaults is something I have to remove for every plot53.
Viridis
A couple packages will help you get started in choosing a decent color scheme. One is viridis. As stated in the package description:
These color maps are designed in such a way that they will analytically be perfectly perceptually-uniform, both in regular form and also when converted to black-and-white. They are also designed to be perceived by readers with the most common form of color blindness.
So basically you have something that will take care of your audience without having to do much. There are four primary palettes, plus one version of the main viridis color scheme that will be perceived by those with any type of color blindness (cividis).

These color schemes might seem a bit odd from what you’re used to. But recall that the goal is good communication, and these will allow you to convey information accurately, without implicit bias, and be acceptable in different formats. In addition, there is ggplot2 functionality to boot, e.g. scale_color_viridis, and it will work for discrete or continuously valued data.
For more, see the vignette. I also invite you to watch the introduction of the original module in Python, where you can learn more about the issues in color selection, and why viridis works.
You can use the following functions for with ggplot2:
- scale_color_viridis_c
- scale_color_viridis_d
- scale_fill_viridis_c
- scale_fill_viridis_d
Scientific colors
Yet another set of palettes are available via the scico package, and are specifically geared toward for scientific presentation. These perceptually-uniform color maps sequential, divierging, and circular pallets, will handle data variations equally all along the colour bar, and still work for black and white print. They provide more palettes to go with viridis.
- Perceptually uniform
- Perceptually ordered
- Color-vision-deficiency friendly
- Readable as black-and-white print
You can use the following functions for with ggplot2:
- scale_color_scico
- scale_color_scico_d
- scale_fill_scico
- scale_fill_scico_d

I personally prefer these for the choices available, and viridis doesn’t seem to work aesthetically that well in a lot of contexts. More information on their development can be found here.
RColorBrewer
Color Brewer offers a collection of palettes that will generally work well in a variety of situations, but especially for discrete data. While there are print and color-blind friendly palettes, not all adhere to those restrictions. Specifically though, you have palettes for the following data situations:
- Qualitative (e.g. Dark254)
- Sequential (e.g. Reds)
- Diverging (e.g. RdBu)

There is a ggplot2 function, scale_color_brewer, you can use as well. For more, see colorbrewer.org. There you can play around with the palettes to help make your decision.
You can use the following functions for with ggplot2:
- scale_color_brewer
- scale_fill_brewer/span>
In R, you have several schemes that work well right out of the box:
- ggplot2 default palette
- viridis
- scico
- RColorBrewer
Furthermore, they’ll work well with discrete or continuous data. You will have to do some work to come up with better, so they should be your default. Sometimes though, one can’t help oneself.
Contrast
Thankfully, websites have mostly gotten past the phase where there text looks like this. The goal of scientific communication is to, well, communicate. Making text hard to read is pretty much antithetical to this.
So contrast comes into play with text as well as color. In general, you should consider a 7 to 1 contrast ratio for text, minimally 4 to 1.
-Here is text at 2 to 1
-Here is text at 4 to 1
-Here is text at 7 to 1 (this document)
-Here is black
I personally don’t like stark black, and find it visually irritating, but obviously that would be fine to use for most people.
Contrast concerns regard color as well. When considering color, one should also think about the background for plots, or perhaps the surrounding text. The following function will check for this. Ideally one would pass AAA status, but AA is sufficient for the vast majority of cases.

# default ggplot2 discrete color (left) against the default ggplot2 gray background
visibly::color_contrast_checker(foreground = '#F8766D', background = 'gray92') ratio AA AALarge AAA AAALarge
1 2.25 fail fail fail fail# the dark viridis (right) would be better
visibly::color_contrast_checker(foreground = '#440154', background = 'gray92') ratio AA AALarge AAA AAALarge
1 12.7 pass pass pass passYou can’t win all battles however. It will be difficult to choose colors that are perceptually even, avoid color-blindness issues, have good contrast, work to convey the information you need, and are aesthetically pleasing. The main thing to do is simply make the attempt.
Scaling Size
You might not be aware, but there is more than one way to scale the size of objects, e.g. in a scatterplot. Consider the following, where in both cases dots are scaled by the person’s body-mass index (BMI).

What’s the difference? The first plot scales the dots by their area, while the second scales the radius, but otherwise they are identical. It’s not generally recommended to scale the radius, as our perceptual system is more attuned to the area. Packages like ggplot2 and plotly will automatically do this, but some might not, so you should check.
Transparency
Using transparency is a great way to keep detailed information available to the audience without being overwhelming. Consider the following. Fifty individual trajectories are shown on the left, but it doesn’t cause any issue graphically. The right has 10 lines plus a fitted line, 20 points and a ribbon to provide a sense of variance. Using transparency and a scientific color scheme allows it to be perceived cleanly.
![]()
Without transparency, it just looks ugly, and notably busier if nothing else. This plot is using the exact same scico palette.
![]()
In addition, transparency can be used to add additional information to a plot. In the following scatter plot, we can get a better sense of data density from the fact that the plot is darker where points overlap more.
![]()
Here we apply transparency to a density plot to convey a group difference in distributions, while still being able to visualize the whole distribution of each group.
![]()
Had we not done so, we might not be able to tell what’s going on with some of the groups at all.
![]()
In general, a good use of transparency can potentially help any visualization, but consider it especially when trying to display many points, or otherwise have overlapping data.
Accessibility
Among many things (apparently) rarely considered in typical academic or other visualization is accessibility. The following definition comes from the World Wide Web Consortium.
Web accessibility means that people with disabilities can use the Web. More specifically, Web accessibility means that people with disabilities can perceive, understand, navigate, and interact with the Web, and that they can contribute to the Web. Web accessibility also benefits others, including older people with changing abilities due to aging.
The main message to get is that not everyone is able to use the web in the same manner. While you won’t be able to satisfy everyone who might come across your work, putting a little thought into your offering can go along way, and potentially widen your audience.
We talked about this previously, but when communicating visually, one can do simple things like choosing a colorblind-friendly palette, or using a font contrast that will make it easier on the eyes of those reading your work. There are even browser plugins to test your web content for accessibility. In addition, there are little things like adding a title to inserted images, making links more noticeable etc., all of which can help consumers of your information.
File Types
It’s one thing to create a visualization, but at some point you’re likely going to want to share it. RStudio will allow for the export of any visualization created in the Plots or Viewer tab. In addition, various packages may have their own save function, that may allow you to specify size, type or other aspects. Here we’ll discuss some of the options.
- png: These are relatively small in size and ubiquitous on the web. You should feel fine in this format. It does not scale however, so if you make a smaller image and someone zooms, it will become blurry.
- gif: These are the type used for all the silly animations you see on the web. Using them is fine if you want to make an animation, but know that it can go longer than a couple seconds, and there is no requirement for it to be asinine.
- jpg: Commonly used for photographs, which isn’t the case with data generated graphs. Given their relative size I don’t see much need for these.
- svg: These take a different approach to imaging and can scale. You can make a very small one and it (potentially) can still look great when zoomed in to a much larger size. Often useful for logos, but possibly in any situation.
As I don’t know what screen will see my visualizations, I generally opt for svg. It may be a bit slower/larger, but in my usage and for my audience size, this is of little concern relative to it looking proper. They also work for pdf if you’re still creating those, and there are also lighter weight versions in R, e.g. svglite. Beyond that I use png, and have no need for others.
Here is a discussion on stackexchange that summarizes some of the above. The initial question is old but there have been recent updates to the responses.
Note also, you can import files directly into your documents with R, markdown, HTML tags, or \(\LaTeX\). See ?png for a starting point. The following demonstrates an image insert for HTML output, with a couple options for centering and size.
<img src="file.jpg" style="display:block; margin: 0 auto;" width=50%>

This uses markdown to get the same result
{width=50%}
Summary of Thinking Visually
The goal of this section was mostly just to help you realize that there are many things to consider when visualizing information and attempting to communicate the contents of data. The approach is not the same as what one would do in say, an artistic venture, or where there is nothing specific to impart to an audience. Even some of the most common things you see published are fundamentally problematic, so you can’t even use what people traditionally do as a guide. However, there are many tools available to help you. Another thing to keep in mind is that there is no right way to do a particular visualization, and many ways, to have fun with it.
A casual list of things to avoid
I’m just putting things that come to mind here as I return to this document. Mostly it is personal opinion, though often based on various sources in the data visualization realm or simply my own experience.
Pie
Pie charts and their cousins, e.g. bar charts (and stacked versions), wind rose plots, radar plots etc., either convey too little information, or make otherwise simple information more difficult to process perceptually. The basic pie chart is really only able to convey proportional data. Beyond that, anything done with a pie chart can almost always be done better, at the very least with a bar chart, but you should really consider better ways to convey your data.
Alternatives:
- bar
- densities/stacked densities
- parallel sets/sankey
Histograms
Anyone that’s used R’s hist function knows the frustration here. Use density plots instead. They convey the same information but better, and typical defaults are usually fine. However, you should really consider the information and audience- is a histogram or density plot really displaying what you want to show?
Alternatives:
- density
- quantile dotplot

Using 3D without adding any communicative value
You will often come across use of 3D in scientific communication which is fairly poor and makes the data harder to interpret. In general, when going beyond two dimensions, your first thought should be to use color, size, etc. and finally, prefer interactivity to 3D. Where it is useful is in things like showing structure (e.g. molecular, geographical), or continuous multi-way interactions.
Alternatives:
- multiple 2d/faceting
Using too many colors
Some put a completely non-scientifically based number on this, but the idea holds. For example, if you’re trying to show U.S. state grouping by using a different color for all 50 states, no one’s going to be able to tell the yellow for Alabama vs. the slightly different yellow for Idaho. Alternatives would be to show the information via a map or use a hover over display.
Using valenced colors when data isn’t applicable
Often we have data that can be thought of as having a positive/negative or valenced nuance. For example, we might want to show values relative to some cut point, or they might naturally have positive and negative values (e.g. sentiment, standardized scores). Oftentimes though, doing so would mean possibly arbitrarily picking a cut point and unnaturally discretizing the data.
The following shows a plot of water risk for many countries. The first plots the color along a continuum with increasing darkness as one goes along, which is appropriate for this score of positive numeric values from 0-5. We can clearly see problematic ones while still getting a sense of where other countries lie along that score. The other plot arbitrarily codes a different color scheme, which might suggest some countries are fundamentally different than others. However, if the goal is to show values relative to the median, then it accurately conveys countries above and below that value. If the median is not a useful value (e.g. to take some action upon), then the former plot would likely be preferred.

Showing maps that just display population
Many of the maps I see on the web cover a wide range of data and can be very visually appealing, but pretty much just tell me where the most populated areas are, because the value conveyed is highly correlated with it. Such maps are not very interesting, so make sure that your geographical depiction is more informative than this.
Biplots
A lot of folks doing PCA resort to biplots for interpretation, where a graphical model would be much more straightforward. See this chapter for example.
Thinking Visually Exercises
Exercise 1
The following uses the diamonds data set that comes with ggplot2. Use the scale_color_viridis or scale_color_scico function to add a more accessible palette. Use ? to examine your options.
# devtools::install_github("thomasp85/scico") # to use scientific colors
library(ggplot2)
ggplot(aes(x = carat, y = price), data = diamonds) +
geom_point(aes(color = price)) +
????
Exercise 2
Now color it by the cut instead of price. Use scale_color_viridis/scioc_d. See the helpfile via ?scale_color_* to see how to change the palette.

Thinking exercises
For your upcoming presentation, who is your audience?
Error bars for group means can overlap and still be statistically different (the test regards the difference in means). Furthermore visuals of this sort often don’t bother to say whether it is standard deviation, standard error, or 2*standard error, or even something else.↩︎
People seem to think there are text limits for captions. There are none.↩︎
Even Matlab finally joined the club, except that they still screwed up with their default coloring scheme.↩︎
Hadley states “The grey background gives the plot a similar colour (in a typographical sense) to the remainder of the text, ensuring that the graphics fit in with the flow of a text without jumping out with a bright white background. Finally, the grey background creates a continuous field of colour which ensures that the plot is perceived as a single visual entity.”. The part about it being ugly is apparently left out. ☺ Also, my opinion is that it has the opposite effect, making the visualization jump out because nothing on the web is typically gray by default. If anything the page background is white, and having a white/transparent background would perhaps be better, but honestly, don’t you want a visualization to jump out?↩︎
Don’t even think about asking what the Dark1 palette is.↩︎